爬虫实战——爬取腾讯招聘的职位信息(2020年2月2日)
爬取腾讯招聘的职位信息
- 思路分析
- 特别说明
- 1、获取PostId列表
- 2、爬取详情页面
- 3、保存数据
- 完整代码
- 结果展示
- 总结分析
思路分析
特别说明
本文以Java工作岗位信息为例进行说明,如果想爬取其他岗位的信息,更改URL请求中的关键字即可。方法仅供交流学习,不要用来做违法的事情。
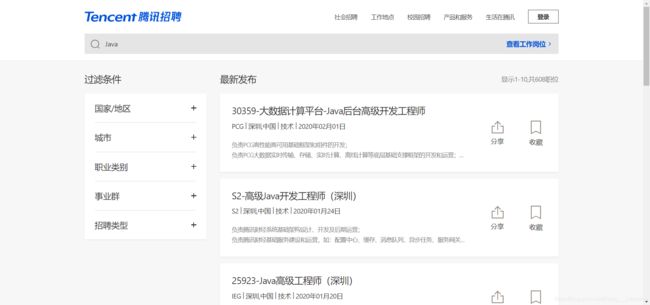
1、获取PostId列表
由于网页中每一个职位都有一个PostId,而爬取职位的详情信息时,需要用到PostId来构造请求的URL,因此,我先将职位的PostId存放到列表中,为下一步爬取职位的详情信息做准备。
def get_url():
# 爬取的页数,这里爬取前10页
endIndex = 10
postId = []
for pageIndex in range(1, endIndex+1):
query['timestamp'] = int(time.time())
query['pageIndex'] = pageIndex
url = raw_url.format(query['timestamp'], query['keyword'], query['pageIndex'], query['pageSize'],
query['language'], query['area'])
try:
r = requests.get(url, headers=headers)
except :
print("请求失败!")
continue
data_list = json.loads(r.text)['Data']['Posts']
for item in data_list:
postId.append(item['PostId'])
print(item['PostId'])
return postId
2、爬取详情页面
利用上一步得到的PostId列表即可构造URL发送请求,这里可以用Python的time模块来处理时间戳的问题,然后,再将爬到信息以列表的形式返回,方便后面进行数据存储。
def get_detail(post_id):
data_list = []
for it in post_id:
url = post_url % (int(time.time()), it)
try:
response = requests.get(url, headers)
except :
print("请求失败!")
continue
if response.status_code == 200:
data = json.loads(response.text)['Data']
data_list += [data]
print(data)
return data_list
3、保存数据
将数据保存成CSV文件即可
def save_to_file(data_list):
df = pd.DataFrame(data_list)
df.to_csv('./result/tencent.csv', index=False, encoding='utf_8_sig')
完整代码
# !/usr/bin/env python
# —*— coding: utf-8 —*—
# @Time: 2020/2/2 14:36
# @Author: Martin
# @File: tencent_hr.py
# @Software:PyCharm
import requests
import time
import json
from lxml import etree
import pandas as pd
# 请求头部信息
headers = {
'referer': 'https://careers.tencent.com/search.html?keyword=Java',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
query = {
'timestamp': '',
'countryId': '',
'cityId': '',
'bgIds': '',
'productId': '',
'categoryId': '',
'parentCategoryId': '',
'attrId': '',
'keyword': 'Java',
'pageIndex': '',
'pageSize': '10',
'language': 'zh-cn',
'area': 'cn'
}
raw_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp={}&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword={}&pageIndex={}&pageSize={}&language={}&area={}'
post_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=%d&postId=%s&language=zh-cn'
def get_url():
# 爬取的页数,这里爬取前10页
endIndex = 10
postId = []
for pageIndex in range(1, endIndex+1):
query['timestamp'] = int(time.time())
query['pageIndex'] = pageIndex
url = raw_url.format(query['timestamp'], query['keyword'], query['pageIndex'], query['pageSize'],
query['language'], query['area'])
try:
r = requests.get(url, headers=headers)
except :
print("请求失败!")
continue
data_list = json.loads(r.text)['Data']['Posts']
for item in data_list:
postId.append(item['PostId'])
print(item['PostId'])
return postId
def get_detail(post_id):
data_list = []
for it in post_id:
url = post_url % (int(time.time()), it)
try:
response = requests.get(url, headers)
except :
print("请求失败!")
continue
if response.status_code == 200:
data = json.loads(response.text)['Data']
data_list += [data]
print(data)
return data_list
def save_to_file(data_list):
df = pd.DataFrame(data_list)
df.to_csv('./result/tencent.csv', index=False, encoding='utf_8_sig')
def spider():
postId = get_url()
save_to_file(get_detail(postId))
if __name__ == '__main__':
spider()
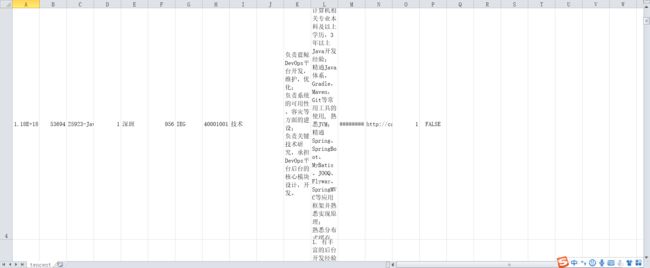
结果展示

总结分析
1、程序的健壮性,记得写 try啊!
2、时间戳的处理,可以用Python的time模块。
虐猫人薛定谔i 2020年2月2日 写于家中