pandas数据处理实践五(透视表pivot_table、分组和透视表实战Grouper和pivot_table)
建议大家多研究pandas的官方文档
透视表:
DataFrame.pivot_table(values = None,index = None,columns = None,aggfunc ='mean',fill_value = None,margin = False,dropna = True,margins_name ='All' )
创建一个电子表格样式的数据透视表作为DataFrame。数据透视表中的级别将存储在结果DataFrame的索引和列上的MultiIndex对象
| 参数: | values : 要聚合的列,可选 index:列,Grouper,数组或前一个列表
columns:列,Grouper,数组或前一个列表
aggfunc:function,function of list,dict,default numpy.mean
fill_value:标量,默认无
margin:boolean,默认为False
dropna:布尔值,默认为True
margins_name:string,默认为'All'
|
|---|---|
| 返回: | table : DataFrame |
In [7]: df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",^M
...: "bar", "bar", "bar", "bar"],^M
...: "B": ["one", "one", "one", "two", "two",^M
...: "one", "one", "two", "two"],^M
...: "C": ["small", "large", "large", "small",^M
...: "small", "large", "small", "small",^M
...: "large"],^M
...: "D": [1, 2, 2, 3, 3, 4, 5, 6, 7]})
...:
In [8]: df
Out[8]:
A B C D
0 foo one small 1
1 foo one large 2
2 foo one large 2
3 foo two small 3
4 foo two small 3
5 bar one large 4
6 bar one small 5
7 bar two small 6
8 bar two large 7
In [9]: table = pd.pivot_table(df, values='D', index=['A','B'], columns=['C'], aggfunc=np.sum)
# 通过透视表,以A,B为索引对象,以c作为列,把D作为值填充
In [10]: table
Out[10]:
C large small
A B
bar one 4.0 5.0
two 7.0 6.0
foo one 4.0 1.0
two NaN 6.0再举一个例子:
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df = pd.read_excel('sales-funnel.xlsx')
df.head() # 查看前五行数据
Account Name Rep Manager Product Quantity Price Status
0 714466 Trantow-Barrows Craig Booker Debra Henley CPU 1 30000 presented
1 714466 Trantow-Barrows Craig Booker Debra Henley Software 1 10000 presented
2 714466 Trantow-Barrows Craig Booker Debra Henley Maintenance 2 5000 pending
3 737550 Fritsch, Russel and Anderson Craig Booker Debra Henley CPU 1 35000 declined
4 146832 Kiehn-Spinka Daniel Hilton Debra Henley CPU 2 65000 won
# 生成透视表
# 从数据的显示来看,我们对顾客 购买的总价钱感兴趣,如何转换表格呢?
pd.pivot_table(df,index=['Name'],aggfunc='sum')
Account Price Quantity
Name
Barton LLC 740150 35000 1
Fritsch, Russel and Anderson 737550 35000 1
Herman LLC 141962 65000 2
Jerde-Hilpert 412290 5000 2
Kassulke, Ondricka and Metz 307599 7000 3
Keeling LLC 688981 100000 5
Kiehn-Spinka 146832 65000 2
Koepp Ltd 1459666 70000 4
Kulas Inc 437790 50000 3
Purdy-Kunde 163416 30000 1
Stokes LLC 478688 15000 2
Trantow-Barrows 2143398 45000 4
pd.pivot_table(df,index=['Name','Rep','Manager'])
Account Price Quantity
Name Rep Manager
Barton LLC John Smith Debra Henley 740150.0 35000.0 1.000000
Fritsch, Russel and Anderson Craig Booker Debra Henley 737550.0 35000.0 1.000000
Herman LLC Cedric Moss Fred Anderson 141962.0 65000.0 2.000000
Jerde-Hilpert John Smith Debra Henley 412290.0 5000.0 2.000000
Kassulke, Ondricka and Metz Wendy Yule Fred Anderson 307599.0 7000.0 3.000000
Keeling LLC Wendy Yule Fred Anderson 688981.0 100000.0 5.000000
Kiehn-Spinka Daniel Hilton Debra Henley 146832.0 65000.0 2.000000
Koepp Ltd Wendy Yule Fred Anderson 729833.0 35000.0 2.000000
Kulas Inc Daniel Hilton Debra Henley 218895.0 25000.0 1.500000
Purdy-Kunde Cedric Moss Fred Anderson 163416.0 30000.0 1.000000
Stokes LLC Cedric Moss Fred Anderson 239344.0 7500.0 1.000000
Trantow-Barrows Craig Booker Debra Henley 714466.0 15000.0 1.333333
分组和透视表的使用:
本试验的数据是飞机延误
In [15]: import numpy as np^M
...: import pandas as pd^M
...: from pandas import Series,DataFrame
...:
...:
In [16]: df = pd.read_csv('usa_flights.csv')
In [17]:
In [17]: df.head()
Out[17]:
flight_date unique_carrier ... security_delay actual_elapsed_time
0 02/01/2015 0:00 AA ... NaN 381.0
1 03/01/2015 0:00 AA ... NaN 358.0
2 04/01/2015 0:00 AA ... NaN 385.0
3 05/01/2015 0:00 AA ... NaN 389.0
4 06/01/2015 0:00 AA ... 0.0 424.0
[5 rows x 14 columns]
In [18]: df.shape # 查看数据的维度
Out[18]: (201664, 14)
In [22]: df.columns # 查看数据的列标签
Out[22]:
Index(['flight_date', 'unique_carrier', 'flight_num', 'origin', 'dest',
'arr_delay', 'cancelled', 'distance', 'carrier_delay', 'weather_delay',
'late_aircraft_delay', 'nas_delay', 'security_delay',
'actual_elapsed_time'],
dtype='object')
任务一:1.通过arr_delay排序观察延误时间最长top10
In [23]: df.sort_values('arr_delay',ascending=False).head(10)
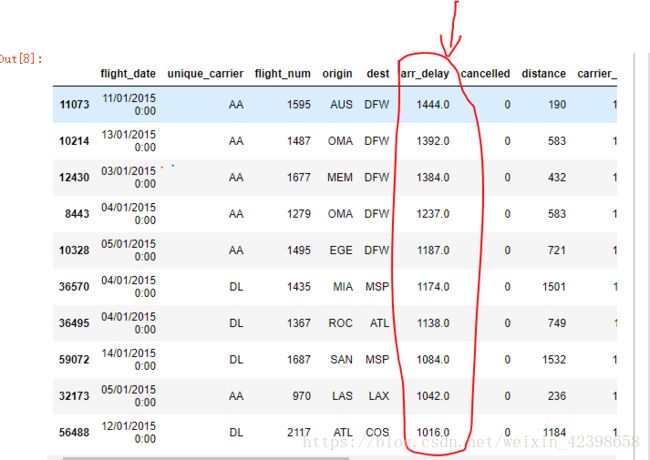
2.计算延误和没有延误的比例
In [24]: df['cancelled'].value_counts() # 计算取消航班和正常航班的总次数
Out[24]:
0 196873
1 4791
Name: cancelled, dtype: int64
In [25]: df['delayed'] = df['arr_delay'].apply(lambda x: x>0) #把延误的转为数值量
In [26]: df.head()
In [27]: delay_data = df['delayed'].value_counts()
In [28]: delay_data
Out[28]:
False 103037
True 98627
Name: delayed, dtype: int64
In [29]: delay_data[0]
Out[29]: 103037
In [30]: delay_data[1] / (delay_data[0] + delay_data[1])
Out[30]: 0.48906597112027933.每个航空公司的延误情况
In [31]: delay_group = df.groupby(['unique_carrier','delayed'])
In [32]: df_delay = delay_group.size().unstack()
In [33]: df_delay
Out[33]:
delayed False True
unique_carrier
AA 8912 9841
AS 3527 2104
B6 4832 4401
DL 17719 9803
EV 10596 11371
F9 1103 1848
HA 1351 1354
MQ 4692 8060
NK 1550 2133
OO 9977 10804
UA 7885 8624
US 7850 6353
VX 1254 781
WN 21789 21150
In [34]: import matplotlib.pyplot as plt
In [35]: df_delay.plot()