写在前面
不知不觉的,写Node.js已经一年了。不同于最开始的demo、本地工具等,这一年里,都是用Node.js写的线上业务。从一开始的Node.js同构直出,到最近的Node接入层,也算是对Node开发入门了吧。目前,我一个人维护了大部分组内流传下来的Node服务,包括内部系统和线上服务。新增的后台服务,也是尽可能地使用Node进行开发。本文是一下自己最近的一些小小的总结和思考。
本文不会深入讲解Node.js本身的特性,架构等等。我也没有写过Node扩展或者库什么的,对Node.js的了解也并不够深入。
为何用Node
对于我来说,对于团队来说,适用Node的原因其实很简单:开发起来快。熟悉JS的前端同学可以很快上手,节省成本。选一个http server库起一个server,选择合适的中间件,匹配好请求路由,看情况合理使用ORM库链接数据库、增删改查即可。
Node的适用场景
Node.js 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量又高效。这种模型使得Node.js 可以避免了由于需要等待输入或者输出(数据库、文件系统、Web服务器...)响应而造成的 CPU 时间损失。所以,Node.js适合运用在高并发、I/O密集、少量业务逻辑的场景。
对应到平时具体的业务上,如果是内部的系统,大部分仅仅就是需要对某个数据库进行增删改查,那么Server端直接就是Node.js一把梭。
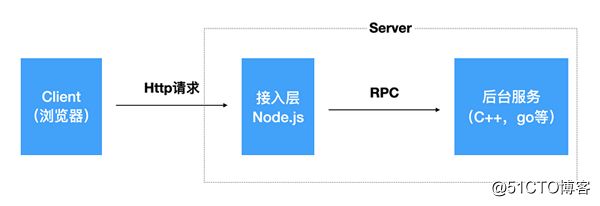
对于线上业务,如果流量不大,并且业务逻辑简单的情况下,Server端也可以完全使用Node.js。对于流量巨大,复杂度高的项目,一般用Node.js作为接入层,后台同学负责实现服务。如下图:
同样是写JS,Node.js开发和页面开发有什么区别
在浏览器端开发页面,是和用户打交道、重交互,浏览器还提供了各种Web Api供我们使用。Node.js主要面向数据,收到请求后,返回具体的数据。这是两者在业务路径上的区别。而真正的区别其实是在于业务模型上(业务模型,这是我自己瞎想的一个词)。直接用图表示吧。
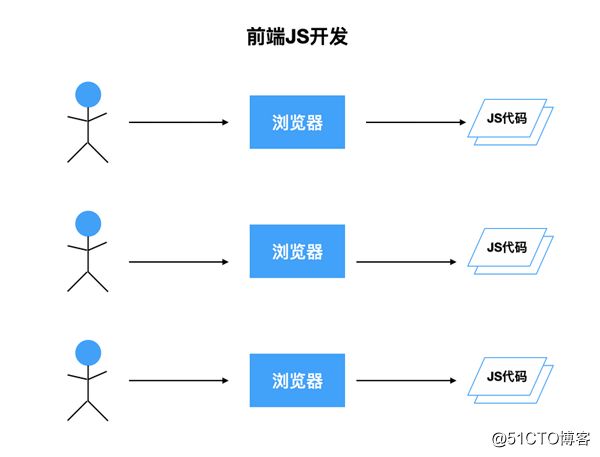
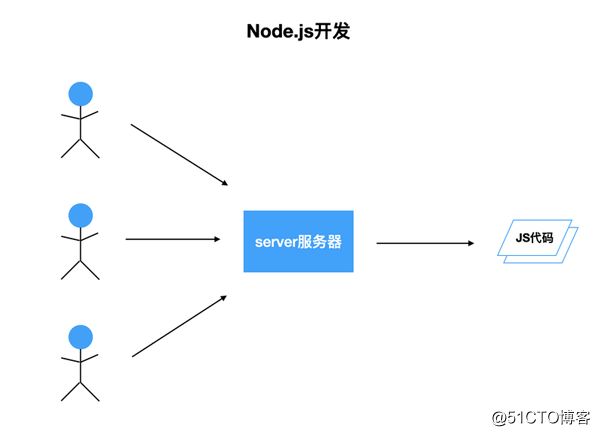
开发页面时,每一个用户的浏览器上都有一份JS代码。如果代码在某种情况下崩了,只会对当前用户产生影响,并不会影响其他用户,用户刷新一下即可恢复。而在Node.js中,在不开启多进程的情况下,所有用户的请求,都会走进同一份JS代码,并且只有一个线程在执行这份JS代码。如果某个用户的请求,导致发生错误,Node.js进程挂掉,server端直接就挂了。尽管可能有进程守护,挂掉的进程会被重启,但是在用户请求量大的情况下,错误会被频繁触发,可能就会出现server端不停挂掉,不停重启的情况,对用户体验造成影响。
以上,可能是Node.js开发和前端JS开发最大的区别。
Node.js开发时的注意事项
用户在访问Node.js服务时,如果某一个请求卡住了,服务迟迟不能返回结果,或者说逻辑出错,导致服务挂掉,都会带来大规模的体验问题。server端的目标,就是要 快速、可靠 地返回数据。
-
缓存
由于Node.js不擅长处理复杂逻辑(JavaScript本身执行效率较低),如果要用Node.js做接入层,应该避免复杂的逻辑。想要快速处理数据并返回,一个至关重要的点:使用缓存。
例如,使用Node做React同构直出,renderToString这个Api,可以说是比较重的逻辑了。如果页面的复杂度高,每次请求都完整执行renderToString,会长时间占用线程来执行代码,增加响应时间,降低服务的吞吐量。这个时候,缓存就十分重要了。
实现缓存的主要方式:内存缓存。可以使用Map,WeakMap,WeakRef等实现。参考以下简单的示例代码:
const cache = new Map();
router.get('/getContent', async (req, res) => {
const id = req.query.id;
// 命中缓存
if(cache.get(id)) {
return res.send(cache.get(id));
}
// 请求数据
const rsp = await rpc.get(id);
// 经过一顿复杂的操作,处理数据
const content = process(rsp);
// 设置缓存
cache.set(id, content);
return res.send(content);
}); 使用缓存时,有一个很重要的问题是:内存缓存如何更新。一种最简单的方法,开一个定时器,定期删除缓存,下一次请求到来时,重新设置缓存即可。在上述代码中,增加如下代码:
setTimeout(function() {
cache.clear();
}, 1000 * 60); // 1分钟删除一次缓存 如果server端完全使用Node实现,需要用Node端直接连接数据库,在数据时效性要求不太高、且流量不太大的情况下,就可以使用上述类似的模型,如下图。这样可以降低数据库的压力且加快Node的响应速度。
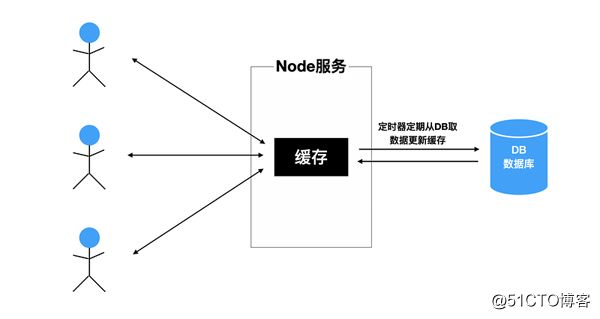
另外,还需要注意内存缓存的大小。如果一直往缓存里写入新数据,那么内存会越来越大,最终爆掉。可以考虑使用LRU(Least Recently Used)算法来做缓存。开辟一块内存专门作为缓存区域。当缓存大小达到上限时,淘汰最久未使用的缓存。
内存缓存会随着进程的重启而全部失效。
当后台业务比较复杂,接入层流量,数据量较大时,可以使用如下的架构,使用独立的内存缓存服务。Node接入层直接从缓存服务取数据,后台服务直接更新缓存服务。
当然,上图中的架构是最简单的情形,现实中还需要考虑分布式缓存、缓存一致性的问题。这又是另外一个话题了。
- 错误处理
由于Node.js语言的特性,Node服务是比较容易出错的。而一旦出错,造成的影响就是服务不可用。因此,对于错误的处理十分的重要。
处理错误,最常用的就是try catch 了。可是 try catch无法捕获异步错误。Node.js中,异步操作是十分常见的,异步操作主要是在回调函数中暴露错误。看一个例子:
const readFile = function(path) {
return new Promise((resolve,reject) => {
fs.readFile(path, (err, data) => {
if(err) {
throw err; // catch无法捕获错误,这和Node的eventloop有关。
// reject(err); // catch可以捕获
}
resolve(data);
});
});
}
router.get('/xxx', async function(req, res) {
try {
const res = await readFile('xxx');
...
} catch (e){
// 捕获错误处理
...
res.send(500);
}
});
上面的代码中,readFile 中 throw 出来的错误,是无法被catch捕获的。如果我们把 throw err 换成 Promise.reject(err),catch中是可以捕获到错误的。
我们可以把异步操作都Promise化,然后统一使用 async 、try、catch 来处理错误。
但是,总会有地方会被遗漏。这个时候,可以使用process来捕获全局错误,防止进程直接退出,导致后面的请求挂掉。示例代码:
process.on('uncaughtException', (err) => {
console.error(`${err.message}\n${err.stack}`);
});
process.on('unhandledRejection', (reason, p) => {
console.error(`Unhandled Rejection at: Promise ${p} reason: `, reason);
}); 关于Node.js中错误的捕获,还可以使用domain模块。现在这个模块已经不推荐使用了,我也没有在项目中实践过,这里就不展开了。Node.js 近几年推出的 async_hooks 模块,也还处于实验阶段,不太建议线上环境直接使用。做好进程守护,开启多进程,错误告警及时修复,养成良好的编码规范,使用合适的框架,才能提高Node服务的效率及稳定性。
写在后面
本文总结了Node.js开发一年多以来的实践总结等。Node.js的开发与前端网页的开发思路不同,着重点不一样。我正式开发Node.js的时间也不算太长,一些点并没有深入的理解,本文仅仅是一些经验之谈。
【责任编辑:庞桂玉 TEL:(010)68476606】