OO第一单元博客
一.我的程序结构
在本次的面向作业当中,一共经历了三个小作业,并且难度使层层递进的。在这里可以用工具来分析一下每次作业所使用的类的数目以及基本结构。
第一次作业:
| Type Name |
NOF |
NOPF |
NOM |
NOPM |
LOC |
WMC |
NC |
DIT |
LCOM |
| Poly |
5 |
0 |
7 |
7 |
149 |
28 |
0 |
0 |
0.285714286 |
| Unit11 |
0 |
0 |
1 |
1 |
44 |
8 |
0 |
0 |
-1 |
第二次作业:
| Type Name |
NOF |
NOPF |
NOM |
NOPM |
LOC |
WMC |
NC |
DIT |
LCOM |
| Tripoly |
7 |
0 |
16 |
16 |
334 |
54 |
0 |
0 |
0 |
| Unit12 |
0 |
0 |
1 |
1 |
54 |
12 |
0 |
0 |
-1 |
第三次作业:
| Type Name |
NOF |
NOPF |
NOM |
NOPM |
LOC |
WMC |
NC |
DIT |
LCOM |
| Cos |
6 |
0 |
1 |
1 |
38 |
7 |
0 |
1 |
0 |
| Index |
5 |
0 |
1 |
1 |
31 |
5 |
0 |
1 |
0 |
| Main |
0 |
0 |
1 |
1 |
25 |
3 |
0 |
0 |
-1 |
| Poly |
8 |
0 |
12 |
12 |
246 |
49 |
3 |
0 |
0.333333333 |
| derivative |
0 |
0 |
1 |
1 |
3 |
1 |
0 |
0 |
-1 |
| Sin |
5 |
0 |
1 |
1 |
37 |
7 |
0 |
1 |
0 |
| TreeNode |
9 |
0 |
9 |
7 |
42 |
9 |
0 |
0 |
0 |
可以看到,每一次的作业当中类的数目以及其中定义的函数的数目是在逐步上升的。我们可以简单看一下每次作业和前一次比增加了哪些内容。第二次和第一次相比增加了三角函数的类,相应的增加了两种求导算法的不同,以及乘法求导的法则,在基本类和方法类上都增加了内容;而第三次增加了嵌套的求导法则,相应的增加了分解储存多项式的树的内容。
而我在这次作业中也展现出来不足,在第二次作业中没有对第一次的代码进行重构,增加了自己第三次作业重构求导类的工作量。
除此以外,在高内聚低耦合方面的要求,可以看到,代表内聚不足的LCOM在第一次作业和第三次作业表现出来不足说明在第一次中缺乏对于类的正确使用,而第三次中的POLY类当中耦合过高,需要进一步改进。
以第三次作业为例,可以简单的画出各个类和方法的类图。
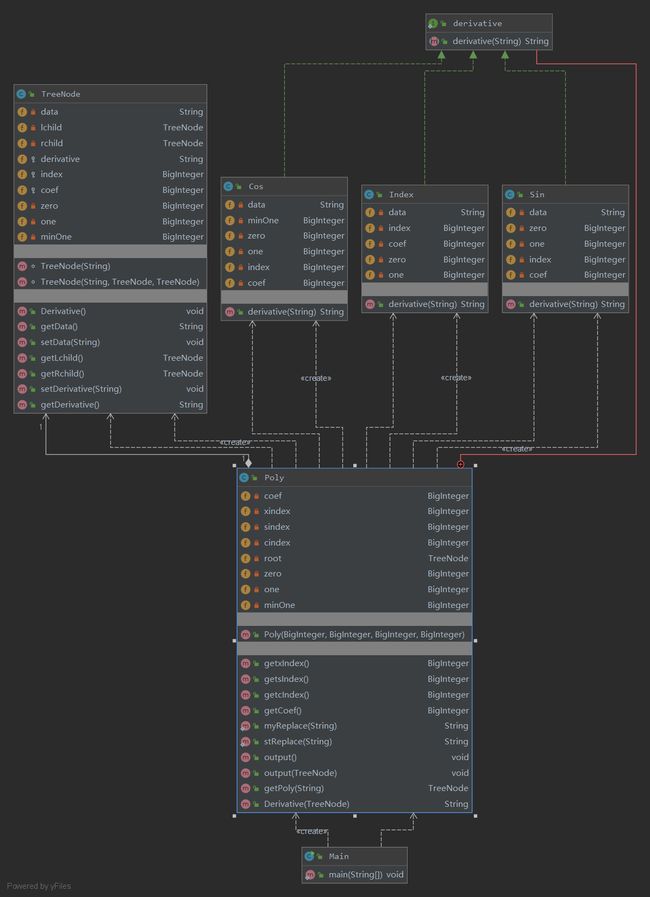
由类图可知,作业三的基本思路是建立二叉树,将计算符号作为中间节点,将因子作为子节点,并且通过递归的方式对于不同类型的因子进行分别求导计算。但是由于我没有针对乘法,加法,嵌套分别设置抽象类,因此将这些计算方式放在了poly类中作为递归时判断的条件,因此poly类的耦合度较高,需要进一步的改进。
二.我的程序的bug分析
在本次实验中产生了众多的bug,其中最难解决的是格式方面的bug以及嵌套结构中的bug。由于对嵌套格式的理解不到位导致在以括号位标志分层读入因子的时候容易产生不少的bug;对于嵌套结构的理解是今后类的调用的重点,需要进一步完善。而读入格式方面的bug主要出在正则表达式不够完善和对于replaceAll函数的过度依赖。ReplaceAll函数能够十分有效的消除很多复杂的读入内容,但是会漏掉很多违规的读入选项,因此对读入字符串的第一次的处理就显得至关重要,这也直接导致了本次的第三次作业本地提交未通过。
三.如何找到他人的bug
再找其他人的bug时我最常用的还是手动构造边界和特殊情况的样例。一般包括读入格式层面,输出格式层面以及对于特殊值的计算层面。首先需要观察目标代码的第一次处理的正则表达式,以及对于第二次分解表达式并储存的正则表达式。在这一方面一般会出现漏判错误格式以及错判格式的情况,因此能够很容易发现一些简单但是没有处理的bug。之后会判断输出格式,尤其是性能优化部分的代码。对于输出的处理很容易将本来正确的结果错误的输出,比如在简化系数和指数上的1时很容易将其他情况也错误处理。最后在代码层面难以找到bug时,就可以用一组特殊的数据进行测试,比如连续的系数相乘,连续的三角函数相乘,单项结果为零的各种形式都很容易缺乏对特殊情况的特殊处理。
四.应用对象创建模式来重构
在第三次作业的重构过程中,我重构了大量的结构和方法。由于前两次作业的扩展性很差,在第三次作业我需要重写三种因子类,三种抽象计算类,二叉树节点类。同时,再读入方面也要重构,需要重写因子写入树节点以及递归的求导函数,重构的工作量很大。重构的主要思路是保留扩展性的部分代码,而耦合度高的,针对性强的代码需要重新,因此需要加强自己类的观念,扩展自己的工厂模式,能够更好的进行扩展。
五.和优秀代码的对比和心得体会
在研究了其他同学的优秀代码之后,我发现好的代码都做好了求导接口的构建以及工厂模式的扩展,尤其是在类的方面分的很细,能够分别发现bug和调用,代码耦合度很低,是很值得学习的代码思路。
在本单元的学习中,我学习到了很多原来有想法但是没有实现的工厂类结构,将代码的每一部分写好封装最后一一调用,结构十分清晰,思路一目了然,是以前写代码的时候无法感受到的,工厂类是一种十分规范且便于扩展的方法,之后要多加练习。