本思考题的设计需求是力图找到一个简单且可行的饲料分配方案,由于不涉及到饲料价格或者是营养均衡之类的优化问题,因此在假设总的饲料量必能满足所有动物的热量需求的前提下,我们只需要采用贪心策略就可以找到一个算法上的可行解。
当然,这里我们关注的不只是在算法思路上的尽可能简单,由于是OO,所以我们更需要将整个过程进行抽象和封装,从而使得该方案可以在顶层模块的架构上也要尽可能的简单清晰。而为了做到这一点,本节课上我们所学习到的知识(也就是继承与实现,多态与归一化等)可以说是必不可少的。
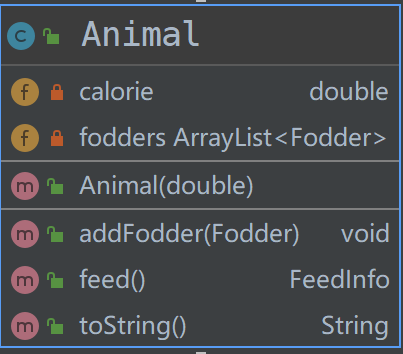
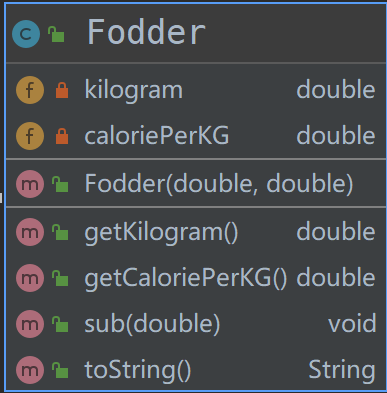
首先,我们可以看到,这个问题的核心就是要处理动物与饲料之间的一个映射关系,也就是某个动物分别需要哪几种饲料各多少,某种饲料分别投喂多少给哪几种动物这样。那么很显然,我们需要建立动物(Animal)和饲料(Fodder)这两个“家族”,至于它们都有哪些具体的成员以及成员之间有着怎样的关系(继承or实现)则取决于进一步对其属性和方法的分析。
对于动物而言,我们需要知道这个动物可以吃哪些饲料,以及它每天需要的总热量,这些都是属性,所以我们需要将Animal定义为一个父类而非接口;同理,对于饲料,我们也需要知道饲料的总重量以及每单位饲料所产生的相应热量,因此Fodder也必须是一个父类。1
明确属性只是第一步,接下来我们得知道对这些属性我们要执行什么操作,也就是方法。而对于方法的实现,首先应该明确的是我们站在谁的立场上去思考问题,如果我们站在饲料的立场上,那么我们关心的就是这个饲料应该喂给哪些动物,分别喂了多少等等;而如果我们站在动物的立场上,那么我们关心的就是这个动物吃了哪些饲料,都吃了多少。相信同学们看到这已经意识到了,没错,就本题而言,出题人已经提前帮我们明确了我们的立场——我们知道的是“每一种动物能吃哪些饲料有明确规定”,而非“每一种饲料能给哪些动物吃有明确规定”。
既然如此,我们就可以给动物一个基本方法(Key Method):喂食(feed)。这个方法的大致内容就是:如果这个动物所需的总热量还没有得到满足,就从它能吃的饲料里任选一种,尽最大可能地满足这个动物的热量需求。
其实这个方法同时也是我们算法的核心,比如如果一次喂食没有喂完怎么办?是优先把当前这个动物喂到饱,还是尽量给大家都均衡一些?不过由于这个跟我们本节课探讨的主题没什么关系,所以我们就不用管它了。这里笔者就采用了一种最简单的方法,也就是每次只选一种饲料,能给这只喂多少就喂多少,不够后面再说。
而围绕着这个核心方法,其他的方法也就自然而然地明确了,包括更新动物的可食用饲料列表,获取特定饲料的单位卡路里,获取特定饲料的当前剩余量,更新特定饲料的当前剩余量等等。最后我们得到的Animal与Fodder类的属性与方法如下图所示:
 |
 |
这样一来,我们在main方法中就只需要利用一个简单的循环就可以获得我们想要的饲料分配方案。为了便于演示,我设计了Cow和Pig两种动物,以及Water, Grass, Corn三种饲料。它们的基本信息如下所示:
| Animal | Fodders | Calorie |
|---|---|---|
| Cow | Water, Grass | 500 |
| Pig | Water, Corn | 300 |
| Fodder | CaloriePerKG | Amount(可在初始化时设定) |
|---|---|---|
| Water | 20 | 20 |
| Grass | 50 | 5 |
| Corn | 80 | 3 |
main方法的代码如下:
public static void main(String[] args) { //初始化基本信息 ArrayListanimals = new ArrayList<>(); Water water = new Water(20); Grass grass = new Grass(5); Corn corn = new Corn(3); Cow cow = new Cow(); cow.addFodder(grass); cow.addFodder(water); animals.add(cow); Pig pig = new Pig(); pig.addFodder(corn); pig.addFodder(water); animals.add(pig); ArrayList feedInfos = new ArrayList<>(); //制定饲料分配方案 while (true) { boolean allFull = true; for (Animal animal : animals) { FeedInfo feedInfo = animal.feed(); if (feedInfo != null) { feedInfos.add(feedInfo); allFull = false; } } if (allFull) { break; } } //输出最终信息 for (FeedInfo feedInfo : feedInfos) { System.out.println(feedInfo.toString()); } }
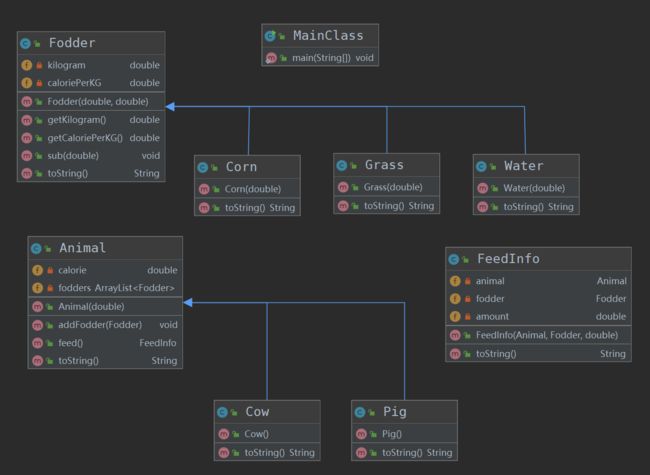
整个项目的UML图如下:
最终程序运行输出的结果如下:
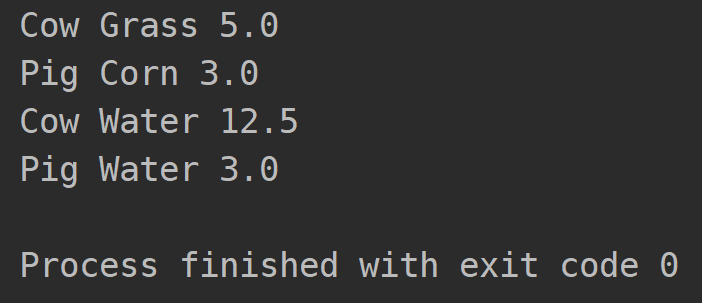
至此,整个饲料分配问题基本得到了较为完善的解决。
总结与归纳
那么,问题来了:在整个方案的设计与实现中,究竟哪里运用到了归一化和多态呢?
答案就在之前提到的FeedInfo类中:
1 public class FeedInfo { 2 private Animal animal;//投喂的动物 3 private Fodder fodder;//投喂的饲料 4 private double amount;//一次投喂的饲料量 5 6 public FeedInfo(Animal animal, Fodder fodder, double amount) { 7 this.animal = animal; 8 this.fodder = fodder; 9 this.amount = amount; 10 } 11 12 @Override 13 public String toString() { 14 return animal.toString() + " " + fodder.toString() + " " + amount; 15 } 16 }
可能有的同学看到这会觉得有些失望:为啥到头来多态就用在了这么一个“不起眼”的地方呢?其实,这恰恰是因为作为父类的Animal和Fodder把子类的大部分方法和所有属性都已经实现了,子类也就没有必要再去修改啦(包括我们的feed()方法)。当然如果你把最后的输出结果放在feed()里面,那么子类就必须对它进行重写了,不过这样反而有些冗长而有损简洁美,所以我就没有这么做。2
额外的细节——
1.浅拷贝与深拷贝
如果有同学仔细地看了我的main函数的话,可能还会发现另一个问题:明明所有的饲料都是在main方法里定义的,动物是怎么在自己的feed()方法里对饲料的量进行修改的呢?其实这就涉及到面向对象里面另一个很重要的问题:关于深浅拷贝的使用与注意事项。简单来说,这里虽然所有的Fodder都是在main()函数里定义的,但是它们的引用却被传给了相应的动物。不仅如此,以water为例,cow和pig饲料列表里的water其实指向的是同一个water(类似c语言的指针),这样我们就可以很方便地在cow和pig各自的feed()方法里对water的量进行增减了。关于深浅拷贝具体的介绍还请感兴趣的同学自己到网上查一下,这里就不展开了。但是必须要强调的是,这个东西是把双刃剑,用的好可以让代码变得简洁,但要是用不好,很可能会出现一些不可描述的错误,还请各位务必小心哦~
2.生产者-消费者模式
另外有一点不得不说,就是这个农场模型很像并发里经典的生产者--消费者这样的关系——饲料是生产者,动物是消费者。不过区别在于,这里我们不是多线程并发实现的,而是所有的动物排好队一个一个来喂食的。
所以,现在我们不妨做一个更大胆的假设:如果有一天,农场变成了奥威尔笔下的《动物庄园》,所有的饲料都在一个仓库里,动物们自己过来拿自己想吃的吃,那么他们会打起来吗?如果采用我们现在的方法,又会发生什么有趣的事情呢?