Java实现单向链表(基础功能实现)
Java实现单向链表(基础功能实现)
- 1 实现目标
- 2 功能分析
- 2.1 添加新节点
- 2.2 插入新节点
- 2.3 删除链表中节点
- 2.4 链表遍历
- 3 详细设计说明
- 3.1 Node类的详细设计说明
- 3.2 Link类的详细设计
- 3.2.1 Link成员变量
- 3.2.2 Link类方法
- 3.3 代码实现
- 4 链表的测试用例
- 5 总结
1 实现目标
从数据结构的角度来说,链表中包含一个或多个节点的数据容器,这些个节点通过串联形成一个完整的、可遍历的线性结构,在文本中,我们依托此结构制作一个单向链表。单向链表必须记录链表的头部元素,可以遍历链表中的所有节点。一个基本的链表结构必须提供元素的添加、删除、修改、查找以及遍历功能。
为了方便链表的使用,还应该提供链表信息获取等扩展方法,这些方法包含并不限于链表长度的获取、头元素获取、尾部元素获取、是否包含指定元素等,这些功能是一个链表应该具备的基础功能。
此外,为了能够让链表可以存储多种类型数据,应该将链表设计成泛型类。为了避免出现不符合Java约束的情况出现,我们也应该对容器内元素个数进行约束,比如给链表制定最大长度约束。
2 功能分析
一个链表结构中包含了若干节点,每一个节点都应包含一个存储单元,多个节点首尾相连组成一个线性数据结构,这就是链表要实现的基本结构。由于我们的设计目标是单项链表结构,链表的节点由两部分组成:一个部分为数据区,用于存放数据元素(简称数据区);另一个部分为链接指针域,用于保存下一个存储单元的地址(简称指针域),尾部的链表指针域应为null,不保存任何节点地址的引用,它标识整条链表的结束。链表中包含的存储单元个数用于表示链表的长度。 链表的整体结构如下图所示,其中e表示数据区,next为指针域。
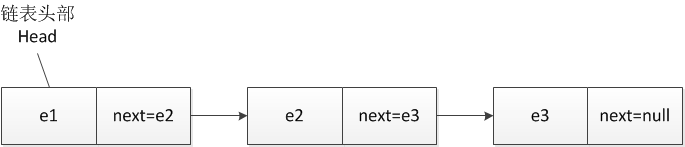
对于链表来说,记住链表的头部节点是非常重要的,只要我们记住了链表的头部节点,我们就可以获取链表上的所有元素。这也是链表遍历时重要的节点。
从容器角度来说,容器提供的主要功是数据的增、删、改、查操作,其中修改和查询操作都是在遍历链表的基础上完成的。链表上的增加和删除操作会影响链表的结构,这两个操作在进行时,我们务必要保证链表节点的之间的链接性和有效性。
2.1 添加新节点
在一般情况下,正常添加的链表应该在当前链表的尾部添加节点。添加节点的过程中,新节点的指针域应为null,原有的尾部节点指针域应该保存新节点地址,这样就保证了整条链表的链接是连贯的,新添加的节点是有效的。添加节点的过程如下图所示。

在实现添加新节点的规程中,我们要从链表的头部遍历到链表的尾部,然后在尾部添加新节点。在实现的过程中,为了可以省略链表的遍历过程,我们需要记录链表的尾部节点。
2.2 插入新节点
在指定的节点之后添加新节点,需要获取指定节点以及前后节点的信息。然后重新对节点的指针域进行处理,其结构改变如下图所示。
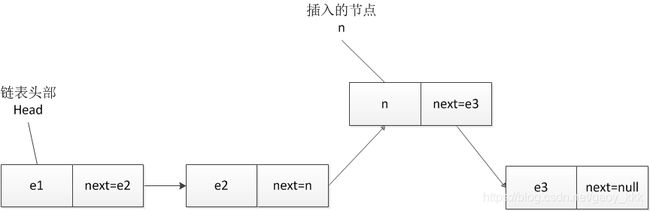
如果在节点为e2和e3之间添加新节点n,n节点添加前后关系变化如下:
- 添加节点前的关系为:e2.next=e3。
- 添加节点后的关系应为e2.next=n和n.next=e3。
2.3 删除链表中节点
删除节点时,需要给出要删除节点的位置,然后将该节点删除,并同时修改被删除节点前一个节点的指针域信息,如下图所示。

如被删除节点为e3,e3的前节点为e2,e3的后节点为e4,在删除的过程中,它们的关系有如下变化:
- 删除前e2.next=e3,e3.next=e4
- 删除后e2.next=e4
当被删除的节点是链表的两端时,还要及时的更新链表的头尾节点信息。
2.4 链表遍历
我们设计的链表如果要进行遍历,可以通过节点的指针域进行遍历。遍历的过程从头部节点开始,通过指针域获取下一个节点,以此类推直到遇到指针域为null的节点为止,代表一次遍历的完成。
3 详细设计说明
实现功能的链表以及相关功能由两个类组成:
- 泛型类Link,命名为Link < T >。该类是链表功能的主类,用于提供链表操作的所有功能。
- 泛型类Node,命名为Node< T >。表示链表中的节点,该类包含数据元素信息以及指针域信息。由于该节点为Link所独,可以设计成Link的内部类。
每当链表中增加一个元素时,对应增加一个Node对象,Node对象包含了元素信息(泛型变量)以及另一个节点引用对象(即链表指针域,实现多个节点的链接功能)。
3.1 Node类的详细设计说明
Node类是为链表的节点信息,与主类Link的泛型信息应保持一致。由于该类主要用于链表节点对象声明,建议创建成为Link的内部类。其声明名称应为"static class Node"。为了方便Node的使用,可以为Node增加一个构造方法用于直接初始化节点中的元素信息和指针域信息。Node类的成员变量和一个构造方法声明如下:
- T item:变量item用于存储链表节点中的数据(数据区)。
- Node< T > next:变量next用于存储下一个链表节点对象(指针域)。
public Node(T item,Node< T > next):构造方法,用于初始化Node的成员变量。
3.2 Link类的详细设计
Link类是实现功能的主要类,Link的声明应为"public class Link< T >",链表的基本功能在Link类中进行实现。
3.2.1 Link成员变量
- private int size:用于表示链表的长度,初始值为0。当链表添加和删除节点时,应该修改size的值,size值与链表的实际长度吻合。
- private final int MAX_SIZE:用于表示链表的最大长度。该值应为合理的整型常量,链表的长度应小于该值,初始值我们可以根据需求自行定义(不要超过int的最大值)。
- private Node< T > head:表示链表的头结点,当删除头结点时,头结点的下一个节点变为头结点,初始值为null。
- private Node< T > last:表示链表的尾结点。当删除尾结点时,尾结点的上一个节点变为尾结点,初始值为null。
3.2.2 Link类方法
1.public boolean add(T e)
- 方法描述:(重载方法)向链表中添加新元素e。返回值为true表明添加成功,失败为false。
- 实现过程:1.先判断size>=MAX_SIZE条件是否成立,如果成立说明超出链表长度,方法返回false。2.创建新节点node,其次再判断链表中是否是空链表,如果是空链表,更新头结点和尾节点信息为node。如果不是空链表,在尾节点后添加node节点,并更新尾节点信息。size自增一个单位,方法返回true。
2.public boolean add(int index,T e)
- 方法描述:(重载方法)在指定的节点index序列前插入新的元素e。返回值为true表明添加成功,失败为false。注意,该方法无法添加在尾节点之后,但可以添加在头节点之前。
- 实现过程:1.判断指定索引index是否在链表范围内,并且判断是否会超出链表最大长度,如果不满足条件,方法返回false。2.索引在指定范围内时,创建新节点newNode,先判断目标是否是头节点(即索引为0),如果是头节点,将创建新节点指向头节点,并更新头结点信息。3.如果不是头结点,找到索引处的节点node和索引处前一个节点preNode,再创建新节点信息,并将新节点插入在preNode和node之间,更新节点之间的关系。4.节点添加成功,size自增一个单位,并返回true。
3.public boolean contains(Object e)
- 方法描述:查询链表中是否有当前对象,对象是否相等取决于equlas方法也是我们判断链表中是否含有目标元素e的重要判断条件。返回值为true表明有该对象,没有找到则为false。
- 实现过程:1.遍历链表,判断遍历的元素是否与目标对象e相等,如果被遍历的节点元素与目标节点相等,方法返回true。2.如果遍历完成后,依然没有找到与目标相等的对象,方法返回false。
4.public T get(int index)
- 方法描述:返回指定序列index处的节点元素信息。如果序列不存在,方法返回null。
- 实现过程:1.当序列索引index不再链表范围内,返回null。2.如果索引在正常范围内,移动到index所在的节点node处,并返回node.item。
5.public T getHead():返回链表的头节点元素,如果头结点为null,返回null。
6.public T getLast():返回链表的尾节点元素,如果尾结点为null,返回null。
7.public boolean remove(int index)
- 方法描述:删除指定索引index处的节点。返回值为true表明删除成功,失败为false。
- 实现过程:1.当index不再链表序列中,方法返回false。2.索引指向头节点时,头节点后移,并将原头结点删除。3.获取要被删除的节点node和前一节点preNode,如果node是尾节点,更新尾节点为preNode,并删除node节点信息。如果不是尾节点,preNode指向下一个节点,并删除node节点信息。4.删除节点成功,size自减一个单位,并返回true。
8.public int size():返回链表的size变量值。
3.3 代码实现
- public class Link<T>{
-
- private int size=0;//链表长度
- private Node<T> head=null;//链表的头节点
- private Node<T> last=null;//链表的头节点
-
- //链表最大长度,链表长度size最大值为MAX_SIZE,是在链表中添加元素时必须判断的条件。
- private final int MAX_SIZE=2<<10;
-
- //链表中的节点类
- static class Node<T> {
- //链表中的节点元素
- T item;
- //下一个节点的地址
- Node<T> next;
-
- Node(T item,Node<T> next){
- this.item=item;
- this.next=next;
- }
- }
-
- public boolean add(T obj){
-
- if(size>=MAX_SIZE) return false;
- Node<T> newNode=new Node<T>(obj, null);
- if(size==0) {
- //如果为头节点,首末节点等于新增节点
- head=newNode;
- last=newNode;
- }else {
- //将节点添加至尾部
- last.next=newNode;
- //尾节点为新节点
- last=newNode;
- }
-
- size++;
- return true;
- }
-
- public boolean add(int index,T obj) {
-
- if(index>=size || index<0 || size>MAX_SIZE-1) return false;
- Node<T> newNode=new Node<T>(obj, null);
- //如果是头结点
- if(index==0) {
- newNode.next=head;
- head=newNode;
- size++;
- return true;
- }
-
- Node<T> node=head;//index索引处节点
- Node<T> preNode=null;//index索引之前的节点
- //遍历节点,node为指定序列index的链表节点,preNode为前一个节点
- for(int i=0;i<index;i++) {
- preNode=node;
- node=node.next;
- }
- //更新节点间的关系
- preNode.next=newNode;
- newNode.next=node;
-
- size++;
- return true;
- }
-
-
- public boolean contains(Object obj) {
-
- Node<T> start=head;
- while(start!=null) {
- //当节点对象与obj的equals相等时,则找到对象
- if(start.item.equals(obj)) return true;
- //节点后移
- start=start.next;
- }
-
- return false;
- }
-
-
- public T get(int index) {
-
- if(index<0 || index>=size) return null;
- //从头部节点遍历到指定索引节点
- Node<T> node=head;
- for(int i=0;i<index;i++) {
- node=head.next;
- }
-
- return node.item;
- }
-
- public T getHead() {
- return head==null?null:head.item;
- }
-
- public T getLast() {
- return last==null?null:last.item;
- }
-
- public boolean remove(int index) {
-
- if(index>=size || index<0) return false;
-
- Node<T> removeNode=head;//被删除节点,初始值为头结点
- Node<T> preNode=null;//被删除节点的上一个节点
- //如果是头节点,将头节点后移。
- if(index==0) {
- this.head=head.next;
- removeNode=null;
- size--;
- return true;
- }
- //移动到指定索引节点处。
- for(int i=0;i<index;i++) {
- preNode=removeNode;
- removeNode=removeNode.next;
- }
- //如果被删除节点是尾节点
- if(removeNode.next==null) {
- last=preNode;
- preNode.next=null;
- removeNode=null;
- }else {
- preNode.next=removeNode.next;
- removeNode=null;
- }
- size--;
- return true;
- }
-
- public int size() {
- return this.size;
- }
-
- public String toString() {
- StringBuilder strs=new StringBuilder();
- Node<T> start=head;
- while(start!=null) {
- strs.append(start.item).append(",");
- start=start.next;
- }
-
- return strs.toString();
- }
- }
在实际的编写中,为了在使用过程中便于观察链表中的数据,我们重写了toString方法(toString方法将链表中的所有数据都逗号分隔,组成一个长字符串)。
4 链表的测试用例
在程序设计阶段,测试用例的作用是为了验证我们编写的功能是正确有效的,能够处理极端参数。对于我们自定义的链表来说,其主要目的是为了测试链表功能的有效性,在操作链表的时候(添加、删除操作),链表中各节点之间是连贯、有效的。在测试用例中,我们需要经常的对链表的头结点、尾节点、链表长度、以及链表中元素内容进行输出,所以我们将信息封装成了方法showLink,源码如下所示:
showLink方法:
01. public static void showLink(Link<?> link) {
02. System.out.println("head="+link.getHead()
03. +",last="+link.getLast()
04. +",size="+link.size());
05. System.out.println("link="+link);
06. }
1.add(E e):方法测试用例:向一个新的空链表中,添加元素。并观察添加前后链表的变量信息。
01. public static void addTest1() {
02. Link<Integer> link=new Link<>();
03. showLink(link);
04. for(int i=0;i<10;i++) {
05. boolean result=link.add(i);
06. if(!result) {
07. System.out.println("添加元素"+i+"失败!");
08. }
09. }
10. showLink(link);
11. }
测试用例运行结果:
head=null,last=null,size=0
link=
head=0,last=9,size=10
link=0,1,2,3,4,5,6,7,8,9,
2.add(E e):方法测试用例:测试添加元素超过链表最大值时,add方法的返回结果。
01. public static void addTest2() {
02. Link<Integer> link=new Link<>();
03. System.out.println(link.size());
04. for(int i=0;i<(2<<10)-1;i++) {
05. boolean result=link.add(i);
06. if(!result) {
07. System.out.println("添加元素"+i+"失败!");
08. }
09. }
10. System.out.println("尾元素:"+link.getLast());
11. System.out.println("添加元素-2:"+link.add(-2));
12. System.out.println("添加元素-1:"+link.add(-1));
13. System.out.println("尾元素:"+link.getLast());
14. System.out.println(link.size());
15. }
测试用例运行结果:
0
尾元素:2046
添加元素-2:true
添加元素-1:false
尾元素:-2
2048
3.add(int index,E e):测试用例:在三种情况下进行测试。1.在有数据的链表中,在头节点处添加元素。2.在有数据的链表中,在任意索引范围内添加数据。3.在非索引范围内添加元素。
01. public static void addTest3() {
02. Link<Integer> link=new Link<>();
03. for(int i=0;i<10;i++) {
04. link.add(i);
05. }
06. showLink(link);
07. System.out.println("在0索引处添加元素100:"+link.add(0,100));
08. showLink(link);
09. System.out.println("在5索引处添加元素500:"+link.add(5,500));
10. showLink(link);
11. System.out.println("在100索引处添加元素1000:"+link.add(100,10000));
12. showLink(link);
13. }
测试用例运行结果:
head=0,last=9,size=10
link=0,1,2,3,4,5,6,7,8,9,
在0索引处添加元素100:true
head=100,last=9,size=11
link=100,0,1,2,3,4,5,6,7,8,9,
在5索引处添加元素500:true
head=100,last=9,size=12
link=100,0,1,2,3,500,4,5,6,7,8,9,
在100索引处添加元素1000:false
head=100,last=9,size=12
link=100,0,1,2,3,500,4,5,6,7,8,9,
4.contains(Object o):测试用例:在三种情况进行查找测试。1.在新链表中查找数据。2.在有数据链表中,查询一个链表中包含的元素。3.在有数据链表中,查询链表中不包含的元素。
01. public static void containsTest() {
02. Link<Integer> link=new Link<>();
03. System.out.println("新链表中查询元素1:"+link.contains(1));
04. for(int i=0;i<10;i++) {
05. link.add(i);
06. }
07. System.out.println("在有数据链表中查询元素1:"+link.contains(1));
08. System.out.println("在有数据链表中查询元素10:"+link.contains(10));
09. }
测试用例运行结果:
新链表中查询元素1:false
在有数据链表中查询元素1:true
在有数据链表中查询元素10:false
5.get(int index):测试用例:在两种情况下进行测试。1.当指定索引在范围内获取元素。2.当指定索引不在范围内获取元素。
01. public static void getTest() {
02. Link<Integer> link=new Link<>();
03. for(int i=0;i<10;i++) {
04. link.add(i);
05. }
06. System.out.println("查找索引3的元素:"+link.get(3));
07. System.out.println("查找索引10的元素:"+link.get(10));
08. }
测试用例运行结果:
查找索引3的元素:1
查找索引10的元素:null
6.getHead、getLast和size方法,这三个方法在showLink方法中被调用,并且在其它测试方法中多次被调用,并且表现正常,我们不再对这三个方法进行单独测试。
7.remove(int index):测试用例:在四种情况下进行测试。1.在新的链表中删除元素。2.在有数据链表中,删除头节点元素。3.在有数据链表中,删除尾节点元素。4.在有数据链表中,删除非头、尾节点元素。
01. public static void removeTest() {
02. Link<Integer> link=new Link<>();
03. System.out.println("新链表,删除索引1的元素"+link.remove(1));
04. for(int i=0;i<10;i++) {
05. link.add(i);
06. }
07. System.out.println("有数据链表,删除头元素"+link.remove(0));
08. showLink(link);
09. System.out.println("有数据链表,删除尾元素"+link.remove(link.size()-1));
10. showLink(link);
11. System.out.println("有数据链表,删除索引1元素"+link.remove(1));
12. showLink(link);
13. }
测试用例运行结果:
新链表,删除索引1的元素false
有数据链表,删除头元素true
head=1,last=9,size=9
link=1,2,3,4,5,6,7,8,9,
有数据链表,删除尾元素true
head=1,last=8,size=8
link=1,2,3,4,5,6,7,8,
有数据链表,删除索引1元素true
head=1,last=8,size=7
link=1,3,4,5,6,7,8,
以上是我们为了测试链表是否成功而准备的基本测试用例,我们也可以创建更多的测试环境,进一步验证我们的程序实现是否正确。
5 总结
我们本文所设计的链表,是一个最基本的链表功能实现,虽然在一些实现的细节上还不严谨,但还是比较适合链表设计的基础练习,只要能够实现基本的链表功能就完成了我们的目的,我们可以以此为基础进行功能和设计上的加强。
从使用功能上来说,链表属于Java的集合体系范围——Collection,如果我们要将链表设计的符合集合体系,就要实现该接口,在下一篇文章中,我们会继续进行单项链表的实现,并对本文中的链表进行升级,让它可以达到一个能符合Java集合体系的链表集合。
单向链表(基础功能实现 )