Scrapy采集“人民的名义”豆瓣评价实验报告
转载请注明出处!!!
实验对象:豆瓣电影--人民的名义
实验目的:通过使用scrapy框架采集“人民的名义”评价内容,进一步体会信息检索的过程。
实验过程:分析采集实体->确定采集方法->制定爬取规则->编写代码并调试->得到数据

ps:由于最近豆瓣发布的 Api V2测试版 需要授权 走oauth2,但是现在不开放key申请,所以直接爬了网页。
---------------------------------欢迎纠错和提问!24小时在线不打烊!!---------------------
目录
- 分析采集实体
- 确定采集方法
- 制定爬取规则
- 编写代码并调试
- 得到数据
- 使用分词工具包进行数据分析
- 总结和感悟
1. 分析采集实体
当前页面中,评价相关的内容有很多,我们通过分析选取更具代表性的数据进行采集。
1.1 IMDb (备用)
豆瓣提供了IMDB的链接。
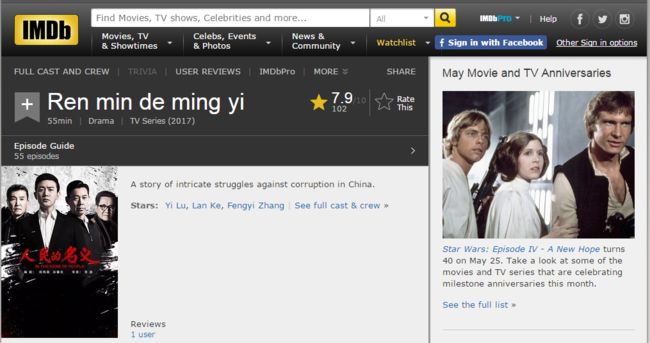
IMDb只提供了5条英文评价
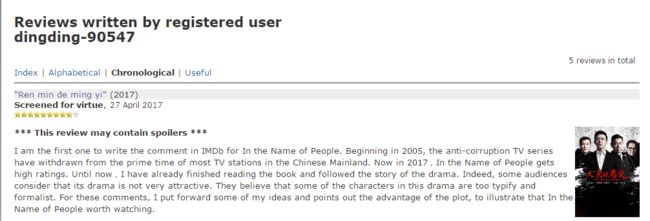
记录网址备用: http://www.imdb.com/user/ur70913446/comments?ref_=tt_urv
1.2 全部评价(不采集)

这里指向了全部评价,没有分类,不考虑

1.3 分集短评(不采集)
这里提供了分集短评,不具代表性,不考虑

1.4 全部短评(采集部分)
这里提供了人民的名义的全部短评,考虑采集看过/热门的前50条

1.5 全部剧评(采集部分)
人民的名义的剧评考虑采集最受欢迎的前50条

1.6 确定采集实体
豆瓣提供了部分xml格式的影评

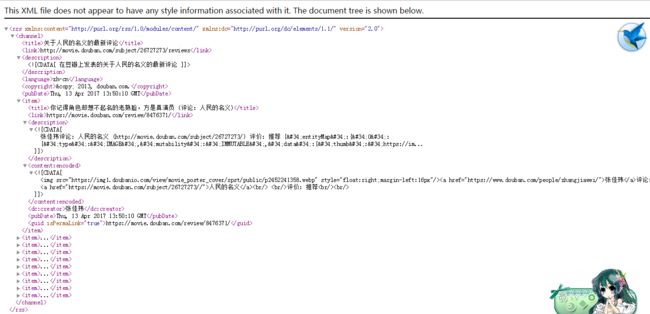
采集的内容很全面,参考该官方示例确定采集实体
- title(剧评)
- description
- star
- creator
- pubDate
2. 确定采集方法
2.1短评采集
start_urls:https://movie.douban.com/subject/26727273/comments?status=P
内容:当前页内采集

分页:【后页】跳转下一页
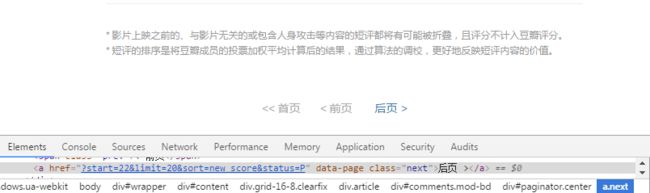
2.2剧评采集
start_urls:https://movie.douban.com/subject/26727273/reviews
内容:完整评价在当前页面可以爬取

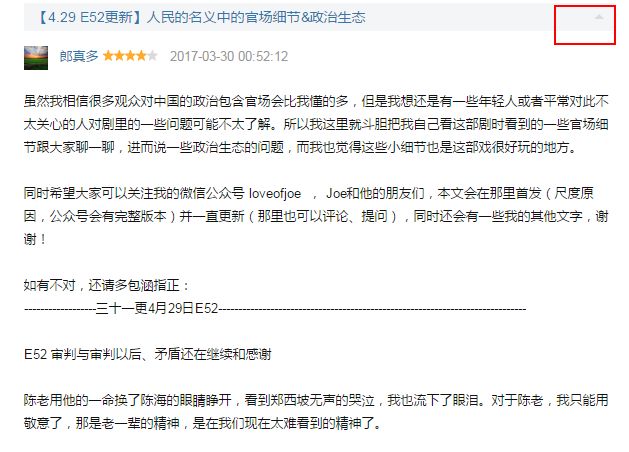
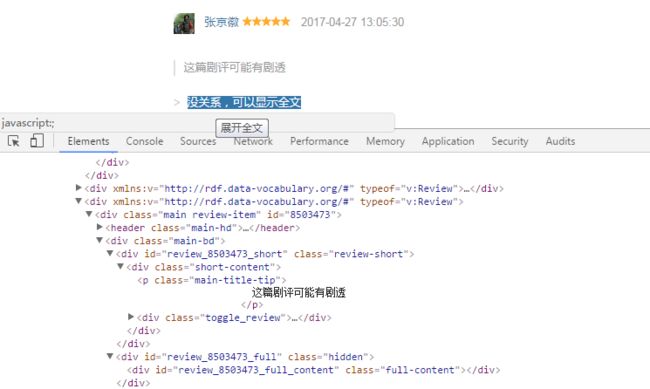
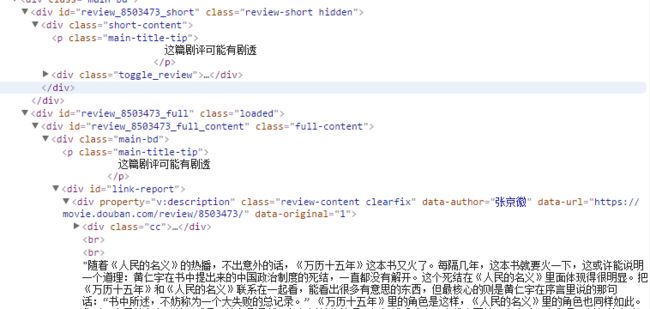
可以看出,页面通过js控制改变class来控制内容的显示隐藏和ajax动态赋值。
3. 制定爬取规则
3.1 短评规则
3.1.1 description

div#comments div.comment-item div.comment p::text
3.1.2 star
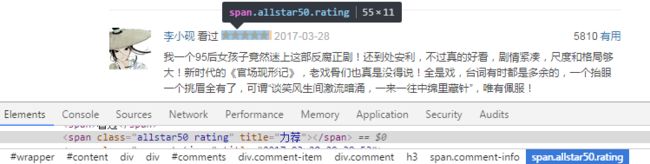
div#comments div.comment-item div.comment h3 span.comment-info span.rating::attr(title)
3.1.3 creator
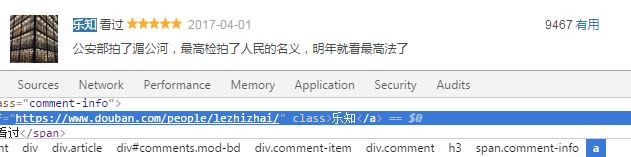
div#comments div.comment-item div.comment h3 span.comment-info a::attr(href)
3.1.4 pubDate
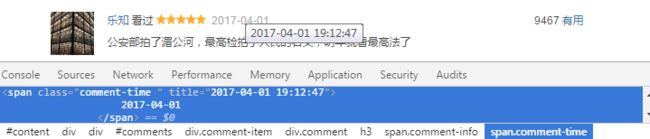
div#comments div.comment-item div.comment h3 span.comment-info span.comment-time::text
3.1.5 next_page

div#paginator a.next::attr(href)
3.2 剧评规则
3.2.1 title
3.2.2 description
3.2.3 star
3.2.4 creator
3.2.5 pubDate
3.2.6 next_page
4. 编写代码并调试
4.1 爬取短评
新建工程douban

编写items.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
description = scrapy.Field()
star = scrapy.Field()
creator = scrapy.Field()
pubDate = scrapy.Field()
编写my_short.py
import scrapy
from douban.items import DoubanItem
class MyShortSpider(scrapy.Spider):
name = "my_short"
allowed_domains = ["douban.com"]
start_urls = [
'https://movie.douban.com/subject/26727273/comments?status=P',
]
def parse(self, response):
for comment in response.css('div#comments div.comment-item div.comment'):
item = DoubanItem()
item['description'] = comment.css('p::text').extract_first(),
item['star'] = comment.css('h3 span.comment-info span.rating::attr(title)').extract_first(),
item['creator'] = comment.css('h3 span.comment-info a::attr(href)').extract_first(),
item['pubDate'] = comment.css('h3 span.comment-info span.comment-time::text').extract_first(),
yield item
next_page = response.css('div#paginator a.next::attr(href)')
if next_page is not None:
next_urls = response.urljoin(next_page.extract_first())
yield scrapy.Request(next_urls,callback = self.parse)
403爬取失败
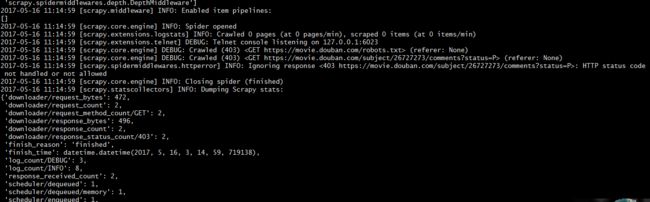
可选方案:
- 动态设置user-agent
- 禁用cookies
- 设置延迟下载
- 使用Google cache
- 使用代理ip
- 使用crawlera
scrapy cloud--crawlera的尝试
登录scrapy cloud创建自己的工程并获取key

在自己的服务器安装crawlera

修改settings.py:
找到settings.py文件

添加crawler代理

配置并填写自己的key
pass字段不用填写
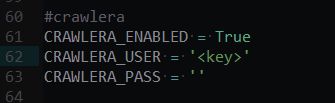
如果你的spider中保留了cookie,在header中添加

407 错误如下:

安装shub

用自己的key登录shub

上传工程

运行之后还是407
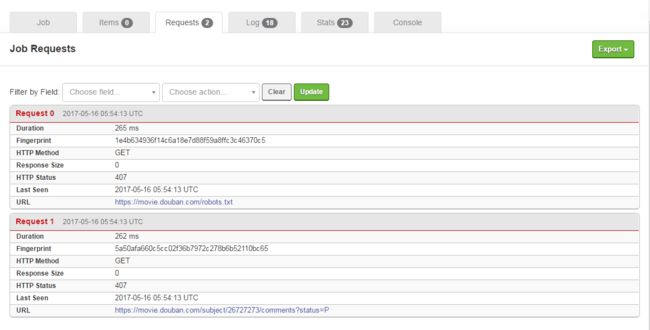
说好的免费现在好像是收费了。。弃坑

使用代理ip
在经历了403 503 111 400 等一系列错误码之后,又尝试了许多代理ip,终于爬到了数据。

然而没过多久就又挂了...
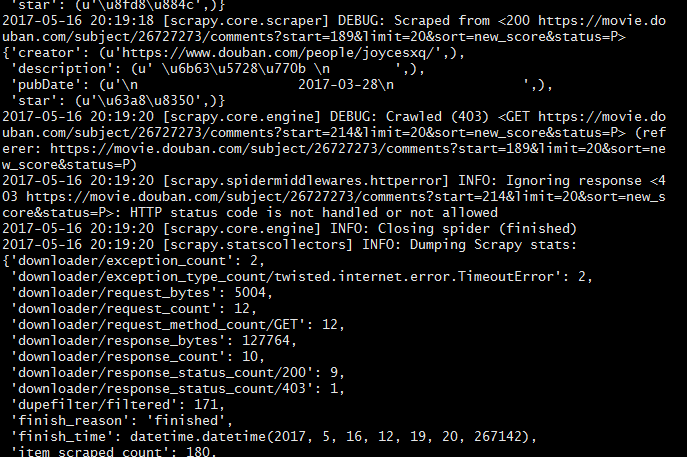
总算是可以爬到数据了,只要及时更换代理ip就没有问题。
修改后的settings.py代码
是否遵循robots.txt

设置下载延迟时间

不保存cookie

这是中间件middlewares的一个函数,543是随便写的,只要不重复就可以

user-agent包头可以在chrome开发者工具获取到
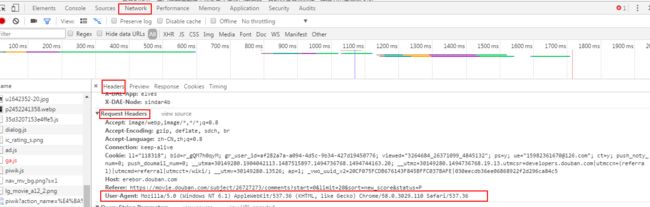
在middlewares.py增加如下代码

其中,引号中的url是代理ip
国内高匿代理IP
西刺免费代理IP
但是这样依然会在爬到一半的时候挂
更好的方法是放一组代理ip,在爬到一半的时候接上继续爬
5. 得到数据
某一次爬到数据180条
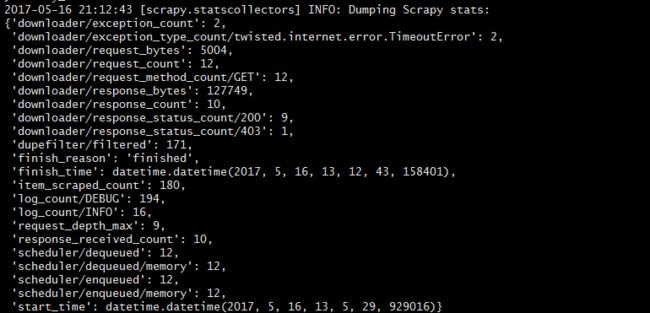
部分xml数据展示

6. 使用分词工具包进行数据分析
7. 总结和感悟
未完待续。
参考链接:
如何让你的scrapy爬虫不再被ban
scrapy爬虫代理——利用crawlera神器,无需再寻找代理IP