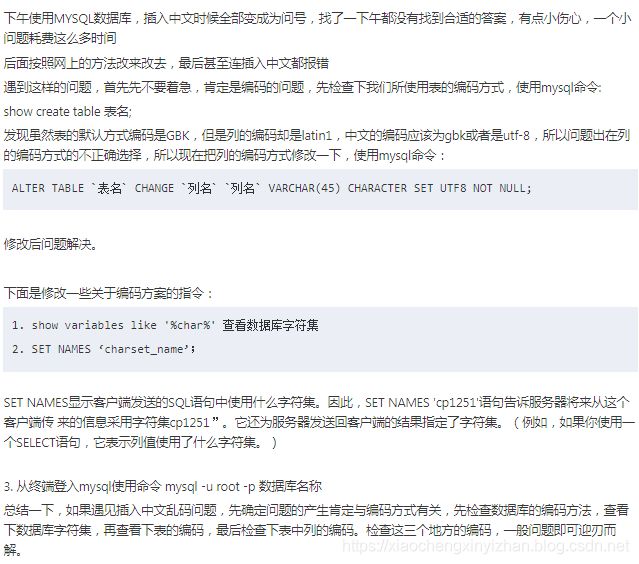
MySQL使用中的常见问题和排查思路
 解决方案:
解决方案:
https://blog.csdn.net/poice00/article/details/52129351
 mysql 秒杀的策略以及思考
mysql 秒杀的策略以及思考


CPU100%问题:
如果配置非常低的话,申请比较高的配置
1.show processlist 语句,查找负荷最重的 SQL 语句,优化该SQL,比如适当建立某字段的索引;
2.开启慢查询,找到性能瓶颈点的SQL语句,然后使用explain,看看该语句是否可以优化;
3.定期分析表,使用optimize table;
4.优化数据库对象;
5.考虑是否是锁问题;
6.在多用户,高并发的情况下,任何系统都会hold不住的,所以,使用缓存是必须的,就向楼上说的memcached,或者redis,这些都可以;
7.打开配置文件,看看tmp_table_size大小是否偏小,如果允许,适当的增大一点;
如果max_heap_table_size配置的过小,增大一点;调整一些MySQL Server参数,
比如key_buffer_size、table_cache、innodb_buffer_pool_size、innodb_log_file_size等等;
8.如果数据量过大,可以考虑使用MySQL集群或者搭建高可用环境
避免出现 CPU 使用率达到 100% 的一般原则
1、设置 CPU 使用率告警,实例 CPU 使用率保证一定的冗余度。
2、应用设计和开发过程中,要考虑查询的优化,遵守 MySQL 优化的一般优化原则,降低查询的逻辑 IO,提高应用可扩展性。
3、新功能、新模块上线前,要使用生产环境数据进行压力测试(可以考虑使用阿里云 PTS 压力测试工具)。
4、新功能、新模块上线前,建议使用生产环境数据进行回归测试。
5、建议经常关注和查看诊断报告。
两种典型问题:
应用负载(QPS)高
现象描述
特征:实例的 QPS(每秒执行的查询次数)高,查询比较简单、执行效率高、优化余地小。
表现:没有出现慢查询(或者慢查询不是主要原因),且 QPS 和 CPU 使用率曲线变化吻合。
常见场景:该状况常见于应用优化过的在线事务交易系统(例如订单系统)、高读取率的热门 Web 网站应用、第三方压力工具测试(例如 Sysbench)等。
解决方案
对于由应用负载高导致的 CPU 使用率高的状况,使用 SQL 查询进行优化的余地不大,建议您从应用架构、实例规格等方面来解决,例如:
升级实例规格,增加 CPU 资源。
增加只读实例,将对数据一致性不敏感的查询(比如商品种类查询、列车车次查询)转移到只读实例上,分担主实例压力。
进行分库分表,将查询压力分担到多个 RDS 实例上。
使用 Memcache 或者 Redis 产品,尽量从缓存中获取常用的查询结果,减轻 RDS 实例的压力。
对于查询数据比较静态、查询重复度高、查询结果集小于 1 MB 的应用,考虑开启查询缓存(Query Cache)。
注意:能否从开启查询缓存(Query Cache)中获益需要经过测试,具体设置请参见 RDS for MySQL 查询缓存(Query Cache)的设置和使用。
定期归档历史数据、采用分库分表或者分区的方式减小查询访问的数据量。
尽量优化查询,减少查询的执行成本(逻辑 IO,执行需要访问的表数据行数),提高应用可扩展性。
查询执行成本(查询访问表数据行数 avg_lgc_io)高
现象描述
特征:实例的 QPS(每秒执行的查询次数)不高;查询执行效率低、执行时需要扫描大量表中数据、优化余地大。
表现:存在慢查询,QPS 和 CPU 使用率曲线变化不吻合。
原因分析:由于查询执行效率低,为获得预期的结果即需要访问大量的数据(平均逻辑 IO高),在 QPS 并不高的情况下(例如网站访问量不大),就会导致实例的 CPU 使用率高。
解决方案
解决该状况的原则是:定位效率低的查询、优化查询的执行效率、降低查询执行的成本
通过 show processlist; 或 show full processlist; 命令查看当前执行的查询。
对于查询时间长、运行状态(State 列)是“Sending data”、“Copying to tmp table”、“Copying to tmp table on disk”、“Sorting result”、“Using filesort”等都可能是有性能问题的查询(SQL)。
注意:
若在 QPS 高导致 CPU 使用率高的场景中,查询执行时间通常比较短,show processlist; 命令或实例会话中可能会不容易捕捉到当前执行的查询。您可以通过执行如下命令进行查询:
explain select b.* from perf_test_no_idx_01 a, perf_test_no_idx_02 b where a.created_on >= 2015-01-01 and a.detail = b.detail
您可以通过执行类似 kill 101031643; 的命令来终止长时间执行的会话
根据优化建议,添加索引,查询执行成本就会大幅减少(如下图所示,从 900 亿行减小到 30 万行,查询成本降低 30 万倍),实例 CPU 使用率 100% 的问题解决。