数据库中树结构数据,转换为Java对象树结构( 多叉树结构 )
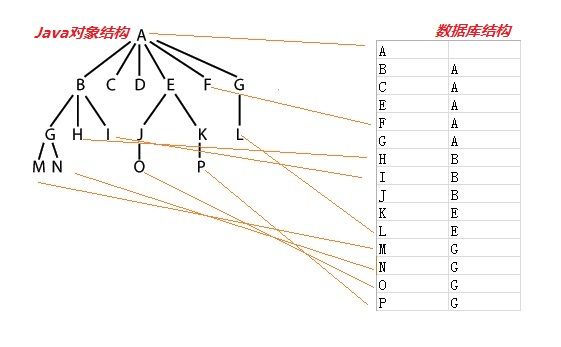
总体就是图所表示所表示的转换,由数据库 => Java对象转换,代码比较简单
提供了两个查询方法:
No.1 : Map<String,List<Tree>> arrMap = queryGroupToMap();//No.1(不推荐使用,运行时间较长)
No.1.1:Map<String, List<Tree>>arrMap=queryListToMap();//No.1.1(推荐使用,运行时间较短)
这个两方法返回的Map内格式是一样的.都是Map<String, List
主要是对象之间建立关联 No.2 : MapForTree(arrMap);
思路为: 用pid(父id)作分组 ,这样每一个组的父节点是同一样,换句话说就是同一分组里,所有节点pid是相同的.这样就针对分组操作,建立两重关联,子节点持有父节点对象,父节点持有子节点List. 就是说通过一个节点可以找得到自己的父节点与子节点
用Map做封装,key为父ID, value为分组List
用到了QueryRunner这个是数据库工具,只要在网上找,下载就可以,能直接查询List.
QueryRunner jar包名=> commons-dbutils-1.5.jar
DTO代码:tree 类的代码.Javabean:
private String AREA_ID; // 主键ID
private String AREA_NAME; // 用来显示的名称
private String PARENT_ID; // 父ID 参照AREA_ID
private Tree parentObj; // 父节点对象
private List childrenList = new ArrayList(); // 子节点
执行代码:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.Set;
import org.apache.commons.dbutils.DbUtils;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ColumnListHandler;
/**
* 数据库中树结构数据,转换为Java对象树结构( 多叉树结构 )
* @author liupengyuan
*
*/
public class ListToTree {
/**
* No.0:
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
long startTime=System.currentTimeMillis(); //获取开始时间
// 从数据库中查询所以分组的节点
// Map> arrMap = queryGroupToMap(); //No.1 (不推荐使用 运行时间较长)
Map> arrMap = queryListToMap(); //No.1.1 (推荐使用 运行时间较短)
// No.2:让节点与子节点之间彼此关联,并返回全有的根.(没有父节点的都为根)
List rootTreeList = MapForTree(arrMap);
// 从map里把根找到.返回List . 可能有多个根
List list = arrMap.get("root");
System.out.println(list.size());
//获取结束时间
long endTime=System.currentTimeMillis();
System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
}
/**
* No.1:
* 通过多条sql查询完成,数据库压力大( 不推荐使用 ).
* 用父ID分组,用Map封装. key为父ID, value是所有父ID为KEY的节点数组.
* 每个数组里都是一组子节点,他们的根是同一个. 换句话说它们的父ID相同, 而Map的Key就是他们是父ID.
* @return
* @throws SQLException
*/
@SuppressWarnings({ "deprecation", "unchecked", "rawtypes" })
public static Map> queryGroupToMap() throws SQLException{
/*
* 该表为中国地区组织,到 区县级
* 比如,中国下分:北京市,河北省,山东省...
* 山东下分:济南市,青岛市,烟台市...
*
*/
// QueryRunner 这个是数据库工具,只要在网上找下载就可以 commons-dbutils-1.5.jar
QueryRunner qr = new QueryRunner();
Connection connection = getJdbcConnection("jdbc:oracle:thin:@192.168.3.34:1521:ORCL", "DSD_ZJK", "DSD_ZJK", "oracle.jdbc.driver.OracleDriver");
/*
* 用父Id分组查询,找到所有的父ID
* 然后循环这个List查询
*/
String sqlGroup = "select parent_id from HM_F_AREA t group by t.parent_id";
List sqlGroupList = (List)qr.query(connection, sqlGroup, new String[]{}, new ColumnListHandler("PARENT_ID"));
Map> arrMap = new HashMap>(sqlGroupList.size());
for(int i=0; i listTree = (List) qr.query(connection, sql, new String[]{} , new BeanListHandler(Tree.class));
arrMap.put( _pid , listTree );
}
DbUtils.close(connection);
return arrMap;
}
/**
* No.1.1:
* 通过两条sql查询完成.数据库压力较小些(推荐使用这个方法,运行的时间比 queryGroupToMap 短一半).
* 用父ID分组,用Map封装. key为父ID, value是所有父ID为KEY的节点数组.
* 每个数组里都是一组子节点,他们的根是同一个. 换句话说它们的父ID相同, 而Map的Key就是他们是父ID.
* @return
* @throws SQLException
*/
@SuppressWarnings({ "unchecked", "deprecation", "rawtypes"})
public static Map> queryListToMap() throws SQLException{
/*
* 该表为中国地区组织,到 区县级
* 比如,中国下分:北京市,河北省,山东省...
* 山东下分:济南市,青岛市,烟台市...
*
*/
// QueryRunner 这个是数据库工具,只要在网上找下载就可以 commons-dbutils-1.5.jar
QueryRunner qr = new QueryRunner();
Connection connection = getJdbcConnection("jdbc:oracle:thin:@192.168.3.34:1521:ORCL", "DSD_ZJK", "DSD_ZJK", "oracle.jdbc.driver.OracleDriver");
//用父Id分组查询,找到所有的父ID然后循环这个List查询
String sqlGroup = "select parent_id from HM_F_AREA t group by t.parent_id";
List sqlGroupList = (List)qr.query(connection, sqlGroup, new String[]{}, new ColumnListHandler("PARENT_ID"));
//查询出所有的节点
Map> arrMap = new HashMap>(sqlGroupList.size());
String sql = "select area_id , area_name , parent_id from HM_F_AREA t ";
List listTree = (List) qr.query(connection, sql, new String[]{} , new BeanListHandler(Tree.class));
DbUtils.close(connection);
/*
* 通过 父ID 和 所有的节点 比对
*/
for(int k=0;k tempTreeList = new ArrayList();
for(int i=0; i < listTree.size();i++){
Tree tree = listTree.get(i);
/*
* 将同一父ID的tree添加到同一个List中,最后将List放入Map.. arrMap.put(pid, tempTreeList);
* 这点虽然不复杂,但这是整个思索的中心,
*/
if(pid.equals(tree.getPARENT_ID())){
tempTreeList.add(tree);
}
}
// 最后将List放入Map.. key就是这组List父ID, value就是这组List
arrMap.put(pid, tempTreeList);
}
return arrMap;
}
/**
* No.2:
* 让节点与子节点之间彼此关联,并返回树的根
* 数据库格式并没有换,只是建立了关联
* @param arrMap
*/
public static List MapForTree(Map> arrMap){
//所以pid的集成
Set pidSet = arrMap.keySet();
//遍历所有的父ID,然后与所以的节点比对,父id与id相同的 //找出对应的tree节点,然后将该节点的
for (Iterator it = pidSet.iterator(); it.hasNext();) {
String pid = (String) it.next();
/*
* 按分组的方式与pid比对.
* 如果找到,那么将该pid分组的List,做为子节点 赋值给该找到的节点的 setChildrenList(list),同时也将找到节点赋值List内所有子节点的parentObj
*
*/
for (Iterator it2 = pidSet.iterator(); it2.hasNext();) {
String key = (String) it2.next();
//不查找自己的分组
if(pid.equals(key)){
// break;
}
List list = arrMap.get(key);
// No.3:找出对应的tree父节点对象
Tree parentTree = indexOfList(list , pid);
if(parentTree!=null){
//通过pid在Map里找出节点的子节点.
if("430000".equals(pid)){
System.out.println(pid);
}
List childrenHereList = arrMap.get(pid);
//TODO 这里是我自己定义的变成成,都不一样.所以需要自定义
// 把子节点List赋值给Tree节点的Children
parentTree.setChildrenList(childrenHereList);
//TODO 这里是我自己定义的变是,都不一样.所以需要自定义
// 与上面相反,这是 把父节点对象赋值给Tree节点的parentObj
for(int i=0; i rootTreeList = new ArrayList();
for (Iterator it2 = pidSet.iterator(); it2.hasNext();) {
String key = (String) it2.next();
List list = arrMap.get(key);
for(int i=0; i list , String pid){
for(int i=0 ;i