数据分析学习笔记2020/8/3——pandas
pandas的常用数据类型:
Series 一维,带标签数组
DataFrame 二维,Series容器
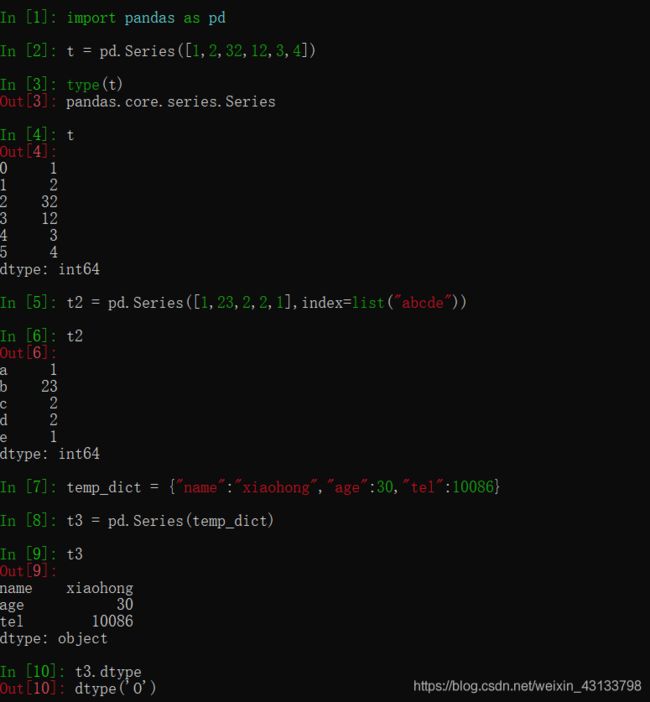
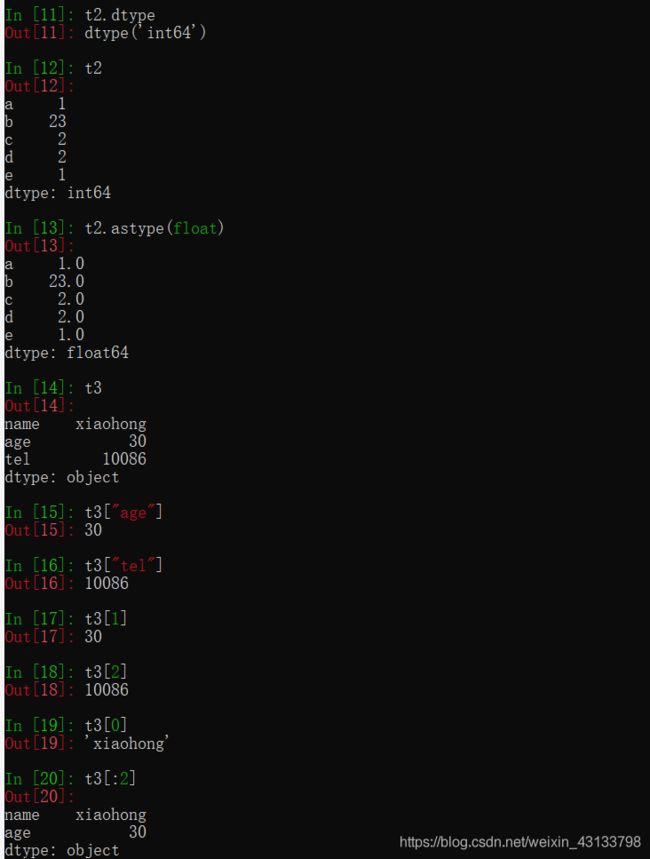
pandas之Series创建
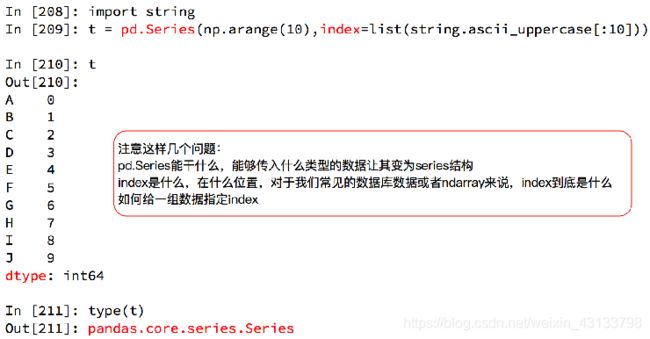

pandas之Series切片和索引
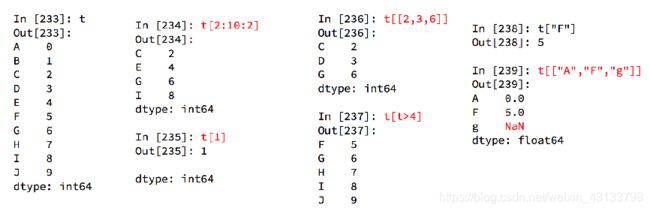

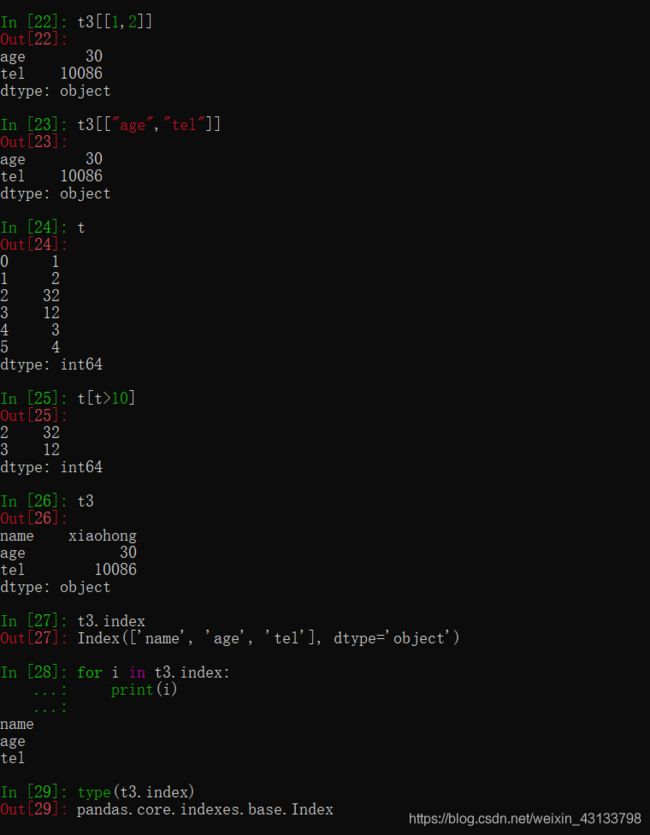
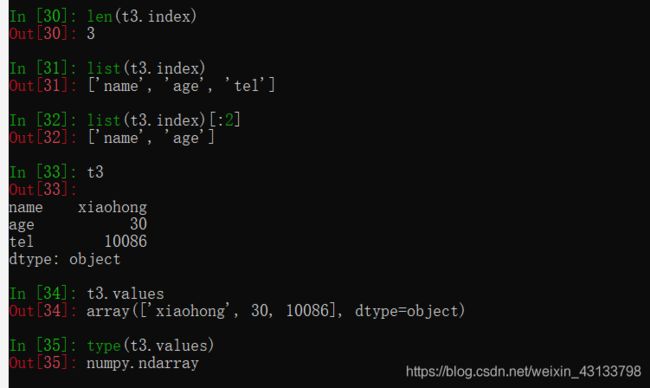
pandas之Series的索引和值
对于一个陌生的series类型,我们如何知道他的索引和具体的值呢?

pandas之读取外部数据

我们的这组数据存在csv中,我们直接使用pd. read_csv即可
和我们想象的有些差别,我们以为他会是一个Series类型,但是他是一个DataFrame,那么接下来我们就来了解这种数据类型
但是,还有一个问题:
对于数据库比如mysql或者mongodb中数据我们如何使用呢?
pd.read_sql(sql_sentence,connection)
那么,mongodb呢?
pandas之DataFrame


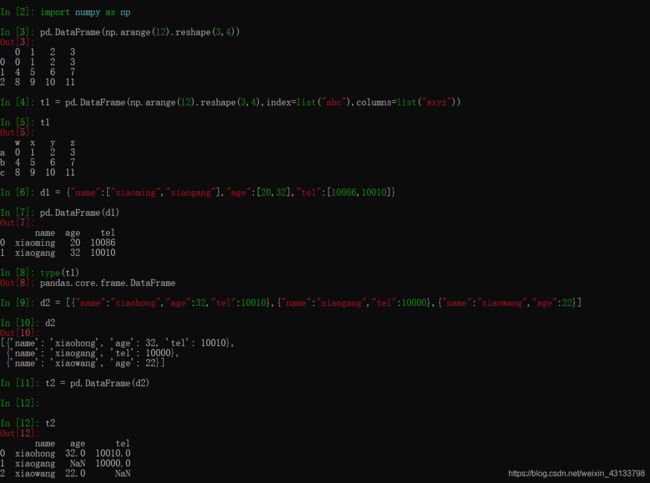
和一个ndarray一样,我们通过shape,ndim,dtype了解这个ndarray的基本信息,那么对于DataFrame我们有什么方法了解呢


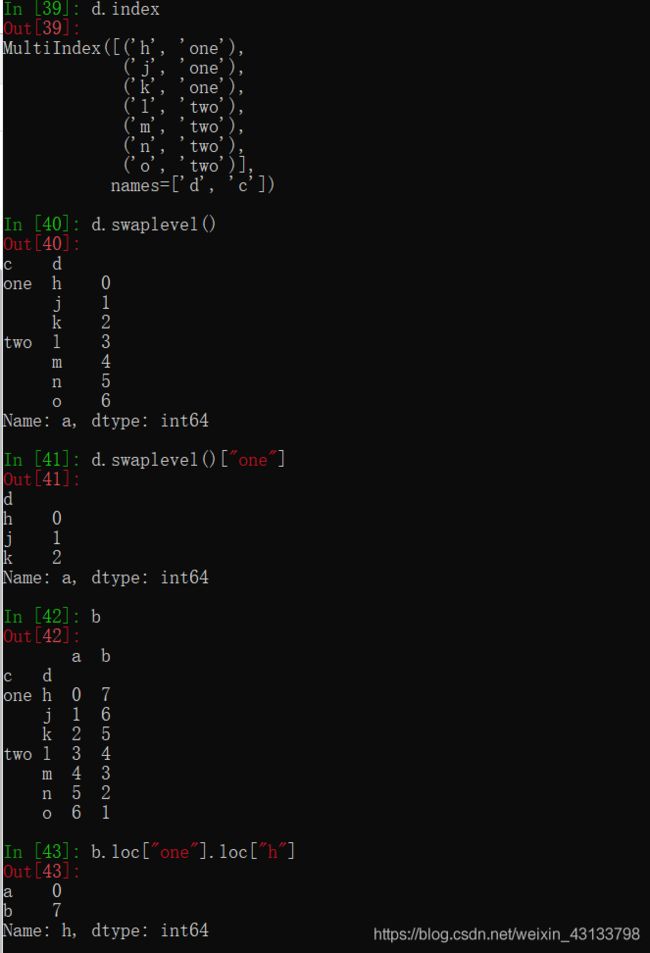
pandas之取行或者列

pandas之loc

pandas之iloc

pandas之布尔索引


pandas之字符串方法

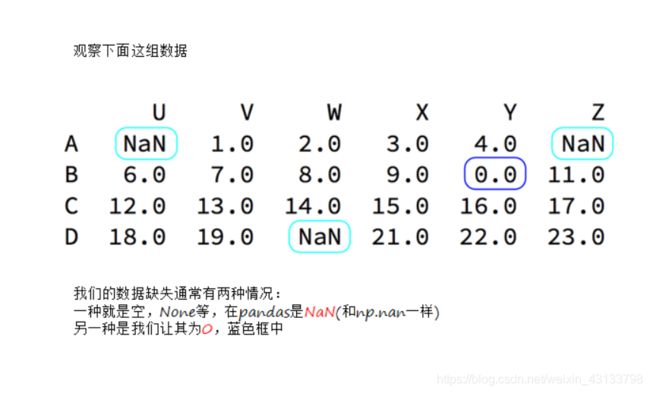
缺失数据的处理

pandas常用统计方法
假设现在我们有一组从2006年到2016年1000部最流行的电影数据,我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
import pandas as pd
file_path = "datasets_IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
#print(df.info())
print(df.head(1))
#获取平均评分
print(df["Rating"].mean())
#导演的人数
#print(len(set(df["Director"].tolist())))
print(len(df["Director"].unique()))
#获取演员的人数
temp_actors_list = df["Actors"].str.split(",").tolist()
actors_list = [i for j in temp_actors_list for i in j]
actors_num = len(set(actors_list))
print(actors_num)


import pandas as pd
from matplotlib import pyplot as plt
file_path = "datasets_IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
# print(df.head(1))
# print(df.info())
#rating,runtime分布情况
#选择图形,直方图
#准备数据
runtime_data = df["Runtime (Minutes)"].values
max_runtime = runtime_data.max()
min_runtime = runtime_data.min()
#计算组数
print(max_runtime-min_runtime)
num_bin= (max_runtime-min_runtime)//5
#设置图形的大小
plt.figure(figsize=(20,8),dpi=80)
plt.hist(runtime_data,num_bin)
plt.xticks(range(min_runtime,max_runtime+5,5))
plt.show()
import pandas as pd
from matplotlib import pyplot as plt
file_path = "datasets_IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
# print(df.head(1))
# print(df.info())
#rating,runtime分布情况
#选择图形,直方图
#准备数据
rating_data = df["Rating"].values
max_rating = rating_data.max()
min_rating = rating_data.min()
#计算组数
print(max_rating-min_rating)
num_bin_list = [1.6]
i = 1.6
while i<=max_rating:
i+=0.5
num_bin_list.append(i)
print(num_bin_list)
#设置图形的大小
plt.figure(figsize=(20,8),dpi=80)
plt.hist(rating_data,num_bin_list)
plt.xticks(num_bin_list)
plt.show()
思考
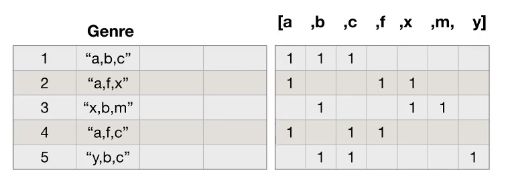
对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
思路:重新构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
file_path = "datasets_IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df["Genre"].head(3))
#统计分类的列表
temp_list = df["Genre"].str.split(",").tolist() #[[],[],[]]列表嵌套列表
print(temp_list)
genre_list = list(set([i for j in temp_list for i in j])) #去重
print(genre_list)
#构造全为0的数组,columns是每个分类
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
print(zeros_df)
#给每个电影出现分类的位置赋值1
for i in range(df.shape[0]):
#zeros_df.loc[0,["Sci-fi","Mucical"]] = 1
zeros_df.loc[i,temp_list[i]] = 1
print(zeros_df.head(3))
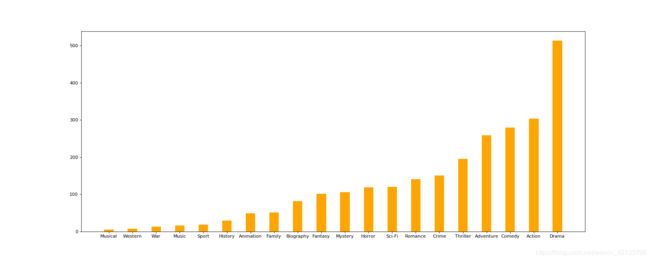
#统计每个分类的电影的数量和
genre_count = zeros_df.sum(axis=0)
print(genre_count)
#排序
genre_count = genre_count.sort_values()
_x = genre_count.index
_y = genre_count.values
#画图
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y,width=0.4,color="orange")
plt.xticks(range(len(_x)),_x)
plt.show()



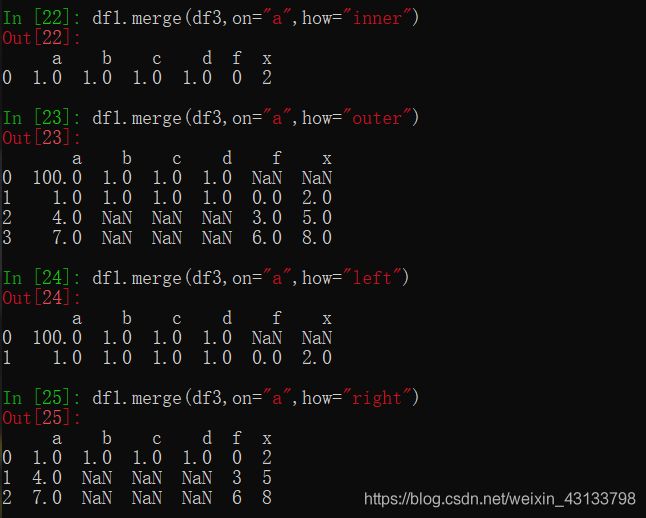



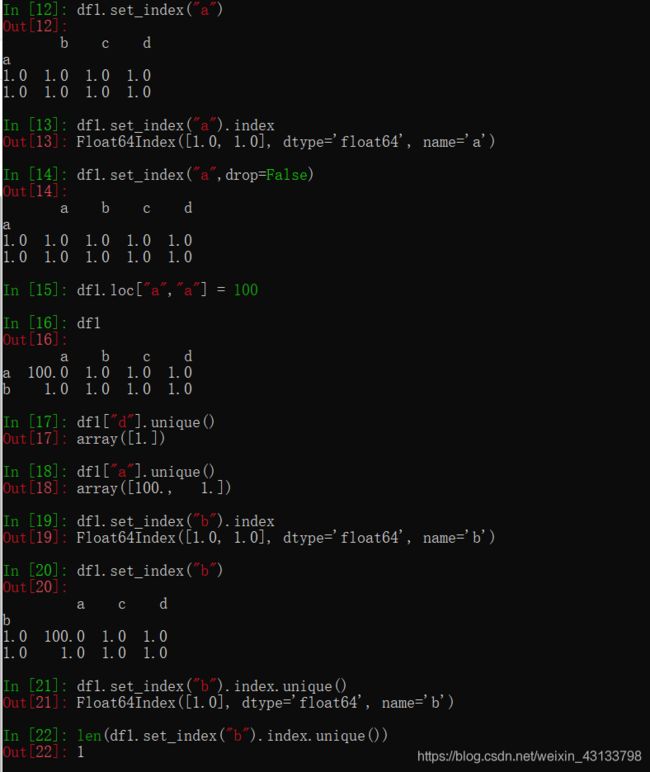
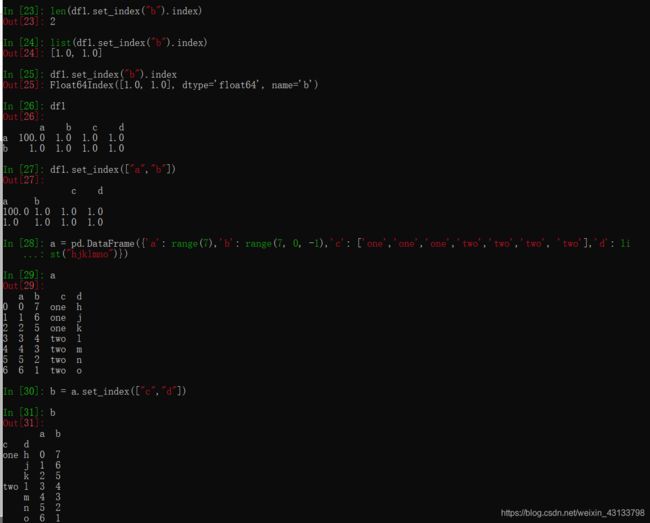
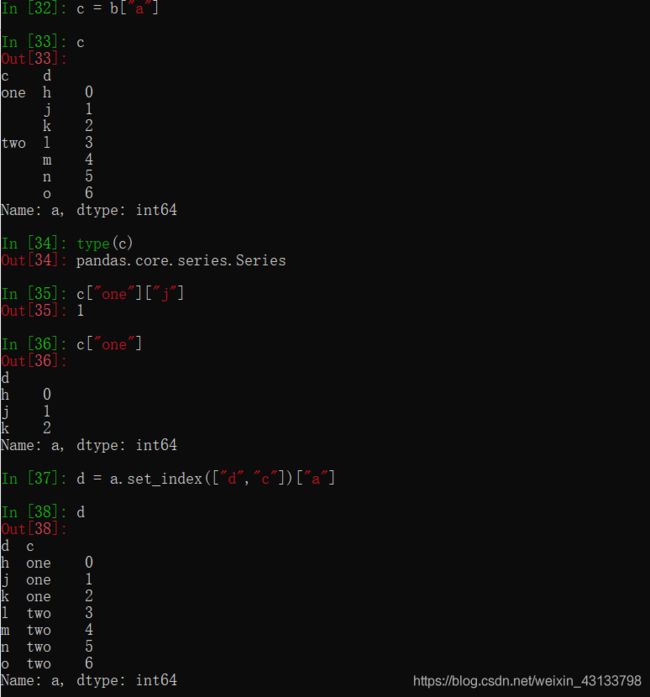
分组和聚合





import pandas as pd
import numpy as np
file_path = "./starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
print(df.head(1))
# print(df.info())
grouped = df.groupby(by="Country")
print(grouped)
#DataFrameGroupBy
#可以进行遍历
# for i,j in grouped:
# print(i)
# print("-"*100)
# print(j,type(j))
# print("*"*100)
# df[df["Country"]="US"]
#调用聚合方法
country_count = grouped["Brand"].count()
print(country_count)
print(country_count["US"])
print(country_count["CN"])
#统计中国每个省店铺的数量
china_data = df[df["Country"] =="CN"]
print(china_data)
grouped = china_data.groupby(by="State/Province").count()["Brand"]
#
print(grouped)
#数据按照多个条件进行分组,返回Series
# grouped = df["Brand"].groupby(by=[df["Country"],df["State/Province"]]).count()
# print(grouped)
# print(type(grouped))
#数据按照多个条件进行分组,返回DataFrame
grouped1 = df[["Brand"]].groupby(by=[df["Country"],df["State/Province"]]).count()
# grouped2= df.groupby(by=[df["Country"],df["State/Province"]])[["Brand"]].count()
# grouped3 = df.groupby(by=[df["Country"],df["State/Province"]]).count()[["Brand"]]
print(grouped1,type(grouped1))
# print("*"*100)
# print(grouped2,type(grouped2))
# print("*"*100)
#
# print(grouped3,type(grouped3))
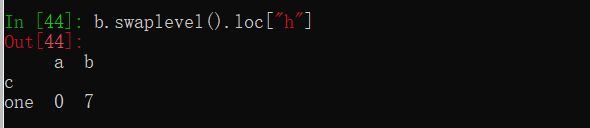
#索引的方法和属性
print(grouped1.index)
索引和复合索引

Series复合索引

DataFrame复合索引

动手1:
1.使用matplotlib呈现出店铺总数排名前10的国家
2.使用matplotlib呈现出每个中国每个城市的店铺数量
import pandas as pd
from matplotlib import pyplot as plt
file_path = "starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
# 使用matplotlib呈现出店铺总数排名前10的国家
# 准备数据
data1 = df.groupby(by="Country").count()["Brand"].sort_values(ascending=False)[:10]
_x = data1.index
_y = data1.values
# 画图
plt.figure(figsize=(20, 8), dpi=80)
plt.bar(range(len(_x)), _y)
plt.xticks(range(len(_x)), _x)
plt.show()

import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname="C:\Windows\Fonts\STXINGKA.TTF")
file_path = "./starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
df = df[df["Country"]=="CN"]
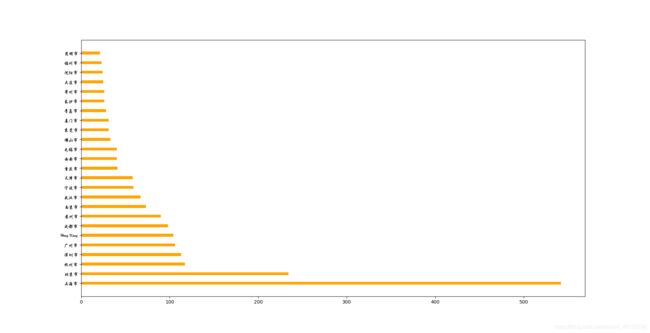
#使用matplotlib呈现出店铺总数排名前10的国家
#准备数据
data1 = df.groupby(by="City").count()["Brand"].sort_values(ascending=False)[:25]
_x = data1.index
_y = data1.values
#画图
plt.figure(figsize=(18,15),dpi=100)
# plt.bar(range(len(_x)),_y,width=0.3,color="orange")
plt.barh(range(len(_x)),_y,height=0.3,color="orange")
plt.yticks(range(len(_x)),_x,fontproperties=my_font)
plt.show()
动手2:
现在我们有全球排名靠前的10000本书的数据,那么请统计一下下面几个问题:
1.不同年份书的数量
2.不同年份书的平均评分情况
import pandas as pd
from matplotlib import pyplot as plt
file_path = "./books.csv"
df = pd.read_csv(file_path)
# print(df.head(2))
#
# print(df.info())
# data1 = df[pd.notnull(df["original_publication_year"])]
# #print(data1)
# grouped = data1.groupby(by="original_publication_year").count()["title"]
# print(grouped)
#不同年份书的平均评分情况
#去除original_publication_year列中nan的行
data1 = df[pd.notnull(df["original_publication_year"])]
grouped = data1["average_rating"].groupby(by=data1["original_publication_year"]).mean()
print(grouped)
_x = grouped.index
_y = grouped.values
print(_x)
#画图
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
print(len(_x))
plt.xticks(list(range(len(_x)))[::10],_x[::10].astype(int),rotation=45)
plt.show()

动手3:
现在我们有2015到2017年25万条911的紧急电话的数据,请统计出出这些数据中不同类型的紧急情况的次数,如果我们还想统计出不同月份不同类型紧急电话的次数的变化情况,应该怎么做呢?
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv("./911.csv")
print(df.head(5))
#获取分类
# print()df["title"].str.split(": ")
temp_list = df["title"].str.split(": ").tolist()
cate_list = list(set([i[0] for i in temp_list]))
print(cate_list)
#构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(cate_list))),columns=cate_list)
#赋值
for cate in cate_list:
zeros_df[cate][df["title"].str.contains(cate)] = 1
# break
# print(zeros_df)
sum_ret = zeros_df.sum(axis=0)
print(sum_ret)
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv("./911.csv")
print(df.head(5))
#获取分类
# print()df["title"].str.split(": ")
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
# print(df.head(5))
print(df.groupby(by="cate").count()["title"])

生成一段时间范围

关于频率的更多缩写


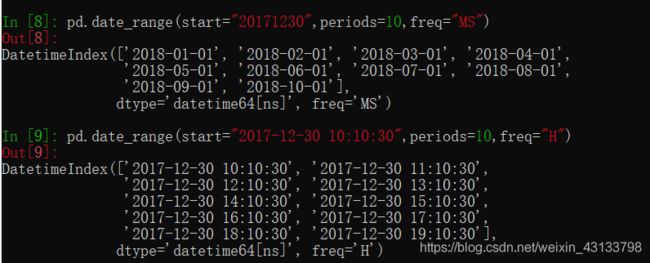
在DataFrame中使用时间序列
index=pd.date_range("20170101",periods=10)
df = pd.DataFrame(np.random.rand(10),index=index)
回到最开始的911数据的案例中,我们可以使用pandas提供的方法把时间字符串转化为时间序列
df["timeStamp"] = pd.to_datetime(df["timeStamp"],format="")
format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文
那么问题来了:
我们现在要统计每个月或者每个季度的次数怎么办呢?
pandas重采样

动手4:
1.统计出911数据中不同月份电话次数的变化情况
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df.set_index("timeStamp",inplace=True)
#统计出911数据中不同月份电话次数的
count_by_month = df.resample("M").count()["title"]
print(count_by_month)
#画图
_x = count_by_month.index
_y = count_by_month.values
# for i in _x:
# print(dir(i))
# break
_x = [i.strftime("%Y%m%d") for i in _x]
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.show()
2.统计出911数据中不同月份不同类型的电话的次数的变化情况
#911数据中不同月份不同类型的电话的次数的变化情况
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#把时间字符串转为时间类型设置为索引
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
#添加列,表示分类
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
# print(np.array(cate_list).reshape((df.shape[0],1)))
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
df.set_index("timeStamp",inplace=True)
print(df.head(1))
plt.figure(figsize=(20, 8), dpi=80)
#分组
for group_name,group_data in df.groupby(by="cate"):
#对不同的分类都进行绘图
count_by_month = group_data.resample("M").count()["title"]
# 画图
_x = count_by_month.index
print(_x)
_y = count_by_month.values
_x = [i.strftime("%Y%m%d") for i in _x]
plt.plot(range(len(_x)), _y, label=group_name)
plt.xticks(range(len(_x)), _x, rotation=45)
plt.legend(loc="best")
plt.show()
思考
现在我们有北上广、深圳、和沈阳5个城市空气质量数据,请绘制出5个城市的PM2.5随时间的变化情况
观察这组数据中的时间结构,并不是字符串,这个时候我们应该怎么办?
PeriodIndex
之前所学习的DatetimeIndex可以理解为时间戳
那么现在我们要学习的PeriodIndex可以理解为时间段
periods = pd.PeriodIndex(year=data["year"],month=data["month"],day=data["day"],hour=data["hour"],freq="H")
那么如果给这个时间段降采样呢?data = df.set_index(periods).resample("10D").mean()
动手5:
请绘制出5个城市的PM2.5随时间的变化情况
import pandas as pd
from matplotlib import pyplot as plt
file_path = "./PM2.5/BeijingPM20100101_20151231.csv"
df = pd.read_csv(file_path)
#把分开的时间字符串通过periodIndex的方法转化为pandas的时间类型
period = pd.PeriodIndex(year=df["year"],month=df["month"],day=df["day"],hour=df["hour"],freq="H")
df["datetime"] = period
# print(df.head(10))
#把datetime 设置为索引
df.set_index("datetime",inplace=True)
#进行降采样
df = df.resample("7D").mean()
print(df.head())
#处理缺失数据,删除缺失数据
# print(df["PM_US Post"])
data =df["PM_US Post"]
data_china = df["PM_Nongzhanguan"]
print(data_china.head(100))
#画图
_x = data.index
_x = [i.strftime("%Y%m%d") for i in _x]
_x_china = [i.strftime("%Y%m%d") for i in data_china.index]
print(len(_x_china),len(_x_china))
_y = data.values
_y_china = data_china.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y,label="US_POST",alpha=0.7)
plt.plot(range(len(_x_china)),_y_china,label="CN_POST",alpha=0.7)
plt.xticks(range(0,len(_x_china),10),list(_x_china)[::10],rotation=45)
plt.legend(loc="best")
plt.show()