Caffe MNIST LeNet
LeNet是一个用来识别手写数字的最经典的卷积神经网络,是Yann LeCun在1998年设计并提出的,是早期神经网络中最具有代表性的实现系统之一,其论文是CNN领域的第一篇经典之作。
1. LeNet模型简介
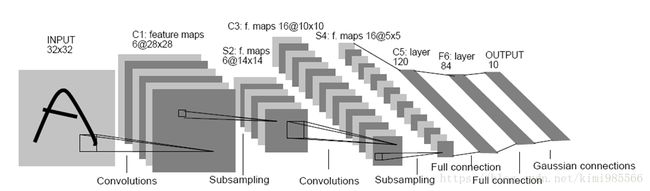
LeNet网络的规模较小,但包含了卷基层、Pooling层、全连接层,这些都是构成现代CNN网络的基本组件,后续更加复杂的网络模型都离不开这些基本网络层组件。
LeNet包含输入层在内共有八层网络,每一层都包含了多个参数(权重)。
- C层代表的是卷基层,通过卷积操作,可以使原信号增强,并降低噪声。
- S层是一个下采样层,利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量,同时也可保留一定的有用信息。
2. 模型解读
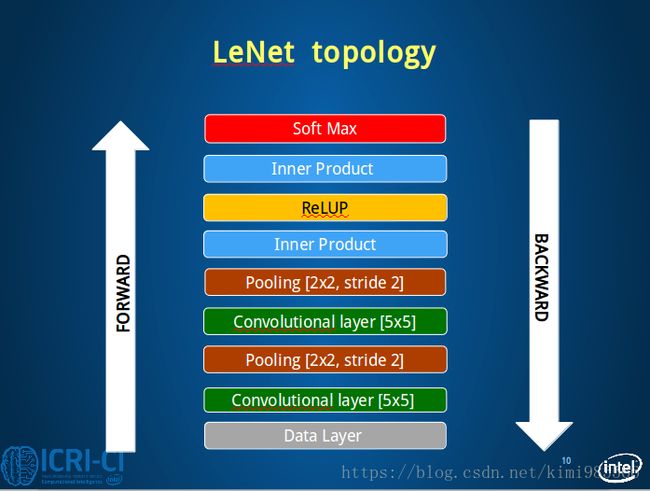
2.1 第一层:Data Layer
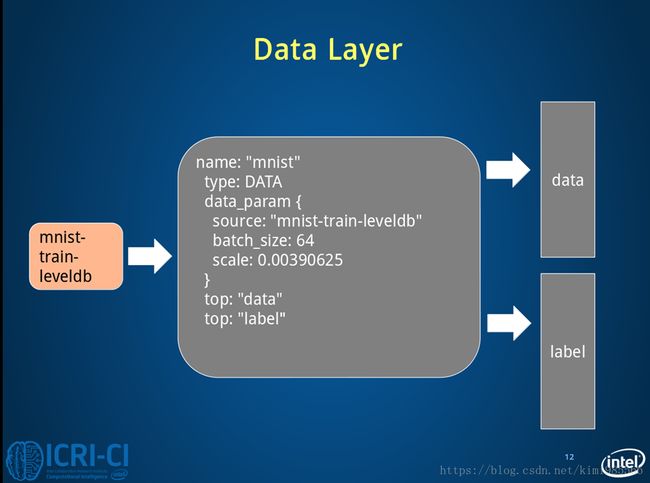
输入层是32×32大小的图像(Caffe中Mnist数据库为28×28),这样做的原因是希望潜在的明显特征,如笔画断续、角点能够出现在最高层特征检测子感受野的中心。 Caffe中采用4D表示,N×C×H×W(Num×Channels×Height×Width)。
#====================定义TRAIN的数据层====================
layer {
name: "mnist" #定义该层的名字
type: "Data" #该层的类型是数据
top: "data" #该层生成一个data blob
top: "label" #该层生成一个label blob
include {
phase: TRAIN #说明该层只在TRAIN阶段使用
}
transform_param {
scale: 0.00390625 #数据归一化系数,1/256,归一到[0,1]
}
data_param {
source: "examples/mnist/mnist_train_lmdb" #训练数据的路径
batch_size: 64 #批量处理的大小
backend: LMDB
}
}
#====================定义TEST的数据层====================
layer {
name: "mnist" #输入层的名称mnist
type: "Data"
top: "data" #本层下一层连接data层和label blob空间
top: "label"
include {
phase: TEST #说明该层只在TEST阶段使用,测试阶段
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb" #测试数据的路径
batch_size: 100
backend: LMDB
}
}2.2 第二层:Conv1 Layer C1
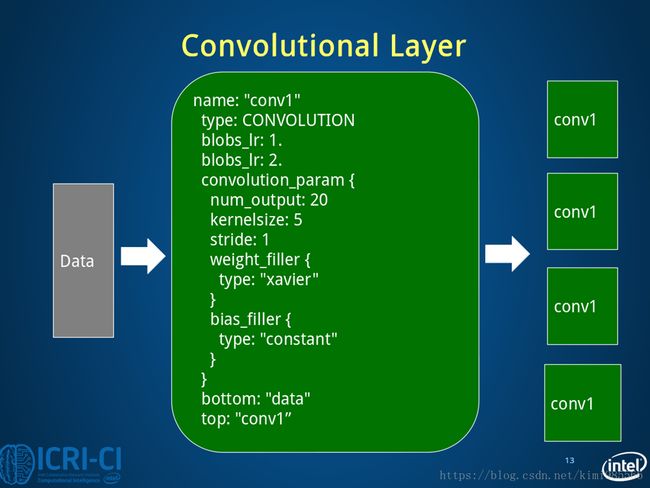
C1层是一个卷积层,6个特征图,5×5大小的卷积核,每个特征图有(32-5+1)×(32-5+1)=28×28个神经元,每个神经元都与输入层的5×5大小的区域相连。所以C1层共有(5×5+1)×6=156个训练参数。两层之间的连接数都为156×(28×28)=122304个。通关卷积运算,使原型号特征增强,并且降低噪声,而且不同的卷积核能够提取到图像中的不同特征。
#====================定义卷积层1====================
layer {
name: "conv1" #该层的名字conv1,即卷积层1
type: "Convolution" #该层的类型是卷积层
bottom: "data" #该层使用的数据是由数据层提供的data blob
top: "conv1" #该层生成的数据是conv1
param {
lr_mult: 1 #weight learning rate(简写为lr)权值的学习率,1表示该值是lenet_solver.prototxt中base_lr: 0.01的1倍
}
param {
lr_mult: 2 #bias learning rate偏移值的学习率,2表示该值是lenet_solver.prototxt中base_lr: 0.01的2倍
}
convolution_param {
num_output: 20 #产生20个输出通道
kernel_size: 5 #卷积核的大小为5*5
stride: 1 #卷积核移动的步幅为1
weight_filler {
type: "xavier" #xavier算法,根据输入和输出的神经元的个数自动初始化权值比例
}
bias_filler {
type: "constant" #将偏移值初始化为“稳定”状态,即设为默认值0
}
}
}2.3 第三层:Pool1 Layer S2
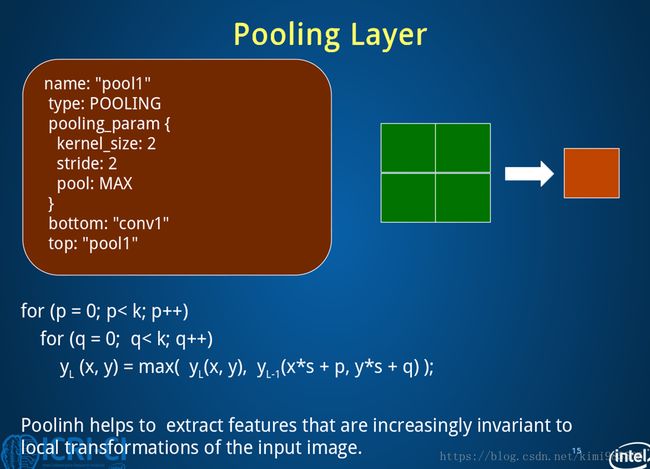
S2层是一个下采样层,有6个14×14的特征图,每个特征图中的每个神经元都与C1层对应的特征图中的2×2的区域相连。S2层中的每个神经元是由4个输入相加,乘以一个训练系数,再加上这个特征图的偏置参数,结果通过sigmoid函数计算得到。S2的每一个feature map有14×14个神经元,参数个数为2×6=12个,连接数为(4+1)×(14×14)×6=5880个连接。下采样层的目的是为了降低网络训练参数及模型的过拟合程度。
下采样的池化方法一般有两种:
- 一是选择Pooling窗口中的最大值作为采样值,即最大值池化;
- 二是将Pooling窗口中的所有值相加取平均值作为采样值,即均值池化。
#====================定义池化层1====================
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1" #该层使用的数据是由conv1层提供的conv1
top: "pool1" #该层生成的数据是pool1
pooling_param {
pool: MAX #采用最大值池化
kernel_size: 2 #池化核大小为2*2
stride: 2 #池化核移动的步幅为2,即非重叠移动
}
}2.4 第四层:Conv2 Layer C3
C3层也是一个卷积层,运用5×5的卷积核,处理S2层。计算C3的特征图的神经元个数为(14-5+1)×(14-5+1),即10×10。C3有16个特征图,每个特征图由上一层的各特征图之间的不同组合。训练参数个数(5×5×3+1)×6+(5×5×4+1)×9+(5×5×6+1)×1=1516,所以总共有151600个连接。
#====================定义卷积层2====================
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
2.5 第五层:Pool2 Layer S4
S4层是一个下采样层,由16个5×5大小的特征图构成,每个神经元与C3中对应特征图的2×2大小的区域相连接。所以有32个参数和2000个连接。
#====================定义池化层2====================
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}2.6 第六层:Conv3 Layer C5
C5层又是一个卷积,卷积核5×5,每个特征图(5-5+1)×(5-5+1),即1×1个神经元,每个单元 都与S4层的全部16个特征图相连。C5层共有120个特征图,连接数都为48120个。
2.7 第七层:Ip1 Layer F6

F6全连接层有84个特征图,每个特征图只有一个神经元与C5层全相连,故有(1×1×120+1)×84=10164个参数与连接。F6层计算输入向量和权重向量之间的点积和偏置,之后将其传递给sigmoid函数来计算神经元。
#====================定义全连接层1====================
layer {
name: "ip1"
type: "InnerProduct" #该层的类型为全连接层
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500 #有500个输出通道
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}2.8 Relu1 Layer

#====================定义ReLU1层====================
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}2.9 第八层:输出层
输出层也是全连接层,共有10个节点,分别代表0到9,且节点i的值为0,则网络的数字结果就是数字i。
#====================定义全连接层2====================
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10 #10个输出数据,对应0-9十个数字
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}2.10 Loss Layer
#====================定义损失函数层====================
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}注意到caffe LeNet中有一个accuracy layer的定义,这是输出测试结果的层。
3. Mnist手写测试
手写数字必须满足以下的条件:
- 必须是256位黑白色
- 必须是黑底白字
- 像素大小必须是28*28
- 数字在图片中间,上下左右没有过多的空白
参考
- Chapter 4 深入理解Caffe MNIST DEMO中的LeNet网络模型