一、JML理论基础以及应用工具链
(一)什么是JML
JML全称Java Modeling Language,是一种描述模块规格的语言。
相比于自然语言,JML更注重规格与规范,采用一套范式描述模块的功能,这样一来不容易产生歧义,有利于开发者之间的合作;
二来由于是规范化书写,我们可以通过某种方式让机器明白要做的事,从而实现自动化的检验。
(二)JML语法
1、书写格式
JML一般作为注释放在代码当中,单行注释格式为//@annotation或者/*@annotation@*/,
多行注释以/*@annotation开头,中间的行是@annotation,以@annotation*/结尾
2、内容要求
JML中的内容基本涉及三个要素,分别是表达式、方法规格和类规格
(1)表达式
首先,有这么一些关键词及其形式:
\result:指方法非void的返回值
\forall:全称量词,与其配套的格式是(\forall ①;②;③),其中①是类型+变量,②是变量的范围,③是具体的行为,是一个可以判断的布尔表达式
\exists:存在量词,结构与\forall相似
\sum:求和,结构与\forall结构类似,但是结果是对第三部分符合的变量求和
\nothing:空集
\everything:全集
\old:被这个修饰过的变量指方法执行前该变量的值。需要注意的是,使用这个关键词必须特别小心,例如
\old(p.size())和\old(p).size()就是不同的变量
以上关键词可以组成表达式,且表达式可以嵌套组成新的表达式。一般而言,表达式是指布尔表达式。
(2)方法规格
方法规格中有以下关键词:
normal_behavior:表示方法正常执行的分支
requires:表示方法进入该分支的前置条件,后面跟着一个表达式
assignable:表示方法会产生的副作用,后面跟着一个或多个变量,表示方法可能会修改的变量
ensures:表示方法完成该分支后的结果,后面跟着一个表达式
exceptional_behavior:表示方法异常执行的分支,往往抛出异常
signal:抛出异常的类型,后面跟着一个表达式,表示抛出该异常需要满足的条件
(3)类规格
类规格主要对类的成员变量进行约束。在类规格中,我们使用instance来表示成员变量,同时为了联系各个类,我们一般加上public修饰;
有时我们也会使用not_null对成员变量进行约束。
此外,我们使用invariant修饰一些表达式,表示无论这个类的实例怎么变化,其变量必须时刻满足这些表达式;还有一些表达式会用constraint修饰,
表示任意一个方法执行前后成员变量的变化必须符合这些表达式
(三)JML工具
实际上,我在写作业的过程中完全没有使用JML工具,一切全凭自己对于JML的理解写,然后使用JUnit测试。
受本次博客驱使,我决定了解JML工具的应用,但是JML工具的不成熟+我自己对于CPI很生疏,我没有完成JML工具的使用,因此我只能放出一些结论。
1、OpenJML
OpenJML可以对代码进行JML语法静态检查和程序代码静态检查,JML语法静态检查只关心JML语法,不关心代码,而程序代码静态检查只关心程序中可能
隐藏的错误,不关心JML
OpenJML似乎无法支持对数组的检查,功能似乎并不完善
2、JMLUnitNG
这个真的不知道怎么操作,总有一堆我看不懂的东西。和同学交流后发现,这个工具同样也不完善,想要真正对Group测试,必须对Group进行魔改。
到这一步,我想这个工具(也许还有OpenJML可能也一样)目前就失去了使用的价值,因为我不可能舍本逐末地为了机器能读懂我的代码而魔改自己的代码,让它变得
繁琐冗余。
3、个人感想
个人认为JML工具在发展完善前没有使用的必要。我在完成作业,包括进行实验时,都没有使用这些JML工具,但是我至少还是完成了任务,反过来,
当我尝试使用JML工具的时候,我甚至不能完整地用自己的代码去测试。我认为JML更多地还是沟通人与人,如果JML能帮助合作,我想这就够了。
二、作业设计
(一)第一次作业设计
1、作业整体架构
第一次作业较为简单,基本不设时间限制。但是我还是设置了两套存储机制,一套用来查询一套用来遍历。同时isCircle使用了类似于并查集的机制,
将所有处于同一极大连通分支中的人放在同一个数组中,并且为了后续查询方便为每个人都加了一个编号标识所在分支,这样查询的时间复杂度就集中在
查找人,然而加关系就麻烦了,必要时还要将合并后的人整体改编号
以下为方法分析:
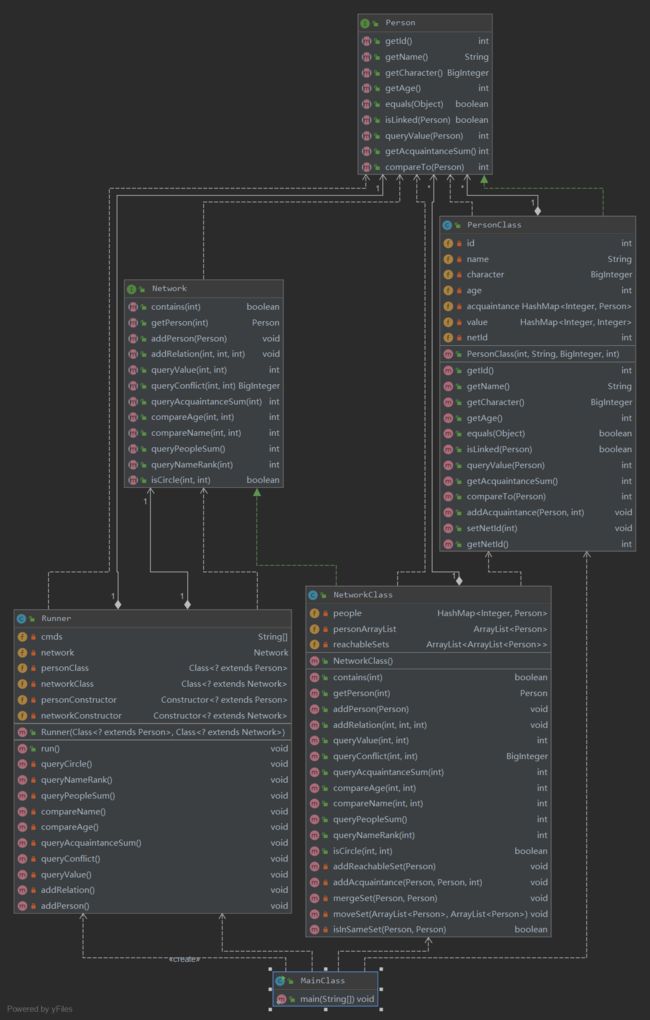
基本和之前的分析差不多,加关系比较复杂,另外queryValue可以无视
2、bug分析
第一次作业并没有部署JUnit进行测试,只是简单地自己检查了一遍代码就交上去了,结果栽在了一个坑上:判断两人是否认识还要考虑两人是否是同
一人,即自己认识自己。结果下来我才意识到一件事,我之前所谓的有自信只是针对黑箱式的任务,即不要求具体怎么实现,只关心输入和输出。这个单
元的作业要求细化,它关心到了每个方法的目标,这样我的限制条件增多,而且体系是别人给的,自己并不熟悉,一不小心就容易犯错。
(二)第二次作业设计
1、作业整体架构
这一次作业开始,我更多地考虑时间因素了。我为节省时间做出的努力有这么几个方面:
1.预先设定容器大小。我们知道,所有基于数组实现的容器都是有上限的,在达到上限(或者有的容器设定了阈值)时,容器必须扩容,
而这很费时费力,特别是HashMap,扩容的resize机制极其复杂。基于课程组给定的数据,我为不同类中的ArrayList和HashMap设定了不同初
始容量(当然为了避免额外的运算,我采用了缺省构造方法自然增长能达到的容量)
2.采用缓存技术。当然这里的缓存是非常低级的,只是记录了数据有没有改变,以及对于年龄和冲突而言,记录了年龄和、年龄平方和与
冲突和。我想如果是加一个查一次的方式的话,我恐怕就要超时了。
3.折半双循环。有的双循环因为其特性,只需要遍历其中一半的情况即可,其他情况完全是多余的,因此我采用了折半的双循环节省时间。
4.蚊子肉也是肉——位运算代替乘法。前面提到双循环折半,自然的想法是直接结果乘2,但是计组的知识告诉我们,乘法是最耗时的运算,
加减法次之,最省时间的方法是位运算(当然这是我查看java库API的感悟)
以下为方法分析:
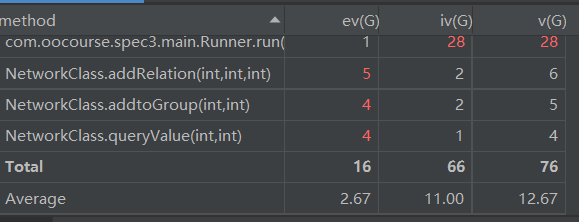
和之前的分析也吻合,相比于上次多了一个addtoGroup,和queryValue差不多的情况,就是if多了点
2、bug分析
第二次作业我试着部署了一些JUnit,不过感觉并没有什么用处,因为我还是错过了发现bug的机会,因为我出bug的根源,除了有一个点是没有
缓存导致超时外,其他的点都是我漏看了一组人数限制导致的,就算我部署了JUnit,我也只能查到因为实现方法细节不对导致的bug,对于这种
从根源上就出问题的bug完全无能为力。和上次作业一样,这次作业的bug可以说是同样的成因。
(三)第三次作业设计
1、作业整体架构
我很焦虑啊。。。
事情是这样子的,当时我是星期六才开始动手的,这就导致我没有时间去细细思考应该怎么规划,结果就是,我采用了我能想到的最直接
的方式去解答问题。这次的作业主要就是三个方法最复杂:qbs、qmp和qsl。其中qbs的问题我在第一次作业中就已经解决了,因为我使用的是
加关系合并的方式获得单个人所在的极大连通分支,那么对于两个分支因为加关系而合并,必然只保留一个,但是我为了能依据人的分支号快速
找到分支,在合并后没有删除被合并的分支,而是将被合并的分支改为了null(实际上这一步也是不必要的,我只是为了debug)那么,要查找总
共有多少分支,只要我维护一个无用分支数,每次合并的时候这个值就+1,最后总分支号减去无用分支数即可。
qmp的实现要复杂一些,我使用了dijkstra算法,但是没有堆优化。要命的是我的储存方式对遍历极为不友好,因此我专门开了一个类来维护
这些分支。每当中间有任何改动的时候我就设置状态,直到查询的时候将关系转换为矩阵,然后一次查阅。我采用的是多级缓存的思路,即能直
接找到就别算,算了就只算并储存相应的结果。以dijkstra算法为例,我在一次查询的时候转换,然后每查一次就将对应的人的最短路径全部标记,
下次和此人相关的时候就不用查了,但是和此人无关的还是要再算的。
qsl我是真的情急之下只能想到n*n*n的复杂度的暴力算法了,且不设缓存机制(因为是人和人的直接查询,每次都不一样),这种方法粗暴
有效但是易超时,后来我也确实因为这个丢了分。后面优化的话,我想我可能会依据割点分割分支,从而实现缓存。
以下为方法分析:

Network中的方法基本都是if多造成的,因为它们就是个壳,真正的实现在其调用的函数里;dijkstra算法因为本身特性过于复杂,至于另外两个也是
分支语句过多造成的。
2、bug分析
第三次作业什么都来不及,我就差没交上去了。现在回想起来,我本身的设计就已经暗地里埋了不少bug,超时且不说,隐藏的bug随时会让我头疼。
互测的结果也表明,我的设计也不是一定正确的,我还是被测试出了其他的bug。
三、理解和心得体会
(一)JML
最大的体会就是读JML的时候一定要仔细仔细再仔细。如果说写代码就是造房子的话,那么前面的作业就是客户给你提出大概的要求,你自己去造一栋房子,那么这个
房子的细节你都了然于胸,发生致命错误的概率低;JML是别人已经把房子搭好了,需要你具体去安排各个细节,在每个地方和要求的有一点出入都不行,这时候因为要求
反而多了,你就很有可能会犯错误。
不过,必须承认的一点是,JML十分利于团队合作。本质上团队合作也就是这样,任务分发下来,按照契约完成任务,这个契约当然越严格越好,我前面说的情况实际
上是相对于单人设计而言的,多人合作,JML的优势将十分明显。
(二)Java
因为必须对容器进行慎重的选择,我选择最直接的方式了解容器——自己看底层实现。结果是,我除了掌控了容器的特性,知道了一些避免提高时间复杂度的做法之外,
还收获了一些意想不到的东西。位运算便是其中一个,我之前从来没有想过还可以这样写,虽然原理上的东西都清楚,可是真正看到Java开发人员的智慧之前我无论如何都
不会去往这方面想。此外,Java的API中还有很多前辈的智慧有待发掘,这些东西如果肯思考,都可以化为己用。我觉得,从API中寻找前辈智慧,这就是我这个单元最大的
意外收获。