Python3爬虫(4)--抓取考生的四六级成绩
本文主要写的是利用本地的四六级考生的相关信息,我们通过爬虫将这些信息在四六级考试成绩网上进行查询,然后将考生的成绩保存在本地的过程。由于四六级考生的信息不便透露,本文只是提供了一个思路。
我们使用的是中国高等教育学生信息网(http://www.chsi.com.cn/cet/)作为我们查询的相关网站。
我们打开网站之后,看到的如下面的界面
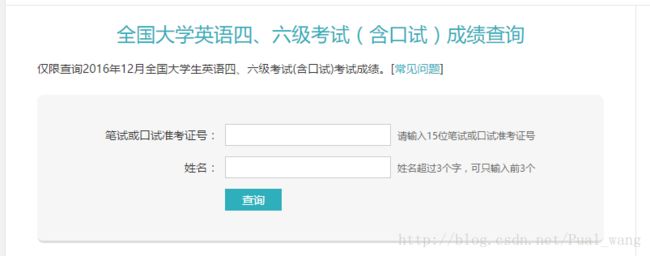
通过这个查询界面,我们可以知道大概要提交的参数,一个是准考证号,另一个是姓名。下面我们先正常的填入准考证号,姓名,进行查询。

我们发现URL是这个样子的
http://www.chsi.com.cn/cet/query?zkzh=510020162100310&xm=XX(XX是汉字)
我们分析这个URL发现zkzh后面的就是准考证号的内容,xm就是姓名,这样的话获取成绩就变的非常的简单了。我们可以直接将Excel文件中获取到的信息处理为字符串,然后和URL拼接在一起,直接对URL进行访问,就可以得到我们想要的数据了。
这里秉着学习的态度,我们从Excel文件中获得准考证号、姓名等信息, 然后在将成绩信息保存到MySQL数据库内,这里用到了两个包,一个是处理Excel文件的xlrd,另一个是mysql-connector。这两个第三方模块都可以在pip install中直接安装。xlrd用法直通车
我们先将需要用到的信息从Excel文件中获取
def collect(self,i):
excel=xlrd.open_workbook('F:\CET\CET.xlsx')
sheet=excel.sheets()[0]
row_data=sheet.row_values(i)
return row_data[5],row_data[6]得到数据之后,我们就可以将这些数据拼接成URL,然后使用requests的get方法获取网页的内容,这里有两种拼接URL的方式,在代码中体现,可以自由选择。requests直通车
def post(self,user_id,user_name):
url='http://www.chsi.com.cn/cet/query?zkzh='+user_id+'&xm='+user_name
r=requests.get(url,headers=self.header)
## r=requests.get('http://www.chsi.com.cn/cet/query',params={'zkzh':user_id,'xm':user_name},headers=self.header)
print(r.url)
return r.text然后就是解析网页的信息,得到我们要得到的信息,这里可以用正则表达式匹配,也可以直接获取内容,看哪个方便
def scrapy(self,data):
soup=bs(data,'html.parser')
links=soup.find_all('td')
# 4 6 8 10 12
n_data=[]
i=4
while i<13:
n_data.append(links[i].get_text().strip())
i=i+2
return n_data得到了我们想要的数据信息,就可以存储到数据库内
def stored(self,data,i,user_id,user_name):
#在这里采用直接将数据插入到数据库内 也可以直接插入到Excel表格中
conn=mysql.connector.connect(user='root',password='',database='spider')
cursor=conn.cursor()
cursor.execute('insert ignore into cet(id,user_name,user_id,zongfen,tingli,yuedu,xiezuo,cet) values(%s,%s,%s,%s,%s,%s,%s,%s)',[i,user_name,user_id,int(data[1]),int(data[2]),int(data[3]),int(data[4]),data[0]])
conn.commit()
cursor.close()
conn.close()在通过调度程序,进行调度就可以完成爬取的内容
def spider_main(self):
i=1
try:
while i<100:
user_id,user_name=self.collect(i)
f=self.post(user_id,user_name)
a=self.scrapy(f)
self.stored(a,i,user_id,user_name)
i=i+1
except Exception as e:
print(e)因为网站有防爬虫机制,一般采用sleepde的方式或者设置ip代理,这里通过在存储过程中加大时间开销,省去了sleep的方法,如果有好的建议,请联系我,谢谢。
最后附上MySQL的SQL语句
create table cet(
id int(10) not null primary key,
user_name varchar(20),
user_id varchar(20),
zongfen int(10),
tingli int(10),
yuedu int(10),
xiezuo int(10),
cet varchar(20)
);到这里爬取四六级成绩的爬虫就完成了,这段代码有很多改进的地方,欢迎大家指正。