Python 美团商户信息
爬取的思路:
找到你要爬取的网站,例如https://sz.meituan.com/meishi/(这次爬取的目标网址)
分析此网页是动态还是静态(动静态网页此处就不多说明,不懂得同学们可以百度了解一下)
如果网页是静态,则可以直接请求回来,再用相应的解析库进行解析,获取你想要的数据;如果网页时动态的,可以考虑使用抓包方法或者Selenium模拟浏览器去抓取网页(大杀器,不过性能方面会比较慢,慎用把)
在获取到想要的数据后,再进行结构化的存储操作
明确爬取网站(https://sz.meituan.com/meishi/)
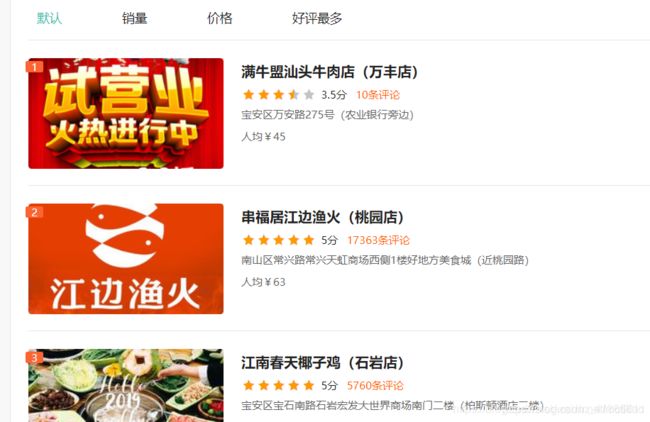
打开之后你会发现网站长这样,接着点击右键"查看源代码",

看到了想要的数据"满牛盟汕头牛肉店",此时使用杀器正则表达式,将其匹配下来
import requests
import re
url='https://sz.meituan.com/meishi/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
response=requests.get(url,headers=headers)
shopname=re.findall(r'"frontImg".*?title":(.*?),',response.text)
以此类推,同样的方法将所需要的其它数据一起弄下来,依次是店铺评分(avgScore)、评论个数(allCommentNum)、地址(address)、人均消费(avgPrice)、对应的urlid(urlid,此处是为了后面的二级爬取,进入此商铺连接获取联系方式(phone)以及营业时间(openTime))
完整的获取数据部份的代码如下
import requests
import json
import re
def one_level(url,headers):
meishi_dict={}
response=requests.get(url,headers=headers)
html=etree.HTML(response.text)
avgScore=re.findall(r'"avgScore":(.*?),',response.text)
shopname=re.findall(r'"frontImg".*?title":(.*?),',response.text)
allCommentNum=re.findall(r'"allCommentNum":(\d+),',response.text)
address=re.findall(r'"address":(.*?),',response.text)
avgPrice=re.findall(r'"avgPrice":(\d+),',response.text)
urlid=re.findall(r'"poiId":(\d+),',response.text)
two_url=[]
for k in urlid:
a='https://www.meituan.com/meishi/'+str(k)+'/'
two_url.append(a)
meishi_all_list=[]
for i in range(len(shopname)):
meishi_list=[]
meishi_list.append(shopname[i])
meishi_list.append(avgScore[i])
meishi_list.append(allCommentNum[i])
meishi_list.append(address[i])
meishi_list.append(avgPrice[i])
meishi_list.append(two_url[i])
#meishi_dict.setdefault(shopname[i],meishi_list)
meishi_all_list.append(meishi_list)
return meishi_all_list,two_url
def two_level(meishi_all_list,two_url,headers):
for i in meishi_all_list:
new_url=i[5]
response=requests.get(new_url,headers=headers)
phone=re.findall(r'"phone":(.*?),',str(response.text))
openTime=re.findall(r'"openTime":(.*?),',str(response.text))
i.append(phone)
i.append(openTime)
writer_to_file(meishi_all_list)
return meishi_all_list
接着获取完所需数据之后,得将其结构化存储,此处采用了csv库里面的write.writerows方法
def writer_to_file(meishi_all_list):
with open('a.csv','a',newline='',encoding='utf-8')as f:
write=csv.writer(f)
write.writerows(meishi_all_list)
完整的思路过程也就差不多这样啦,接下来给大家附上完整的代码:
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 20 00:50:47 2019
@author: HHX
"""
import csv
import requests
import json
import re
def one_level(url,headers):
meishi_dict={}
response=requests.get(url,headers=headers)
avgScore=re.findall(r'"avgScore":(.*?),',response.text)
shopname=re.findall(r'"frontImg".*?title":(.*?),',response.text)
allCommentNum=re.findall(r'"allCommentNum":(\d+),',response.text)
address=re.findall(r'"address":(.*?),',response.text)
avgPrice=re.findall(r'"avgPrice":(\d+),',response.text)
urlid=re.findall(r'"poiId":(\d+),',response.text)
two_url=[]
for k in urlid:
a='https://www.meituan.com/meishi/'+str(k)+'/'
two_url.append(a)
meishi_all_list=[]
for i in range(len(shopname)):
meishi_list=[]
meishi_list.append(shopname[i])
meishi_list.append(avgScore[i])
meishi_list.append(allCommentNum[i])
meishi_list.append(address[i])
meishi_list.append(avgPrice[i])
meishi_list.append(two_url[i])
meishi_all_list.append(meishi_list)
return meishi_all_list,two_url
def two_level(meishi_all_list,two_url,headers):
for i in meishi_all_list:
new_url=i[5]
response=requests.get(new_url,headers=headers)
phone=re.findall(r'"phone":(.*?),',str(response.text))
openTime=re.findall(r'"openTime":(.*?),',str(response.text))
i.append(phone)
i.append(openTime)
writer_to_file(meishi_all_list)
return meishi_all_list
def writer_to_file(meishi_all_list):
with open('food.csv','a',newline='',encoding='utf-8')as f:
write=csv.writer(f)
write.writerows(meishi_all_list)
def main():
for i in range(1,5):
url='https://sz.meituan.com/meishi/pn' + str(i) + '/'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
#为了保险起见,同学们可以在headers里面添加自已的cookie
a,b=one_level(url,headers)
two_level(a,b,headers)
if __name__=='__main__':
main()
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 20 00:50:47 2019
@author: HHX
"""
import csv
import requests
import json
import re
def one_level(url, headers):
meishi_dict = {}
response = requests.get(url, headers=headers)
avgScore = re.findall(r'"avgScore":(.*?),', response.text)
shopname = re.findall(r'"frontImg".*?title":(.*?),', response.text)
allCommentNum = re.findall(r'"allCommentNum":(\d+),', response.text)
address = re.findall(r'"address":(.*?),', response.text)
avgPrice = re.findall(r'"avgPrice":(\d+),', response.text)
urlid = re.findall(r'"poiId":(\d+),', response.text)
two_url = []
print("商户名称:",shopname)
for k in urlid:
a = 'https://www.meituan.com/meishi/' + str(k) + '/'
two_url.append(a)
meishi_all_list = []
for i in range(len(shopname)):
meishi_list = []
meishi_list.append(shopname[i])
meishi_list.append(avgScore[i])
meishi_list.append(allCommentNum[i])
meishi_list.append(address[i])
meishi_list.append(avgPrice[i])
meishi_list.append(two_url[i])
meishi_all_list.append(meishi_list)
return meishi_all_list, two_url
def two_level(meishi_all_list, two_url, headers):
for i in meishi_all_list:
new_url = i[5]
response = requests.get(new_url, headers=headers)
phone = re.findall(r'"phone":(.*?),', str(response.text))
openTime = re.findall(r'"openTime":(.*?),', str(response.text))
i.append(phone)
i.append(openTime)
print("Phone:",phone)
writer_to_file(meishi_all_list)
return meishi_all_list
def writer_to_file(meishi_all_list):
with open('food.csv', 'a', newline='', encoding='utf-8')as f:
write = csv.writer(f)
write.writerows(meishi_all_list)
def main():
# 在美团上查询该城市的商户一共有多少页,修改下面的值即可
for i in range(1, 20):
url = 'https://ts.meituan.com/meishi/pn' + str(i) + '/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
# 为了保险起见,同学们可以在headers里面添加自已的cookie
a, b = one_level(url, headers)
two_level(a, b, headers)
if __name__ == '__main__':
main()
如果运行后,在food.csv中如果没有商户的电话号码信息,可以尝试下面的方法。
提示:美团网站 用户登录,登录后,运行程序,在food.csv文件中找到某个商户的信息地址,例如:https://www.meituan.com/meishi/94057020/
在浏览器中打开该地址,查看一下是否需要输入验证码,如果需要就正确输入后再运行程序,这样可以获取到商户的电话号码。