NLP面试题总结.02
这一章节提出了33个问题,不是很难,可以当做休闲读一下:
目录
1.下列哪些技术能被用于关键词归一化(keyword normalization),即把关键词转化为其基本形式?
2. 下列哪些技术能被用于计算两个词向量之间的距离?
3. 文本语料库的可能特征是什么?
4.你在20K文档的输入数据上为机器学习模型创建了文档-词矩阵(document-term matrix)。以下哪项可用于减少数据维度?
5.哪些文本分析技术可被用于名词短语检测、动词短语检测、主语检测和宾语检测?
6.用余弦相似度表示的词之间的差异将显著高于0.5
7.下列哪项是关键词归一化技术?
8.在包含N个文档的语料库中,随机选择的一个文档总共包含个词条,词条“hello”出现 K 次。如果词条“hello”出现在全部文档的数量接近三分之一,则TF(词频)和 IDF(逆文档频率)的乘积的正确值是多少?
9.下列算法中减少了常用词的权重,增加了文档集合中不常用词的权重的是?
10.下列算法中减少了常用词的权重,增加了文档集合中不常用词的权重的是?
11. 将句子或段落转换为tokens的过程称为词干提取(Stemming)
12. 在给到任何神经网络之前,Tokens都会被转换成数字
13. 找出其中的异类
14.TF-IDF帮你建立
15. 从给定的句子、段落中识别人名、组织名的过程称为?
16. 下列哪一项不是预处理技术?
17. 在文本挖掘中,可以使用以下哪项命令完成将文本转换为tokens,然后将其转换为整数或浮点向量的操作?
18.将词表示成向量被称为神经词嵌入(Neural Word Embeddings)?
19. 下列哪种词嵌入支持上下文建模(Context Modeling)?
20. 下列哪种嵌入方式支持双向上下文(Bidirectional Context)?
21. 下列哪种词嵌入可以自定义训练特定主题?
22. 词嵌入捕获多维数据,并表示为向量?
23. 词嵌入向量有助于确定2个tokens之间的距离?
24. 以下哪项是解决NLP用例(如语义相似性、阅读理解和常识推理)的更好选择?
25. Transformer架构首先是由下列哪项引入的?
26. 相同的词可以通过_____来实现多个词嵌入?
27. 对于一个给定的token,其输入表示为它的token嵌入、段嵌入(Segment Embedding)、位置嵌入(Position Embedding)的总和
28. 从左到右和从右到左训练两个独立的LSTM语言模型,并将它们简单地连接起来
29. 用于产生词嵌入的单向语言模型
30. 在这种架构中,对句子中所有词之间的关系进行建模,而与它们的位置无关。这是哪种架构?
31. Transformer模型关注句子中最重要的词
32. 排列语言模型(Permutation Language Models)是下列哪项的特点?
33. Transformer XL使用相对位置嵌入
1.下列哪些技术能被用于关键词归一化(keyword normalization),即把关键词转化为其基本形式?
A. 词形还原(Lemmatization)
B. 探测法(Soundex)
C. 余弦相似度(Cosine Similarity)
D. N-grams
答案:A ;词形还原有助于得到一个词的基本形式,例如:playing -> play, eating -> eat等;其他选项的技术都有其他使用目的。
2. 下列哪些技术能被用于计算两个词向量之间的距离?
A. 词形还原(Lemmatization)
B. 欧式距离(Euclidean Distance)
C. 预先相似度(Cosine Similarity)
D. N-grams
答案:B和C;两个词向量之间的距离可以用预先相似度和欧式距离来计算。余弦相似度在两个词之间的向量之间建立一个余弦角,两个词之间的余弦角接近表词相似,反之亦然。两点之间的欧式距离是连接这两点的最短路径的长度。
3. 文本语料库的可能特征是什么?
A. 文本中词计数
B. 词的向量标注
C. 词性标注(Part of Speech Tag)
D. 基本依存语法
E. 以上所有
答案:E
以上所有这些都可以作为文本语料库的特征。
4.你在20K文档的输入数据上为机器学习模型创建了文档-词矩阵(document-term matrix)。以下哪项可用于减少数据维度?
(1)关键词归一化(Keyword Normalization)
(2)潜在语义索引(Latent Semantic Indexing)
(3)隐狄利克雷分布(Latent Dirichlet Allocation)
A. 只有(1)
B. (2)、(3)
C. (1)、(3)
D. (1)、(2)、(3)
答案:D
5.哪些文本分析技术可被用于名词短语检测、动词短语检测、主语检测和宾语检测?
A. 词性标注(Part of Speech Tagging)
B. Skip Gram 和N-Gram 提取
C. 连续性词袋(Bag of Words)
D. 依存句法分析(Dependency Parsing)和成分句法分析(Constituency Parsing)
答案:D
6.用余弦相似度表示的词之间的差异将显著高于0.5
A. 正确
B. 错误
答案:A
7.下列哪项是关键词归一化技术?
A. 词干提取(Stemming)
B. 词性标注(Part of Speech)
C. 命名实体识别(Named Entity Recognition)
D. 词形还原(Lemmatization)
答案:A与 D
词性标注(POS)与命名实体识别(NER)不是关键词归一化技术。
8.在包含N个文档的语料库中,随机选择的一个文档总共包含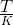 个词条,词条“hello”出现 K 次。如果词条“hello”出现在全部文档的数量接近三分之一,则TF(词频)和 IDF(逆文档频率)的乘积的正确值是多少?
个词条,词条“hello”出现 K 次。如果词条“hello”出现在全部文档的数量接近三分之一,则TF(词频)和 IDF(逆文档频率)的乘积的正确值是多少?
A. KT * Log(3)
B. T * Log(3) / K
C. K * Log(3) / T
D. Log(3) / KT
答案:C ;词频的计算:![]() ,逆文档频率:
,逆文档频率: ![]() ,最后两者相乘就是答案C。
,最后两者相乘就是答案C。
9.下列算法中减少了常用词的权重,增加了文档集合中不常用词的权重的是?
A. 词频(TF)
B. 逆文档频率(IDF)
C. Word2Vec
D. 隐狄利克雷分布(Latent Dirichlet Allocation)
答案:B
10.下列算法中减少了常用词的权重,增加了文档集合中不常用词的权重的是?
A. 词频(TF)
B. 逆文档频率(IDF)
C. Word2Vec
D. 隐狄利克雷分布(Latent Dirichlet Allocation)
答案:B
11. 将句子或段落转换为tokens的过程称为词干提取(Stemming)
A. 正确
B. 错误
答案:B 这是分词(tokenization),而不是词干提取。
12. 在给到任何神经网络之前,Tokens都会被转换成数字
A. 正确
B. 错误
答案:A ,在自然语言处理中,所有的词在输入到神经网络之前都被转换成数字。
13. 找出其中的异类
A. nltk
B. scikit learn
C. SpaCy
D. BERT
答案:D ,除了BERT是一个词嵌入方法以外,其它都是NLP库。
14.TF-IDF帮你建立
A. 文档中出现频率最高的词
B. 文档中最重要的词
答案:BTF-IDF有助于确定特定词在文档语料库中的重要性。TF-IDF考虑了该词在文档中出现的次数,并被出现在语料库中的文档数所抵消。
15. 从给定的句子、段落中识别人名、组织名的过程称为?
A. 词干提取(Stemming)
B. 词形还原(Lemmatization)
C. 停用词消除(Stop Word Removal)
D. 命名实体识别(Named Entity Recognition)
答案:D
16. 下列哪一项不是预处理技术?
A. 词干提取和词形还原(Stemming and Lemmatization)
B. 转换成小写(Converting to Lowercase)
C. 删除标点符号(Remove Punctuation)
D. 删除停用词(Removal of Stop Words)
E. 情绪分析(Sentiment Analysis)
答案:E情绪分析不是一种预处理技术。它是在预处理之后完成的,是一个NLP用例。所有其他列出的都用作语句预处理的一部分。
17. 在文本挖掘中,可以使用以下哪项命令完成将文本转换为tokens,然后将其转换为整数或浮点向量的操作?
A. CountVectorizer
B. TF-IDF
C. 词袋模型(Bag of Words)
D. NERs
答案:ACountVectorizer可帮助完成上述操作,而其他方法则不适用。
18.将词表示成向量被称为神经词嵌入(Neural Word Embeddings)?
A. 正确
B. 错误
答案:A
19. 下列哪种词嵌入支持上下文建模(Context Modeling)?
A. Word2Vec
B. GloVe
C. BERT
D. 以上所有
答案:C ,只有BERT(Bidirectional Encoder Representations from Transformer)支持上下文建模。
20. 下列哪种嵌入方式支持双向上下文(Bidirectional Context)?
A. Word2Vec
B.BERT
C. GloVe
D. 以上所有
答案:B ,只有BERT支持双向上下文。Word2Vec和GloVe是词嵌入,它们不提供任何上下文。
21. 下列哪种词嵌入可以自定义训练特定主题?
A. Word2Vec
B. BERT
C. GloVe
D. 以上所有
答案:B
22. 词嵌入捕获多维数据,并表示为向量?
A. 正确
B. 错误
答案:A
23. 词嵌入向量有助于确定2个tokens之间的距离?
A. 正确
B. 错误
答案:A ,可以使用余弦相似度来确定通过词嵌入来表示的两个向量之间的距离。
24. 以下哪项是解决NLP用例(如语义相似性、阅读理解和常识推理)的更好选择?
A. ELMo
B. Open AI’s GPT
C. ULMFit
答案:B ,Open AI的GPT能够通过使用Transformer模型的注意力机制(Attention Mechanism)来学习数据中的复杂模式,因此更适合于诸如语义相似性、阅读理解和常识推理之类的复杂用例。
25. Transformer架构首先是由下列哪项引入的?
A. GloVe
B. BERT
C. Open AI’s GPT
D. ULMFit
答案:C ,ULMFit拥有基于LSTM的语言建模架构;这之后被Open AI的GPT的Transformer架构所取代。
26. 相同的词可以通过_____来实现多个词嵌入?
A. GloVe
B. Word2Vec
C. ELMo
D. Nltk
答案:C ,ELMo(Embeddings from Language Models)词嵌入支持同一个词的多个嵌入,这有助于在不同的上下文中使用同一个词,从而捕获上下文而不仅仅是词的意思,这与GloVe、Word2Vec不同。Nltk不是词嵌入。
27. 对于一个给定的token,其输入表示为它的token嵌入、段嵌入(Segment Embedding)、位置嵌入(Position Embedding)的总和
A. ELMo
B. GPT
C. BERT
D. ULMFit
答案:C ,BERT使用token嵌入、段嵌入(Segment Embedding)、位置嵌入(Position Embedding)。
28. 从左到右和从右到左训练两个独立的LSTM语言模型,并将它们简单地连接起来
A. GPT
B. BERT
C. ULMFit
D. ELMo
答案:D ,ELMo尝试训练两个独立的LSTM语言模型(从左到右和从右到左),并将结果连接起来以产生词嵌入。
29. 用于产生词嵌入的单向语言模型
A. BERT
B. GPT
C. ELMo
D. Word2Vec
答案:B
30. 在这种架构中,对句子中所有词之间的关系进行建模,而与它们的位置无关。这是哪种架构?
A. OpenAI GPT
B. ELMo
C. BERT
D. ULMFit
答案:C ,BERT Transformer架构将句子中每个词和所有其他词之间的关系建模,以生成注意力分数。这些注意力分数随后被用作所有词表示的加权平均值的权重,它们被输入到完全连接的网络中以生成新的表示。
31. Transformer模型关注句子中最重要的词
A. 正确
B. 错误
答案:ATransformer模型中的注意机制用于建模所有词之间的关系,并为最重要的词提供权重。
32. 排列语言模型(Permutation Language Models)是下列哪项的特点?
A. BERT
B. EMMo
C. GPT
D. XLNET
答案:D ,XLNET提供了基于排列的语言模型,这是与BERT的一个关键区别。
33. Transformer XL使用相对位置嵌入
A. 正确
B. 错误
答案:A ,Transformer XL使用嵌入来编码词之间的相对距离,而不是必须表示词的绝对位置。这个嵌入用于计算任意两个词之间的注意力得分,这两个词之间可以在之前或之后被n个词分隔开。