使用pandas中concat进行数据整合
这节主要学习:学习如何利用pandas中的整合多个DataFrame或者Series中的数据。
Concat
知识要点
1:concat解决的是对数据进行合并的问题
2:concat()方法的格式
pd.concat(objs, axis=0, join='outer', ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
注:
bjs:列表对象,待合并的DataFrame或者Series,可以包含两个或者两个以上的对象。
axis:用来指定按行(上下拼)还是按列(左右拼)合并,默认按照行进行合并。如果需要按照列进行合并,需要指定参数axis=1
join:确定合并时候记录的匹配方法,后面介绍按列进行合并的时候会专门展开。
前提条件:准备多份数据文件
示例代码如下:
#城市
#引入pandas模块
import pandas as pd
#通过列表存储每个城市的基本信息
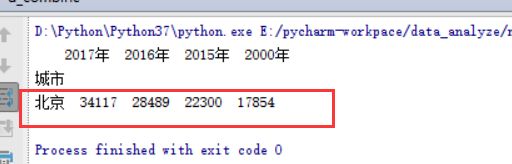
emp1001=['北京',34117,28489,22300,18499,17854]
emp1002=['天津',15139,12870,9931,8828,8390]
emp1003=['深圳',9738,7354,7798,5562,4943]
emp1004=['广州',8827,7348,7303,7155,6668]
emp1005=['海口',5662,5196,4946,5153,4631]
emp1006=['成都',7944,6838,6416,5865,6074]
emp_list=[emp1001,emp1002,emp1003,emp1004,emp1005,emp1006]
# 设定列索引
columns_value=['城市','2017年','2016年','2015年','2014年','2000年']
# 创建表格
df=pd.DataFrame(emp_list,columns=columns_value)
# # 数据保存的地址
csv_file = 'E:/pycharm-workpace/data_analyze/num08/city_data.csv'
print('output:',csv_file)
# 将内容存入到CSV文件
df.to_csv(csv_file)
# 打印刚刚构造的DataFrame
print(df)
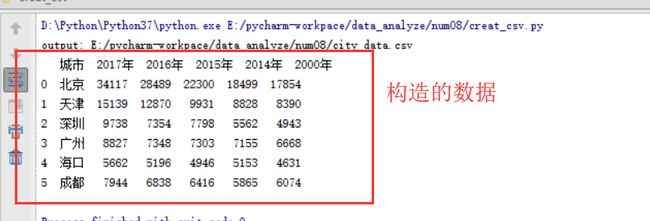
按行进行合并
#按行合并
# 整体思路
# 根据df构造了两个DataFrame变量df1和df2,df的前2行为df1,第3到第4行为df2,
# 接着通过concat()方法合并df1和df2,最终结果放到df3中
示例代码如下:
#读取文件
import pandas as pd
# 文件地址
csv_file = 'E:/pycharm-workpace/data_analyze/num08/city_data.csv'
df=pd.read_csv(csv_file,index_col='城市')
#构造2个DataFrame,分别读取文件的0到2行,和第3到4行。
df1=df[0:2]
df2=df[3:4]
#TODO
#合并2个DataFrame
df3=pd.concat([df1,df2])
print(df3)
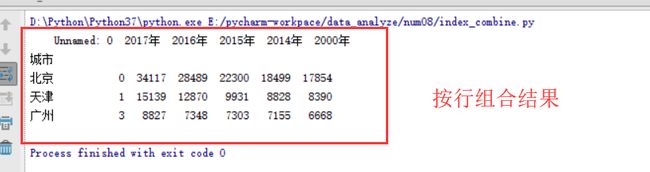
按列进行合并
#按列合并
# 整体思路
# 根据df构造了两个DataFrame变量df1和df2,df的前2行为df1,第3到第4行为df2,
# 接着通过concat()方法合并df1和df2,最终结果放到df3中
#读取文件
import pandas as pd
# 文件地址
csv_file = 'E:/pycharm-workpace/data_analyze/num08/city_data.csv'
df=pd.read_csv(csv_file,index_col='城市')
#构造2个DataFrame,df1包含2017,2016,2015的数据,df2包含2014年、2013年、2012年的数据
df1=df.loc[:,['2017年','2000年']]
df2=df.loc[:,['2016年','2015年']]
#TODO
#合并2个DataFrame
df3=pd.concat([df1,df2],axis=1)
print(df3)
索引值的匹配方式
#默认匹配方式
# 整体思路:
# 读取的文件分别构造了两个DataFrame,以城市字段作为结果的行索引。
# df1包含了北京和上海两个城市2017和2016年的房价数据,
# df2包括了北京和成都两个城市2000和2015年的数据,
# 只有北京这个城市的数据在两个DataFrame中都存在
import pandas as pd
# 文件地址
csv_file = 'E:/pycharm-workpace/data_analyze/num08/city_data.csv'
df=pd.read_csv(csv_file,index_col='城市')
#构造2个DataFrame df1 df2
df1=df[['2017年','2016年']].loc[['北京','成都']]
df2=df[['2015年','2000年']].loc[['北京','深圳']]
#按列进行合并
df4=pd.concat([df1,df2],axis=1)
print(df4)
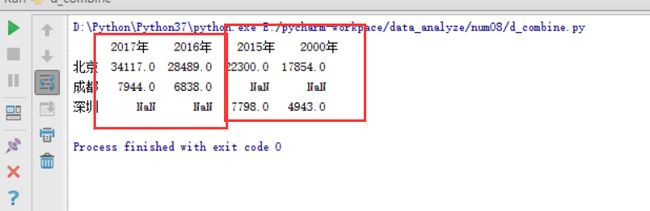
内连接方式匹配:
#按列进行合并,行索引取df1 df2的交集
df5=pd.concat([df1,df2],axis=1,join='inner')
print(df5)