基于centos7的hadoop完全分布式搭建
虚拟机安装
[添加链接描述](https://www.cnblogs.com/Neeo/p/8711201.html)
更改主机名
hostnamectl set-hostname master
(在root下)
下载两个文件
yum install ntp
yum install net-tools
下载的时候出现 。。。。锁定状态睡眠中
rm -f /var/run/yum.pid
找到ens33的ip
ifconfig
使用xftp向虚拟机传输文件
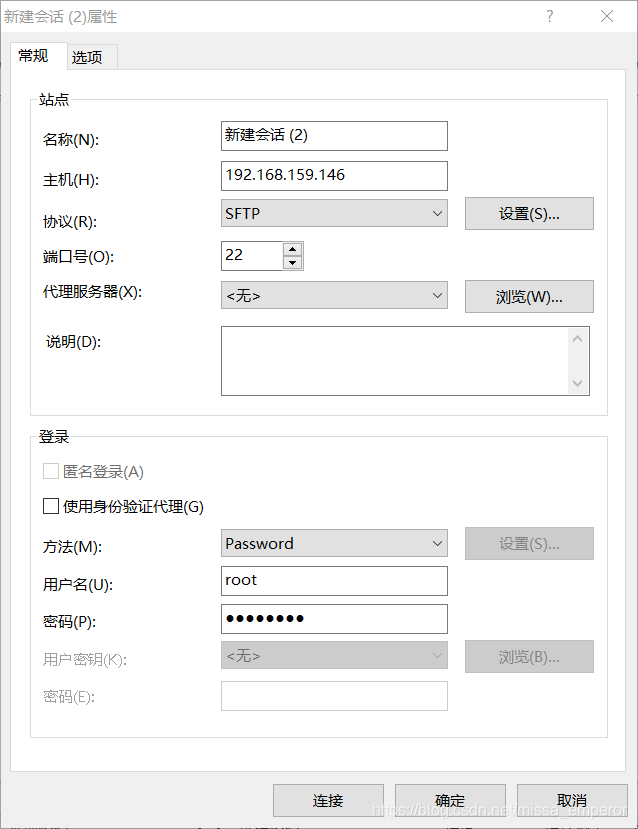
用户名必须为root,否则虚拟机不允许远程连接root
密码为创建虚拟机时设的root密码
名称随意
主机为通过ifconfig查得的ens33的ip地址
传一波文件

自建个bigdata文件夹方便之后解压的时候寻找
为了方便可以取消虚拟机的自动锁屏
进入虚拟机----左上角应用程序—系统工具—设置-----锁屏-----关
看看文件是否导入进来
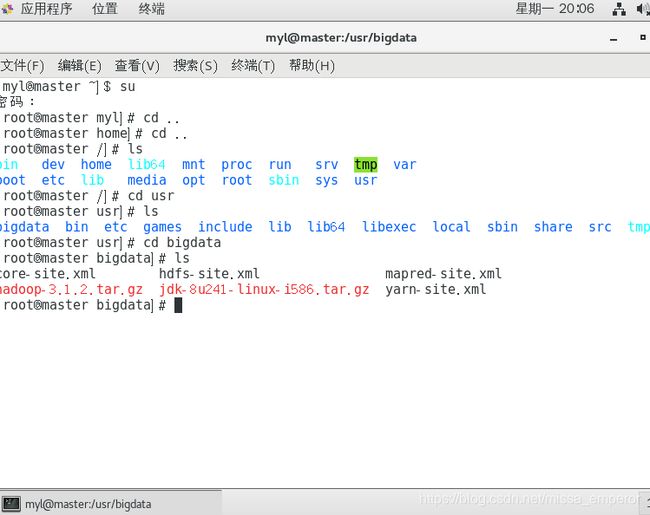
开始解压(为了方便,分别创建jdk和hadoop两个文件夹,把他们解压到里面)
tar -zxvf jdk-8u241-linux-i586.tar.gz -C /usr/jdk
tar -zxvf hadoop-3.1.2.tar.gz -C /usr/hadoop
vi /etc/sysconfig/network
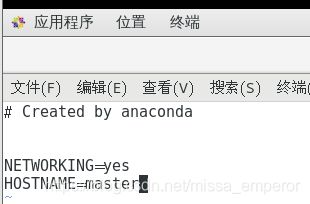
开始克隆虚拟机
完整克隆
三台虚拟机一起启动
通过xshell实现外部连接


改名、实现时间同步(三台机器)
hostnamectl set-hostname slave1
tzselect #(5-9-1-1)
关键注意的问题(关闭防火墙)
当其状态是 dead 时,即防火墙关闭。
关闭防火墙:systemctl stop firewalld
永久关闭防火墙 : systemctl disable firewalld
查看状态:systemctl status firewalld
建议永久关闭省事
hosts文件配置(三台机器)映射
vi /etc/hosts

master 作为 ntp 服务器,修改 ntp 配置文件。(master 上执行)
vi /etc/ntp.conf
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10 #stratum 设置为其它值也是可以的,其范围为 0~15
重启ntp服务(master)
/bin/systemctl restart ntpd.service
到slave1和slave2上同步
ntpdate master

证明正常
ssh免密(重要一定要仔细步骤不能错)
(1)每个结点分别产生公私密钥:
ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa(三台机器)
秘钥产生目录在用户主目录下的.ssh 目录中,进入相应目录查看:
cd .ssh/

(2)Id_dsa.pub 为公钥,id_dsa 为私钥,紧接着将公钥文件复制成 authorized_keys 文 件:(仅 master)
e(注意在.ssh/路径下操作)

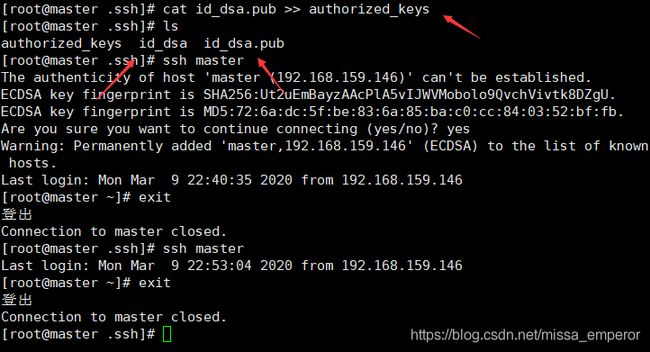
ssh master 是为了做一个回环
把公匙包装成授权钥匙
第一次会要一个验证
(3)让主结点 master 能通过 SSH 免密码登录两个子结点 slave。(slave 中操作)
为了实现这个功能,两个 slave 结点的公钥文件中必须要包含主结点的公钥信息,这样
当 master 就可以顺利安全地访问这两个 slave 结点了。
slave1 结点通过 scp 命令远程登录 master 结点,并复制 master 的公钥文件到当前的目录
下,且重命名为 master_das.pub,这一过程需要密码验证。
scp master:~/.ssh/id_dsa.pub ./master_das.pub(注意在.ssh/路径下操作)

将 master 结点的公钥文件追加至 authorized_keys 文件:
cat master_das.pub >> authorized_keys(注意在.ssh/路径下操作)!!!!


免密就做完了
安装jdk
配置环境变量(三台机器)
vi /etc/profile
添加内容:
export JAVA_HOME=/usr/java/jdk1.8.0_241
export CLASSPATH=$JAVA_HOME/lib/export
export PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
~
生效环境变量:source /etc/profile
安装hadoop
vi /etc/profile
添加内容
export HADOOP_HOME=/usr/hadoop/hadoop-3.1.2
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin
配置core-site.xml
配置hadoop-env.sh
配置里面的java-home=找jdk的那个位置
添加内容:
export JAVA_HOME=/usr/java/jdk1.8.0_241
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
配置core-site.xml yarn-site.xml hdfs-site.xml mapred-site.xml
cp /usr/bigdata/yarn-site.xml /usr/hadoop/hadoop-3.1.2/etc/hadoop/

同理将这4个文件都复制到hadoop所在文件中

把配置好的hadoop发送给其他机器
scp -r /usr/hadoop root@slave1:/usr/
scp -r /usr/hadoop root@slave2:/usr/
分发jdk
scp -r /usr/jdk root@slave1:/usr/
scp -r /usr/jdk root@slave2:/usr/
格式化namenode
hadoop namenode -format
可能会出现点小插曲

解决方法:在所有节点上 sudo yum install glibc.i686 通过java -version可以检查一下是否成功
再格式化就成了

重启节点
sbin/start-all.sh
![]()
可能会出错

在三台机器上对Hadoop文件夹下的sbin里的start-dfs.sh、stop-dfs.sh、start-yarn.sh、stop-yarn.sh进行配置
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
重启节点即可
再浏览器输入自己master的IP+:50070
