数据分析与数据挖掘实战视频——学习笔记(八)(数据清洗(缺失值和异常值处理)、数据分布探索、数据集成)
网址:【数据挖掘】2019年最新python3 数据分析与数据爬虫实战_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili https://www.bilibili.com/video/av22571713/?p=51
数据探索与数据清洗概述
数据探索与数据与清洗概述:
数据探索的目的是急躁发现数据的一些简单规律或特征,
数据清洗的目的是留下可靠数据,避免脏数据的干扰。
这两者没有严格的先后顺序,经常在一个阶段进行。
就是我们刚拿到数据,我们进行数据探索,找出数据的简单规律,二则是拿到的数据可能不可靠,有些数据可能写入,爬取等等原因变得不可靠了,变成脏数据,所以要把脏数据排除或者将不可靠的数据修正成可靠数据(特别是数据量比较少的时候),这个也可以说是数据修补。而且数据探索和数据清洗经常在一个阶段进行。
数据探索核心
1、数据质量分析(跟数据清晰密切联系)
2、数据特征分析(分布、对比、周期性、相关性、常见统计量等)
数据特征分析,目的是发现数据的基本规律,
分布:发现数据的分布情况,正态分布,其他分布……根据分布,可以知道数据的大致走势。
对比:将多组数据放到一起,比较他们的情况,比如说之前说的多个着现在同一张图上面,找他们的规律。
周期性:我们可以看他是否具有周期性
相关性:找横轴纵轴之间的规律
常见统计量:比如说分位数,平均数,统计的计量分析……
我们可以初步发现一些规律,这只是数据探索。
数据清洗实战
数据清洗可以按如下步骤进行:
1、缺失值处理(通过describe和len直接发现,通过0数据发现)
通过describe和len的数的差别可以找到缺失值
通过0数据发现,通过实际中不可能为0的数据,但显示为0的数据,是为缺失值。
2、异常值处理(通过散点图发现)
异常值可能是爬取错误,可能是有人刷数据,可能是这个性能特别好。
缺失值处理方式
一般遇到缺失值,处理方式为删除,插补,不处理;
删除不适用于数据比较少,这样很影响数据。
插补的方式主要有:均值插补,中位数插补,众数插补、固定值插补、最近数据插补、回归插补、拉格朗日插值、牛顿插值法、分段插值等等。
异常值处理方式
遇到异常值,一般的处理方式是是为缺失值,删除、修补(平均数、中位数等等)、不处理。
接下来以淘宝零食类商品数据为例进行实战讲解。
我没有这个数据,我考虑用京东或者当当图书或者天山智能的数据。
这个是淘宝的零食类商品数据,感觉和我们的京东数据比较像,可惜我没有爬取评论数。那我试着从新爬一下当当的数据,加一个价格吧。
当当网数据可以看这个链接:数据分析与爬虫实战视频——学习笔记(四)(糗事百科、天善智能、当当商城、sql输出)

上面这个是淘宝的零食类商品数据,下面这个是我刚才爬取的当当商城程序设计类商品数据。
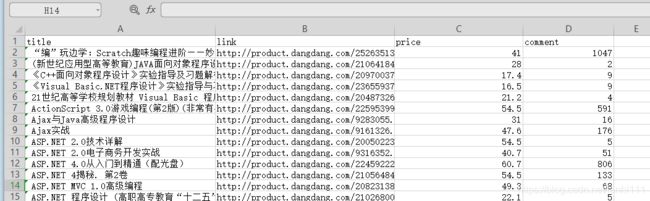
老师好像用的是phpMyAdmin(MySQL数据库管理)打开了本地文件(http://127.0.0.1/phpmyadmin ),我也看了一下相关信息:phpMyAdmin使用教程。暂时先不下载这个,我看看能否直接使用。
#导入数据
import pymysql
import numpy as np
import pandas as pda
conn=pymysql.connect(host="127.0.0.1",user="root",password="密码",db="dd")
sql="select * from books2"
data=pda.read_sql(sql,conn)
print(data.describe)

哦哦,原来我数据库里面都是char类型的,没有数字,那就用处理后的csv数据吧
嗯嗯,所以还是要加括号的。
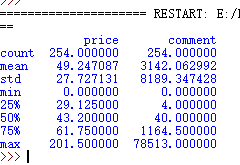
老师视频里面的数据图是这个:
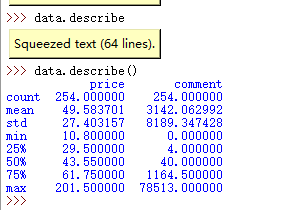
从这个图里面我们可以看到个数,平均数,标准差,最小值,最大值,4分位数值。
价格最小值为0很明显不正常,45万的最大评论数据也可能不正常。
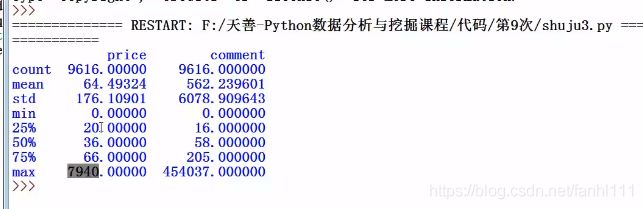
我的数据里面没有这个问题。继续。

这两个一样,所以说没有缺失值。再则可以把价格等于0的数据视为缺失值。
我们可以找到价格为0的数据改成中位数或者平均数,建议最好是用中位数。也就是中位数插补,我们也可以用拉格朗日插补,牛顿法插补等等。
我的数据里面没有0,所以我随意选一些数据改成0吧。
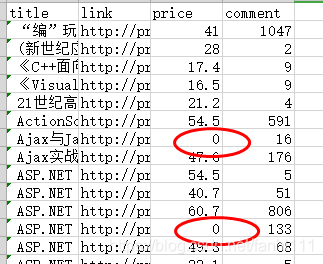
针对这个数据是有等于0的缺失数据了。
我们继续看怎么处理。
#isnull
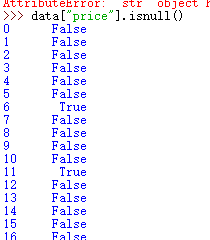
#导入数据
import numpy as np
import pandas as pda
data=pda.read_csv("E:/FHLAZ/sql_document/books2.csv",encoding='ANSI')
print(data.describe())
#数据清洗
#发现缺失值
x=0
data["price"][(data["price"]==0)]=None#(data["price"]==0)是条件
for i in data.columns:#i就是data的列
#print(i) title link price comment
for j in range(len(data)):#数据的列的个数
if(data[i].isnull()[j]):#data[i].isnull()给出一列是否为空的数据,j确定了那个数据,T的话就可以替换了。
data[i][j]="43.20"
x+=1
print(x)
print(data.describe())

中间的红色的字是警告,而不是错误。
我加了一个忽略警告的代码,看起来舒服一点。
接下来讲理:
#导入数据
import warnings
warnings.filterwarnings("ignore", category=Warning)
import numpy as np
import pandas as pda
import matplotlib.pylab as pyl
data=pda.read_csv("E:/FHLAZ/sql_document/books2.csv",encoding='ANSI')
print(data.describe())
#数据清洗
#发现缺失值
x=0
data["price"][(data["price"]==0)]=None#(data["price"]==0)是条件
for i in data.columns:#i就是data的列
#print(i) title link price comment
for j in range(len(data)):#数据的列的个数
if(data[i].isnull()[j]):#data[i].isnull()给出一列是否为空的数据,j确定了那个数据,T的话就可以替换了。
data[i][j]="43.20"
x+=1
print(x)
print(data.describe())
#异常值处理
#画散点图(横轴价格,纵轴评论数)
#得到价格
data2=data.T
price=data2.values[2]
#得到评论数
comment=data2.values[3]
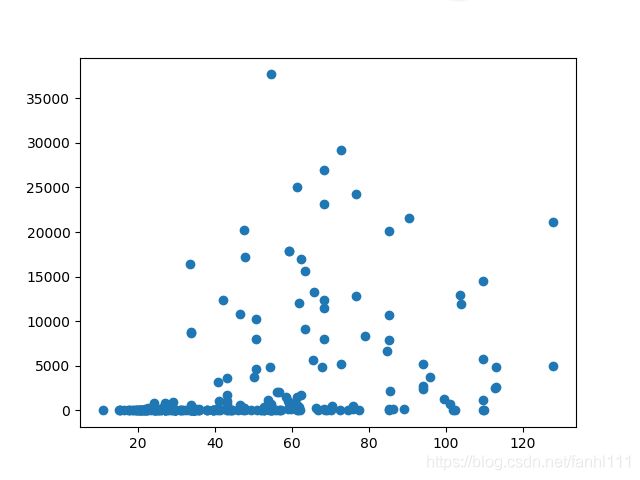
pyl.plot(price,comment,"o")
pyl.show()
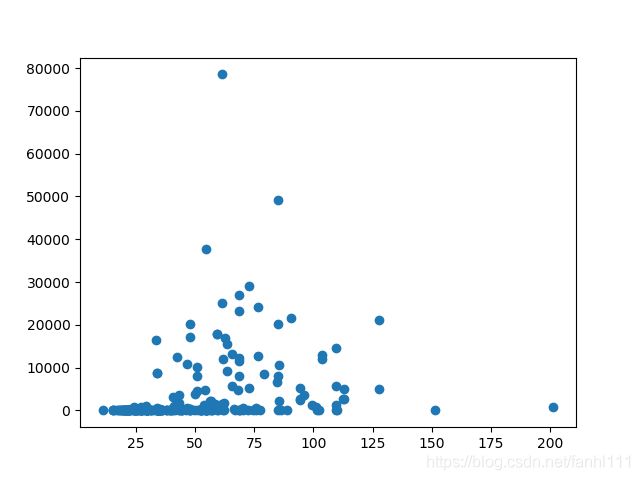
这个是老师视频里的图:
看这个图,老师说左边最上面的两个点偏移了我们主要点聚集地,可能是异常的,
看右边最下面的,比如说2000往上,也可以视为异常的,但实际上感觉价格低,买的人多,评论多也正常,价格高,买的人少,评论少也正常,不过先这么算吧,要有异常值处理。
#评论数异常>200000 价格异常>2300
#我的图里面就评论数异常>40000 价格异常>150
line=len(data.values)#行数254
col=len(data.values[0])#列数
da=data.values#data数据


python怎么将带小数的字符串 转换可以计算的数值类型
python2参考:python 数字类型和字符串类型的相互转换
python3:
>>> a = '12.3456'
>>> float(a)
12.3456
#评论数异常>200000 价格异常>2300
#我的图里面就评论数异常>40000 价格异常>150
line=len(data.values)#行数254
col=len(data.values[0])#列数
da=data.values#data数据
for i in range(0,line):
for j in range(0,col):
if(float(da[i][2])>150):
print(da[i])#输出异常数据
da[i][2]="43.20"#其实我感觉太复杂了,可以直接用da[i][2]了。
我的结果:
![]()
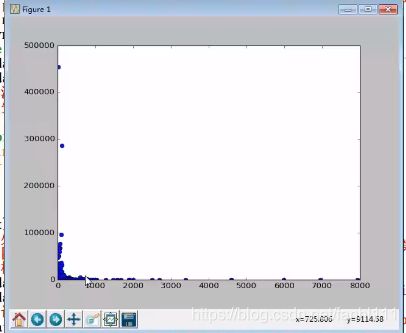
老师的异常数据图:

我们从图中可以发现异常数据多人参花胶这一类滋补品,我们还可以打开链接看看爬取是否出错。
我的爬取代码和图:
#评论数异常>200000 价格异常>2300
#我的图里面就评论数异常>40000 价格异常>150
line=len(data.values)#行数254
col=len(data.values[0])#列数
da=data.values#data数据
for i in range(0,line):
for j in range(0,col):
if(float(da[i][2])>150):
print(da[i])#输出异常数据
da[i][2]="43.20"#其实我感觉太复杂了,可以直接用da[i][2]了。
print("__________________")
if(float(da[i][3])>40000):
print(da[i])#输出异常数据
da[i][3]="40"#其实我感觉太复杂了,可以直接用da[i][2]了。
print("__________________")

处理之后的图:变得密集了。
da2=da.T
price=da2[2]
comment=da2[3]
pyl.plot(price,comment,"o")
pyl.show()
数据探索与数据清洗整体代码
#导入数据
import warnings
warnings.filterwarnings("ignore", category=Warning)
import numpy as np
import pandas as pda
import matplotlib.pylab as pyl
data=pda.read_csv("E:/FHLAZ/sql_document/books2.csv",encoding='ANSI')
#print(data.describe())
#数据清洗
#发现缺失值
x=0
data["price"][(data["price"]==0)]=None#(data["price"]==0)是条件
for i in data.columns:#i就是data的列
#print(i) title link price comment
for j in range(len(data)):#数据的列的个数
if(data[i].isnull()[j]):#data[i].isnull()给出一列是否为空的数据,j确定了那个数据,T的话就可以替换了。
data[i][j]="43.20"
x+=1
#print(x)
print(data.describe())
#异常值处理
#画散点图(横轴价格,纵轴评论数)
#得到价格
data2=data.T
price=data2.values[2]
#得到评论数
comment=data2.values[3]
#pyl.plot(price,comment,"o")
#pyl.show()
#评论数异常>200000 价格异常>2300
#我的图里面就评论数异常>40000 价格异常>150
line=len(data.values)#行数254
col=len(data.values[0])#列数
da=data.values#data数据
for i in range(0,line):
for j in range(0,col):
if(float(da[i][2])>150):
#print(da[i])#输出异常数据
da[i][2]="43.20"#其实我感觉太复杂了,可以直接用da[i][2]了。
#print("__________________")
if(float(da[i][3])>40000):
#print(da[i])#输出异常数据
da[i][3]="40"#其实我感觉太复杂了,可以直接用da[i][2]了。
#print("__________________")
da2=da.T
price=da2[2]
comment=da2[3]
pyl.plot(price,comment,"o")
pyl.show()
数据分布探索实战
探索数据的分布规律,非常有用,有时可以直接发现数据规律。
由于没有老师的淘宝零食类商品数据,因此使用当当的数据为例进行实战讲解。也就是和数据清洗的数据集一样。
我先说下我遇到的问题吧,我要画散点图,但是我的price是这个


直接求最大值格式也有问题,我也考虑过
for i in range(0,len(price)):
price[i]=float(price[i])
comment[i]=float(comment[i])
用这个代码可以运行,但是

总感觉有问题。
后来找到一个代码Numpy —— 数据类型对象 (dtype)
改了代码试试
#分布分析 主要是评论数和价格,上下界,组距
price=price.astype(np.float64)
comment=comment.astype(np.float64)
pricemax=price.max()
pricemin=price.min()
commentmax=comment.max()
commentmin=comment.min()
#极差rg:最大值-最小值
pricerg=pricemax-pricemin
commentrg=commentmax-commentmin
#组距st 设置多少合适?极差/组数
pricest=pricerg/12
commentst=commentrg/12
#画价格的直方图
pricesty=np.arange(pricemax,pricemin,pricest)
pyl.hist(price)
pyl.show()
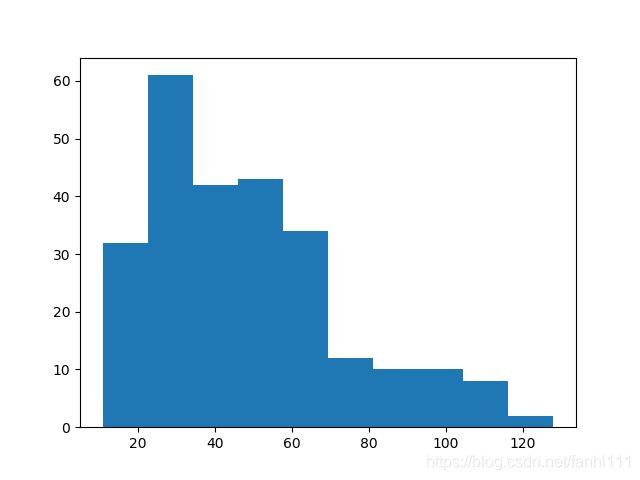
有图,但是,我们想要运行这个pyl.hist(price,pricesty)

报错。不好意思,我把最大值和最小值放错位置了pricesty=np.arange(pricemin,pricemax,pricest)
#分布分析 主要是评论数和价格,上下界,组距
price=price.astype(np.float64)
comment=comment.astype(np.float64)
pricemax=price.max()
pricemin=price.min()
commentmax=comment.max()
commentmin=comment.min()
#极差rg:最大值-最小值
pricerg=pricemax-pricemin
commentrg=commentmax-commentmin
#组距st 设置多少合适?极差/组数
pricest=pricerg/12
commentst=commentrg/12
#画价格的直方图
pricesty=np.arange(pricemin,pricemax,pricest)
#pyl.hist(price,pricesty)
#pyl.show()
#画评论的直方图
commentsty=np.arange(commentmin,commentmax,commentst)
pyl.hist(comment,commentsty)
pyl.show()
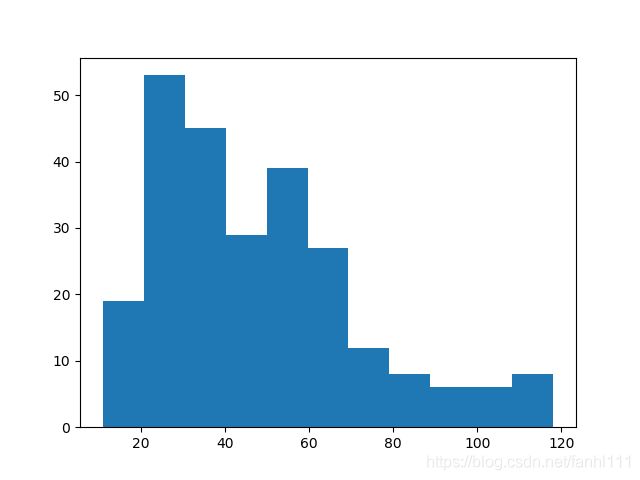
价格的直方图出来了。
评论直方图

老师的图是

这个图形可以发现数据主要集中在价格比较低的时候。
评论直方图

评论主要集中在价格比较低的时候。
数据集成实战
数据集成概述
数据集成一般是把不同来源的数据放在一起。但是来自多个地方的数据一定要做好实体识别与冗余数据识别,避免数据整合错误以及数据重复。
比如说有四个数据库,不同名字的数据可能代表同一含义,同一个名字的数据可能是不同含义,这些都需要整理,不可以整合错误。
数据集成技巧
一般来说,数据集成的过程如下:
1、观察数据源,发现其中关系,详细查看是否有同名不同意,同意不同名的情况。
2、进行数据读取与整合。(pandas)
3、去除重复数据。
import numpy as np
a=np.array([[1,4,5],[6,7,39]])
b=np.array([[13,44,52],[62,27,49]])
c=np.concatenate((a,b))
