程序设计语言与语言处理程序基础
编译与解释
编译过程
Ⅰ、类型:
解释型:编一行,执行一行,告诉结果/错误
编译型:全写完,形成相关程序
Ⅱ、过程源程序
①源程序
②词法分析:正规式,有限自动机,分析你的关键词是否出错
③语法分析:根据语言语法规则
④语义分析:语义检查(检查是否死循环、0除等)
⑤中间代码生产
⑥代码优化
⑦目标代码生成:中间代码转低级语言代码,需要考虑硬件系统结构
⑧目标程序
Ⅲ、错误:
词法错误:非法字符,关键字或标识符拼写错误
语法错误:语法结构出错,if endif不匹配, 缺分号
语义错误:死循环,零除数,其它逻辑错误
文法
文法定义
Ⅰ、概念:一个形式文法是-一个有序四元组G=(V, T, S, P)
其中:
1) V:非终结符。不是语言组成部分,不是最终结果,可理解为占位符。
2) T:终结符。是语言的组成部分,是最终结果。V∩T=0
3) S:起始符。是语言的开始符号。
4) P:产生式。用终结符替代非终结符的规则。形如a→β
Ⅱ、闭包
正则闭包: A+=A1∪A2∪A3∪...∪An∪... (也就是所有幂的组合)。
闭包: A*=A°∪A+(在正则闭包的基础上,加上Ao= {e} )。
| 类型 | 别称 | 说明 | 对应自动机 |
|---|---|---|---|
| 0型 | 短语文法 | G的每条产生式a- +β满足a属于V的正则闭包且至少含有-个非终结符,而属于V的闭包 | 图灵机 |
| 1型 | 上下文有关文法 | G的任何产生式a→β满足a<=β,仅仅S→s例外,但S不得出现在任何产生式右部 | 线性界限自动机 |
| 2型 | 上下文无关文法 | G的任何产生式为A- β , A为非终结符,为V的闭包 | 有限自动机 |
| 3型 | 正规文法 | G的任何产生式为A-→aB或A-→a, a属于非终结符的闭包,A、B都属于非终结符 |
语法推导树
一棵语法树应具有以下特征:
1、每个结点都有一个标记,此标记是V的一个符号;
2、根的标记是S;
3、若一结点n至少有一个它自己除外的子孙,并且有标记A,则A肯定在V-中:
4、如果结点n的直接子孙,从左到右的次序是结点n, n2..ng,其标记分别是: A, A2, - A,那么A->A1, A---A -定是P中的一个产生式。
有限自动机
Ⅰ、公式:M-(S,Z ξ,S0,Z)
Ⅱ、其中:
1) S是一一个有限集,每个元素为一个状态
1) z是一个有穷字母表,每个元素为一个输入字符
2) ξ是转换函数:是一个单值对照
3) S0,属于S,是其唯一的初态
4) Z是一个终态集(可空)
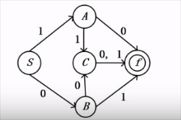
Ⅲ、有限状态自动机可以形象地用状态转换图表示,设有限状态自动机:
DFA=({S,A, B, C, f, {1, 0},ξ,S, {D}),
其中:
ξ(S, 0)= B,ξ(S, 1)=A,ξ(A, 0)=f, ξ(A, 1)= C,ξ(B, 0)= C, ξ(B, 1)= f,ξ(C, 0)=f,ξ(C,1)=f
正规式
Ⅰ、概念:正规式是描述程序语言单词的表达式,对于字母E,其上的正规式及其表示的
Ⅱ、正规集可以递归定义如下。
①ε是一个正规式,它表示集合L(e)={e}.
②若a是E上的字符,则a是一个正则式,它所表示的正规L(a)={a}。
③若正规式r和s分别表示正规集L(r)=L(s),则
(a) r|s是正规式,表示集合L(r)UL(s);
(b) r.s是正规式,表示集合L(r)L(s);
(c) r*是正规式,表示集合(L(r))*;
(d) (r)是正规式,表示集合L(r)。
care:|是或、*循环多次
表达式
构造树利用数的遍历求得前缀表达式和后缀表达式
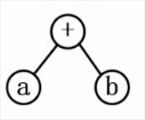
前缀表达式:从根到叶(+ab)
中缀表达式:从中间开始遍历整个树(a+b)
后缀表达式:从叶到根(ab+)
函数调用
传值与传址
| 传递方式 | 主要特点 |
|---|---|
| 传值调用 | 形参取的是实参的值,形参的改变不会导致调用点所传的实参的指发生改变 |
| 引用(传值)调用 | 形参取的是实参的地址,即相当于实参存储单元的地址引用因此其值的改变同时就改变了实参的值 |
多种程序语言特点
- Fortran语言(科学计算,执行效率高)
- Pascal语言(为教学而开发的,表达能力强, Delphi )
- C语言(指针操作能力强,高效)
- Lisp语言(函数式程序语言,符号处理,人工智能)
- C++语言(面向对象,高效)
- 6.Java语言(面向对象,中间代码,跨平台)
- 7.C#语言(面向对象,中间代码,.Net)
- Prolog语言( 逻辑推理,简洁性,表达能力,数据库和专家系统)
参考
软件设计师考试教程