python可视化——词云
1.引言
这篇博客总结可视化中词云的绘制,并且介绍其中几处细节。上篇知识图谱实体定义中,我们指出有"自顶向下"、"自底向上"两种策略,在本章,我们从数据底层出发,研究《毛选》中的词语分布。本文采用jieba获取关键词并绘制成词云。

2.词云绘制的基本流程
直接上代码分析
import jieba # 分词库
from wordcloud import WordCloud # 词云库
import matplotlib.pyplot as plt # 图像展示库,以便在notebook中显示图片
from pyquery import PyQuery # 爬虫中用于数据处理的库,在本文用于去除HTML标签
# 整个过程分三步走
#第一步,获取关键词
# 创建停用词list
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 对句子去除停用词
def movestopwords(sentence,stop_list):
stopwords = stopwordslist(stop_list) # 这里加载停用词的路径
santi_words =[x for x in sentence if len(x) >1 and x not in stopwords]
return santi_words
def run_word_cloud(my_content,my_stop_list,user_words,font_path,background_path,img_to_save_path):
jieba.load_userdict(user_words) # 加载外部 用户词典
santi_text = open(my_content, 'r', encoding='utf-8').read() # 读取本地文档
words = jieba.cut(PyQuery(santi_text).text()) #去除HTML标签
word_list = movestopwords(words,my_stop_list) # 去除停用词
words_split = " ".join(word_list) #列表解析为字符串
# 以上内容是第一个步骤中的获取关键词步骤,如果想简单解决,也可以不去除停用词,直接按以下两句即可获取关键词,但是这种方式有太多杂质,所以不推荐
#f = open(path_txt,'r',encoding='UTF-8').read()
#cut_text = " ".join(jieba.cut(f))
#第二步,设置词云的显示格式
wc = WordCloud(
width=800,
height=800,
background_color="white", # 设置背景颜色
max_words=100, # 词的最大数(默认为200)
max_font_size=400, # 最大字体尺寸
min_font_size=10, # 最小字体尺寸(默认为4)
random_state=42, # 设置有多少种随机生成状态,即有多少种配色方案
mask=plt.imread(background_path), # 读取遮罩图片!!
contour_width=3, # 轮廓宽窄度
contour_color="steelblue",# 轮廓的颜色,默认为黑色
font_path=font_path,
collocations = False#默认为True,False表示不显示重复的关键词
)
#第三步,显示词云并保存
my_wordcloud = wc.generate(words_split) #按词频生成词云
plt.imshow(my_wordcloud) #展示词云
plt.axis("off") #去除横纵轴
plt.show()#弹出式显示,如果是批量生成词云,建议去除。
wc.to_file(img_to_save_path) # 保存图片文件
# 最后的是为方便用户使用,把需要设置的路径集成在这里,读者使用该代码只需要下载好相应的库、并修改一下的路径即可
if __name__ == '__main__':
# 设置需要改变的路径参数
# 文档路径,存放需要
my_content = "data/jieji.txt"
# 停词表,例如:的、了、我、你、我们等虚词、标点符号等
my_stop_list = "stop.txt"
# 自定义词表,例如不想过滤掉的词,例如专业名词、特定的名字,例如网名"廾匸轻踩不刀"
user_words = "dict.txt"
# 字体路径,在C盘字体的路径下
font_path = "C:/Windows/Fonts/simsun.ttc"
# 背景图片路径,图片一般设置成白底黑框的,黑色是显示的内容,也比较清晰
background_path = "imgs/tuzi1.jpg"
img_to_save_path = "my_imgs/jieji.jpg"
run_word_cloud(my_content,
my_stop_list,
user_words,
font_path,
background_path,
img_to_save_path)在上述的代码中,比较简单的过程就是分三步:
第一步,得到关键词:用分词工具将文本分成关键词,这里可以添加一些附加的内容,例如去除停用词、加载用户自定义词表。
第二步,设置词云的显示格式。该步骤主要是一些字体、背景颜色的设置。值得注意的是cllocations = False一定要添加这个参数,如果没有这一行,或者是cllocations = True,最后显示图云会有重复显示,如下图:
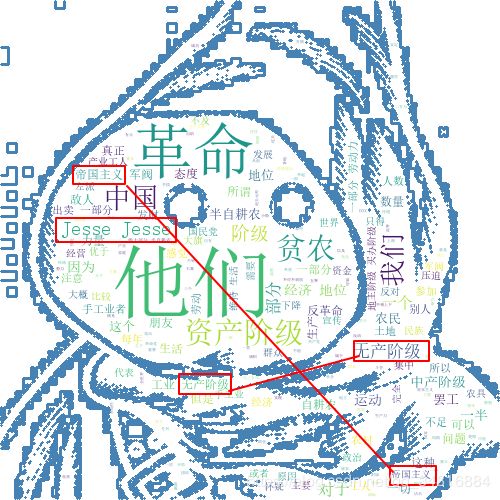
在上述图片中没有添加cllocations = False就有这种重复显示的问题。
第三步,显示词云并保存
这里需要注意的是 plt.show()这一行,通常如果想批量保存生成的词云,可以去掉这一行,这一行主要功能是在IDE中即时显示运行完的词云,批量的话会占用资源,还可能报错(需要手动关闭图片才能下一步保存),因此这一行在批量生成时删除。
3.毛选中的词云图
-
阶级分析

-
矛盾论

-
实践论

-
毛选全文


4.关键词抽取代码
import jieba.analyse
def main():
words = jieba.cut(PyQuery(santi_text).text()) #去除HTML标签
word_list = movestopwords(words) # 去除停用词
words_split = " ".join(word_list) #列表解析为字符串
print('以下是tf-tdf算法-------------------------------------------------')
keywords_tf = jieba.analyse.extract_tags(words_split, topK=100, withWeight=True,allowPOS=('ns', 'n', 'vn', 'v')) # tf-tdf算法
for item in keywords_tf:
print(item[0],item[1])
print('以下是textrank算法-------------------------------------------------')
keywords_rank = jieba.analyse.textrank(words_split, topK=100, withWeight=True,allowPOS=('ns', 'n', 'vn', 'v')) #textrank算法
for item in keywords_rank:
print(item[0],item[1])
print('以下是纯词频统计-------------------------------------------------')
mycount = Counter(word_list) # 统计词频
for key, val in mycount.most_common(100): # 有序(返回前10个)
print(key, val)
上述的是三种关键词抽取的常规方法,在本文中使用的是jieba分词,jieba中使用的是tf-idf算法。以下是jieba、textrank、词频抽取关键词的结果:

从图中可以看出,利用基础的tf-idf、textrank等方式抽取的关键词还很简陋,如果想在专业领域抽取出关键词,还得找更多特征或者性能更好的算法。
5.结语
本章内容承接上几篇知识图谱可视化的内容,将词云制作划分成三个步骤,最后分析了词云中的关键环节"关键词抽取",要想获得专业领域的关键词,仅仅靠基础的工具是不够的,需要用到一定的算法,在下节,拟介绍利用CRF抽取关键词、实体。