Zeppelin安装教程
我是在虚拟机中安装
虚拟机:virtualbox
系统:centos7
jdk1.7
zeppelin0.6.2
spark-2.0.2-bin-hadoop2.7
hadoop-2.7.3
scala-2.11.8
R-3.3.2
1.安装jdk
1.1.下载jdk,从官网下载linux版本的jdk
1.2.新建文件夹
sudo mkdir /jdk
1.3.将jdk压缩包放到jdk目录下面,可以复制过去
1.4.将压缩包解压
tar zxvf jdk-7u76-linux-x64.tar.gz1.5.设置jdk环境变量
vi /etc/profile在文件中输入
export JAVA_HOME=/jdk/jdk1.7.0_76 export JRE_HOME=/jdk/jdk1.7.0_76/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin: $PATH输入完后 按Esc 输入 :wq! 退出vi编辑器
source /etc/profile
java -version
2.安装scala-2.11.8 (安装spark-2.0.2-bin-hadoop2.7 对应的scala版本是scala-2.11.8,为避免以后出扫描问题,这里安装对应的)
2.1新建文件夹
sudo mkdir /tools
2.2将压缩包拷贝到tools文件夹下, 在文件夹下解压scala
拷贝命令 cp scala-2.11.8 /tools
解压:tar -zvxf scala-2.11.82.3 配置环境变量
tar -zvxf scala-2.11.8
vim /etc/profile配置文件输入内容:
export SCALA_HOME=/tools/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
运行配置文件source /etc/profile验证 显示版本信息
scala -version
启动scala
scala
3.安装spark-2.0.2-bin-hadoop2.7
3.1将压缩包拷贝到tools文件夹下, 在文件夹下解压spark
拷贝命令 cp spark-2.0.2-bin-hadoop2.7 /tools
解压:tar -zvxf spark-2.0.2-bin-hadoop2.73.2配置spark环境变量
export SPARK_HOME=/tools/spark-2.0.2-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin
3.3修改spark配置
进入spark-2.0.2-bin-hadoop2.7/confruguo
复制模板文件:
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
3.4编辑spark-env.sh
添加上你的对应信息:
export JAVA_HOME=/jdk/jdk1.7.0_76
export SCALA_HOME=/tools/scala-2.11.8
export SPARK_MASTER_IP=192.168.199.232
export SPARK_WORKER_MEMORY=2g
export HADOOP_CONF_DIR=/tools/spark-2.0.2-bin-hadoop2.7/conf
3.5编辑slaves
添加上你的对应信息,所有的集群的机器:(单机可不用添加)
192.168.199.233
进入spark-2.0.2-bin-hadoop2.7/sbin/目录
执行:./start-all.sh
浏览器查群信息
master地址+8080端口
启动Running Applications
在bin目录下执行:
MASTER=spark://192.168.199.232:7077 ./spark-shell
参考spark 安装教程链接:
http://jingyan.baidu.com/article/7e440953308f122fc0e2ef81.html
4.安装zeppelin
4.1我这里安装的是二进制,从官网下载的最新版zeppelin0.6.2,如果想从源代码安装,请自行百度查询。
官方网站地址:
http://zeppelin.apache.org/download.html
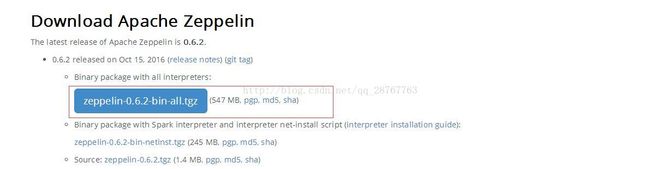
4.2下载好的包放到tools/文件夹下并且解压
解压之后打开配置文件
cd /tools/zeppelin-0.6.2-bin-all/conf
4.3将 zeppelin-env.sh.template 和zeppelin-site.xml.template 重命名成 zeppelin-env.sh 和zeppelin-site.xml
mv zeppelin-env.sh.template zeppelin-env.sh
mv zeppelin-site.xml.template zeppelin-site.xml
**这里有一步比较注意,之前在运行过程中总是出现链接拒绝的问题(头疼了三天),后来经过这种方法修复了,自己也不太清楚这个到底什么原因,不过这一步最好做一下
将解压的文件夹中的bin目录 以及bin目录下的所有文件全部 chmod 777 赋予权限**
4.4打开zeppelin-env.sh
vim zeppelin-env.sh
添加以下:
export JAVA_HOME= /jdk/jdk1.7.0_76export SPARK_HOME=/tools/spark-2.0.2-bin-hadoop2.7
打开zeppelin-site.xml
vim zeppelin-site.xml

4.5 运行zeppelin
在 解压的zeppelin下的bin目录下
运行:./zeppelin-daemon.sh start
重启:./zeppelin-daemon.sh restart
关闭:./zeppelin-daemon.sh stop
4.6 在浏览器运行,地址:端口

我这里是在浏览器中输入 192.168.199.232:8082 域名是我自己本地IP地址,如果本机访问可以是127.0.0.1
4.7 运行pgsql命令

如图,点击右上角(刚开始安装显示的是默认用户anonymous)我这里是设置为自己登录的用户(下面会讲到)

如上图,按照自己的环境进行配置地址,端口,用户名等等,由于zeppelin中默认自带的是pgsql,我这里介绍一下,由于大家很多再用mysql,mysql的设置下面会讲到
配置成功之后就开始运行吧。

创建一个新的Notebook,输入名字确定
输入%jdbc和sql语句点击右上角FINISHED就可以运行了。
5.zepppelin配置mysql
zeppelin 默认的数据库是pgsql,常用的mysql较多一点,在这里就讲一下zeppelin配置mysql
5.1从github上下载代码
(需要在服务器上安装git 和maven)
git clone https://github.com/jiekechoo/zeppelin-interpreter-mysql
mvn clean package假如你的zeppelin安装在 /tools/zeppelin-0.6.2-bin-all目录
mkdir /tools/zeppelin-0.6.2-bin-all/interpreter/mysql
cp target/zeppelin-mysql-0.5.0-incubating.jar /opt/zeppelin/interpreter/mysql拷贝mysql需要的jar包到interpreter目录
cp mysql-connector-java-5.1.6.jar log4j-1.2.17.jar slf4j-api-1.7.10.jar slf4j-log4j12-1.7.10.jar commons-exec-1.1.jar /tools/zeppelin-0.6.2-bin-all/interpreter/mysql
5.3修改zeppelin配置文件vi conf/zeppelin-site.xml在zeppelin.interpreters 的value里增加一些内容 ,org.apache.zeppelin.mysql.MysqlInterpreter
5.4重启zeppelin即可
bin/zeppelin-daemon.sh restart
5.5运行MySQL代码,加载mysql interpreter
登录管理界面,Interpreter -> Create, 类似下面的页面,完成点击 Save

5.6创建 Notebook,完成你的可视化
点击右上角的setting,并且确保mysql被选中,保存Save

5.7输入你要执行的SQL语句,相信你再熟悉不过了
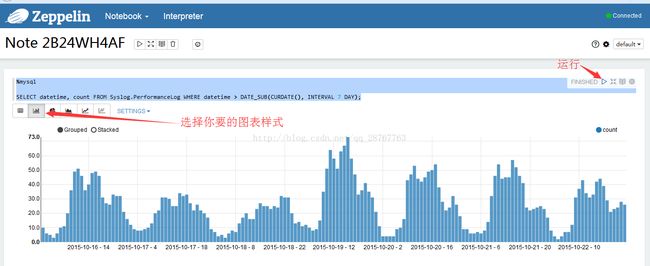
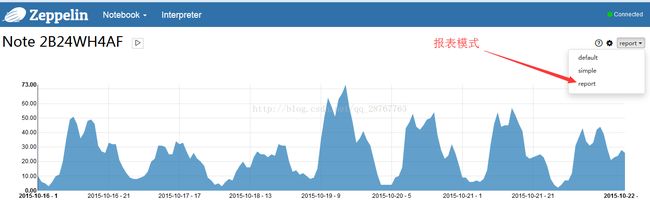
可以做成报表模式,更好看更爽了
引用链接:http://www.ithao123.cn/content-10531523.html
6.配置用户名密码访问登录
Apache Zeppelin启动默认是匿名(anonymous)模式登录的,也就是任何人都可以访问,这个可以在/zeppelin/conf下的zeppelin-site.xml中看到:
-
zeppelin.anonymous.allowed -
true -
Anonymous user allowed by default
- 修改/zeppelin/conf/zeppelin-site.xml文件选项zeppelin.anonymous.allowed的value为false,表示不允许匿名访问:
-
zeppelin.anonymous.allowed -
true -
Anonymous user allowed by default
- 修改/zeppelin/conf/shiro.ini文件,显然zeppelin采用了shiro作为他的验证登录权限控制框架,那么我们需要对shiro有一些了解,我们去看该文件的最后几行:
- [urls]
- # anon means the access is anonymous.
- # authcBasic means Basic Auth Security
- # authc means Form based Auth Security
- # To enfore security, comment the line below and uncomment the next one
- /api/version = anon
- /** = anon
- #/** = authc

- [users]
- # List of users with their password allowed to access Zeppelin.
- # To use a different strategy (LDAP / Database / ...) check the shiro doc at http://shiro.apache.org/configuration.html#Configuratio
- n-INISections
- admin = password1
- user1 = password2, role1, role2
- user2 = password3, role3
- user3 = password4, role2
