ambari2.7.4集成hue4.6.0
版本信息
Ambari:2.7.4
HDP:3.1.4
HUE:4.6.0
ambari-hue-service 集成插件:https://github.com/lijufeng2016/ambari-hue-service 本人已把所有坑填完,插件已适配组新版ambari
环境准备
1.hue的master节点上执行,为编译环境做准备
yum install sqlite-devel libxslt-devel.x86_64 python-devel openldap-devel asciidoc cyrus-sasl-gssapi libxml2-devel.x86_64 mysql-devel gcc gcc-c++ kernel-devel openssl-devel gmp-devel libffi-devel install npm
2.所有机器上创建用户和组
useradd -g hue hue
3.提前在mysql创建好hue的库并授权
CREATE DATABASE hue;
GRANT ALL PRIVILEGES ON hue.* TO hue@'%' IDENTIFIED BY '123456';
FLUSH PRIVILEGES;
4.提前建好hue在hdfs的HOME目录
hadoop fs -mkdir /user/hue
hadoop fs -chown hue:hue /user/hue
5.下载插件源码
在ambari server节点执行
VERSION=`hdp-select status hadoop-client | sed 's/hadoop-client - \([0-9]\.[0-9]\).*/\1/'`
rm -rf /var/lib/ambari-server/resources/stacks/HDP/$VERSION/services/HUE
sudo git clone https://github.com/lijufeng2016/ambari-hue-service.git /var/lib/ambari-server/resources/stacks/HDP/$VERSION/services/HUE
6.hue的安装包并放到你的Apache服务器上

在ambari server节点执行
代码修改
-
package/files/configs.sh文件
USERID='ambari的管理员账号' PASSWD='ambari的管理员密码' -
package/scripts/params.py文件
第32行 download_url 改成你自己的地址,可以跟hdp的本地仓库放一起
第40行 ambari_server_hostname 改成你自己的地址
部署安装
重启ambari
ambari-server restart
ambari界面操作
界面左侧 >> services >> Add service >> Hue >> NEXT >> 选择Hue Server >> NEXT >> 配置
数据库配置,这里选了mysql:
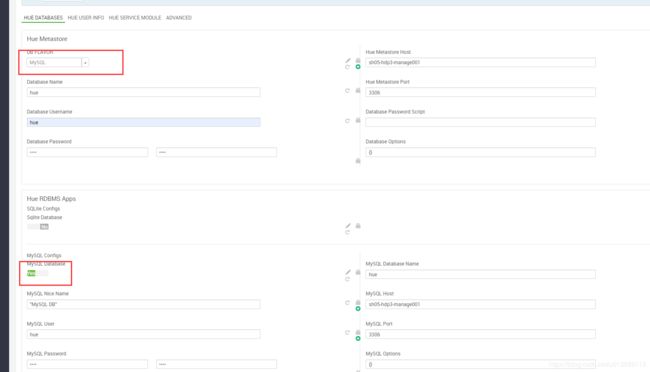
一路next, 启动失败先忽视

启动hue报错:
UnicodeEncodeError: 'ascii' codec can't encode character u'\u201c' in position 3462: ordinal not in range(128)
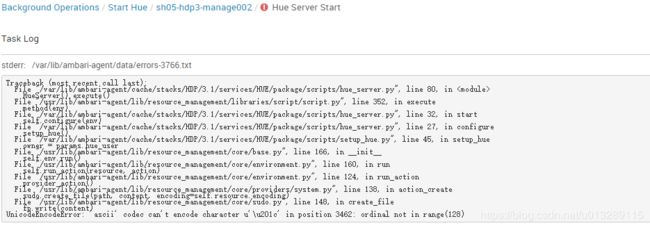
解决办法:
在hue的安装节点上:
vim /usr/lib/ambari-agent/lib/resource_management/core/sudo.py
网上的说的/usr/lib/python2.7/site-packages/resource_management/core/sudo.py文件在新版本中不适用!
添加如下代码:
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8’)

编译
cd /usr/hdp/3.1.4.0-315/hue/
make apps
注意:在准备工作的第一步的包必须安装才能编译成功
再次启动报错:Invalid HTTP_HOST header: ‘sh05-hdp3-manage002:8888’. You may need to add u’sh05-hdp3-manage002’ to ALLOWED_HOSTS.

解决办法:找到Advanced pseudo-distributed.ini 配置
allowed_hosts=*
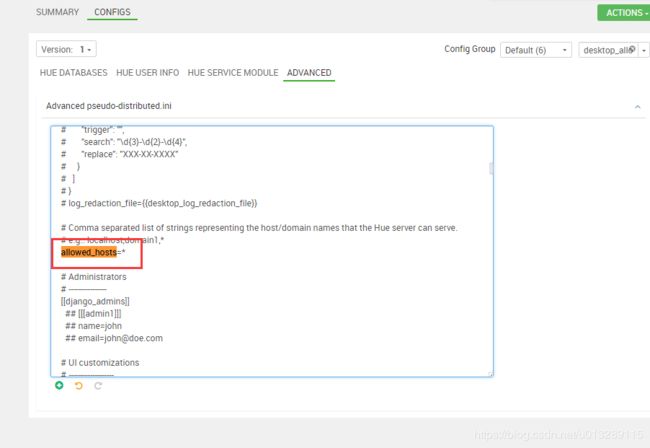
改完重启,终于看到人样的页面了,输入hue hue,你随意

进去发现加载数据库错误

解决方法:
vim /usr/hdp/3.1.4.0-315/hue/desktop/core/src/desktop/lib/conf.py
第293行改为:
if raw is None or raw=='':
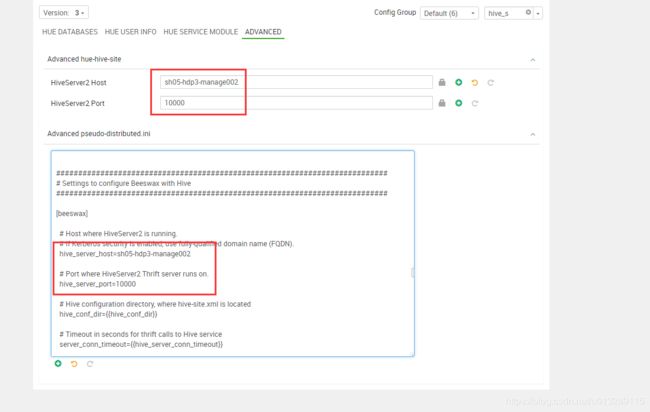
再次重启hue,又报错:ERROR Error running create_session

明显的哪里把端口号当成字符串输入了
解决方法:
把hiveserver2的host和端口号手动设置一下
重启,又报错:TSocket read 0 bytes (code THRIFTTRANSPORT): TTransportException(‘TSocket read 0 bytes’,)

解决办法:
在beeswax的配置下面加上 use_sasl=true
从哪里跌倒就从哪里爬起,再重启,页面终于正常啦!尽情的玩耍了!咦?不对啊?

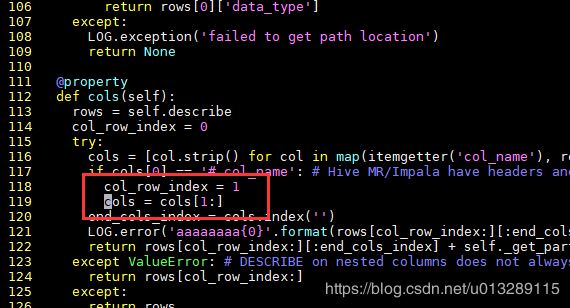
怎么会显示无列呢?
新版的hue4.6.0与hdp3.1.4这种双新组合往往自带坑位,网上也找不到任何答案,经过一步步推测排查,首先可以确定的是后端返回字段的时候有问题,与之相关的是hive相关的包,经过漫长的一步一步排查,确定到了哪一行代码,python真不习惯,也没开发过,太难了,中间过程就不细说了,直接上解决方法:
vim /usr/hdp/3.1.4.0-315/hue/apps/beeswax/src/beeswax/server/hive_server2_lib.py
118行和119行的2改成1即可
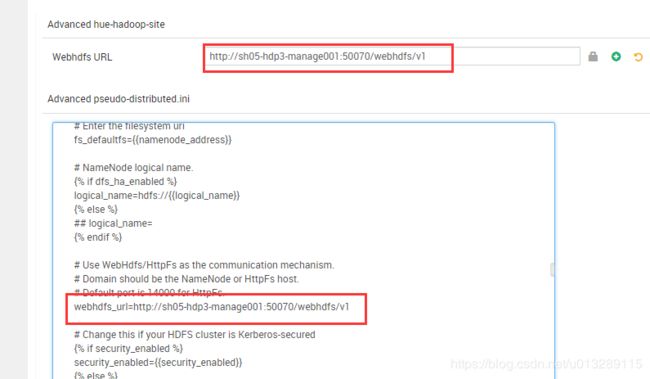
重启,想查看hdfs,又遇到问题

解决方法:
webhdfs_url=http://sh05-hdp3-manage001:50070/webhdfs/v1
继续,查看hbase报错
Api 错误:HTTPConnectionPool(host=‘sh05-hdp3-manage003’, port=9090): Max retries exceeded with url: / (Caused by NewConnectionError(’: Failed to establish a new connection: [Errno 111] Connection refused’,))

解决办法:
hdp3中,hbase的thrift默认不开启,需要手动在各个Hmaster节点启动,注意,一定要使用hbase用户启动thrift,而不是thrift2!!否则后面还会有问题,上代码
su hbase
/usr/hdp/current/hbase-master/bin/hbase-daemon.sh start thrift
建议把启动thrift的命令写到启动hbase master的脚本里,这样就不用每次手动起了
集成sparksql无法正常显示表名,库下所有表名都变成库名的问题
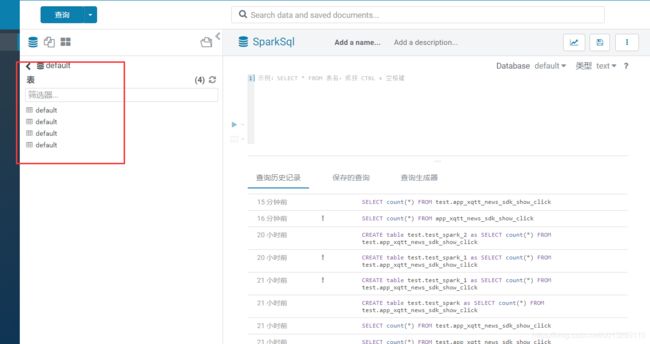
由于是用spark的thrift方式连接的sparksql,在hue.ini里面的配置
[[[sql]]]
name=SparkSql
interface=sqlalchemy
options='{"url": "hive://sh05-hdp3-manage003:10016/default"}'
注意是[[[sql]]]不是[[[sparksql]]],这里的spark的thrift端口是10016,而不是用的hive的10000
出现上述图片的错误,由于spark与hive用的都是sqlalchemy,但是接口返回的结果格式不一样,需要修改pyhive的相关代码,前提必须是pip方式安装pyhive,setup方式由于会打包编译py文件导致没有明文代码可以修改,修改如下:
vim ./build/env/lib/python2.7/site-packages/pyhive/sqlalchemy_hive.py
# get_table_names 方法里面的最后一行替换为如下,由于我这里是10016端口,需要根据自己的spark thrift端口的实际配置
url = '{0}'.format(connection)
if '10016' in url:
return [row[1] for row in connection.execute(query)]
else:
return [row[0] for row in connection.execute(query)]
到这里基本上差不多解决了,记住一定要按步骤来,一步棋错全盘皆输!在解决这些问题的时候折腾了很久。在ambari-hue-service插件上面的改造上面画了比较长的时间,由于是全新版本,只能站在巨人肩膀上。安装过程中,兼容问题频频发生,需要耐心的从原理源码角度出发解决问题,所有问题都不是问题!