R语言在大气污染数据分析中的应用-时间序列分析(一)

作者简介
作者:戴启立,系南开大学在读博士生
统计与编程语言 团队
受益于免费、开源以及程序化的数据挖掘和可视化上的方法学优势,R语言逐渐在学术界和工业界展现出其强大的工具支撑作用而受到了广泛的追捧。在大气环境领域,随着近年来我国环境空气质量监测体系的不断发展和完善,已有367个城市配置了1499个国家环境空气质量自动监测点位(参考真气网的数据来源说明https://www.zq12369.com/datasource.php),此外各地方政府也设置了大量省控点位,实现了对辖区范围内六项法规大气污染物的逐时自动监测,这些监测点位的投入使用使得大气污染监测数据呈现近指数级的增长,而传统的非程序化数据分析和绘图工具耗时费力,不便于数据分析人员快捷、高效地处理和分析数据,难以发挥监测数据在污染防治中应有的作用。同时,随着R语言中各类工具包(package)的不断涌现,一批适用于分析大气污染监测数据的包含数理统计分析工具和可视化方案的R程序包得以被开发应用开来(感谢开发者!),笔者拟就自己常用的几个分析工具包,结合具体案例,拟推出几期R语言在大气污染数据分析中的应用实例(时间序列分析、空间可视化等),与感兴趣的同行们探讨。
本期,我们通过对单一监测点位的全年逐时监测数据进行时间序列分析,以揭示其不同时间尺度的变化规律。
首先,安装和加载所需程序包:
install.packages(c("VIM","mice","readr","ggplot2","openair","tseries"plyr","reshape"))#笔者习惯使用的主要分析包,安装后通过library()加载
读取数据集:
pollut<- read_csv("C:/Users/……/Desktop/pollut.csv", col_types =cols(date = col_datetime(format = "%Y/%m/%d %H:%M")))
以下案例中使用的数据集抓起自https://www.aqistudy.cn/上某空气质量监测点位的2017年全年小时观测数据。pollut为包含SO2,NO2,CO,O3,PM10和PM2.5的2017年全年逐时浓度数据集。
1. 检查数据有效性(缺失值、异常值)
该数据集在前期已做处理,对数据的前处理规则不再赘述,此处仅讨论图形化的展示方法。首先绘制时间序列图,进行直观判断:
plot.ts(subset(pollut,select= -date),col="red")
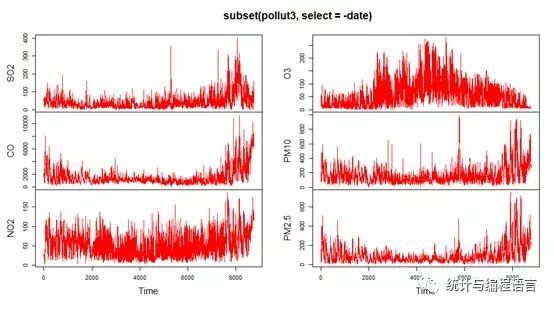
图1六项污染物的时间序列图
我们也可以使用summaryPlot函数快速概览数据整体情况,该函数以
图形展示数据的时间序列变化,统计指标以及频数分布图:
summaryPlot(pollut)
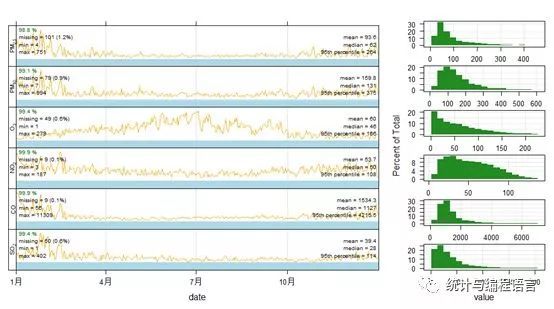
图2六项污染物的时间序列、频数分布和统计分析(平均值、中位/95%分位值、最小/大值、缺失值数据量及占比)
2. 绘制污染物日历图
调用openair中的calendarPlot函数:
calendarPlot(pollut, pollutant = "PM2.5") #pollutant参数选定展示变量名

图3PM2.5浓度的2017年日历图(颜色条指示PM2.5日均浓度值)
根据生态与环境保护部发布的《环境空气质量指数(AQI)技术规定(试行)》(HJ633-2012)中空气质量分指数对应的PM2.5浓度限值,将PM2.5日均浓度划分为六个等级并分别给予数值范围和颜色的定义:
breaks <- c(0,35,75,115,150,250,350)
labels <- c("优","良","轻度污染","中度污染","重度污染","严重污染")
cols=c("green","yellow","orange","red","purple","maroon")
calendarPlot(pollut, pollutant = "PM2.5",breaks =breaks,labels = labels, cols=cols,statistic="mean",main="Daily PM2.5 in 2017") #main表示图的标题

图3PM2.5浓度的2017年日历图(按照空气质量等级标注)
由于O3浓度一般采用8小时滑动平均值浓度,我们首先计算O3的8小时滑动平均浓度:
ozonedata<-rollingMean(pollut,pollutant = "O3",hours=8)
将图中日历显示改为O3每日最大8小时滑动平均浓度:
calendarPlot(ozonedata, pollutant = "O3",cols = "jet", statistic = "max",
main="2017年O3每日最大8小时滑动平均浓度")
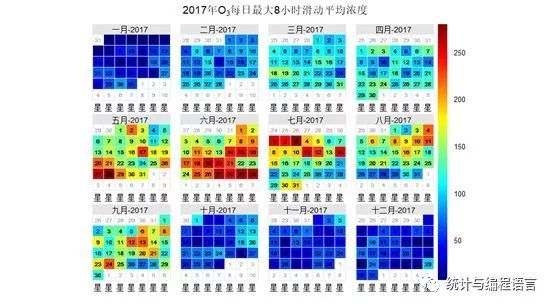
图4臭氧(O3)2017年日历图(颜色柱表示O3日最大8小时滑动平均浓度)
我们还可以利用trendLevel来绘制污染物的时间变化趋势:trendLevel(pollut,pollutant = "PM2.5",X="season",y="hour")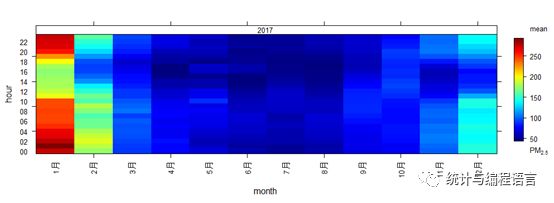
图5PM2.5每月的日变化(平均浓度)
接下来我们展示CO 95%分位数每月的日变化:
设定95%分位数的计算函数:
percentile<-function(x)quantile(x,probs= 0.95,na.rm = TRUE)
将statistic设置成95%分位数的计算函数,绘制图形:
trendLevel(pollut,"CO",x="month",y="hour",statistic= percentile)
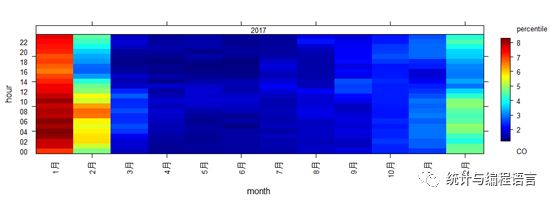
图6CO 95%分位数的每月日变化
3.绘制时间变化图
时间序列分析是大气监测数据的常用分析方法,包括对季度、月份、周-日、小时变化等特征进行分析,以揭示污染物的时间变化规律以及预测变化趋势。
调用timeVariation函数:
timeVariation(pollut,pollutant=c("SO2","NO2","CO","O3","PM10","PM2.5"), statistic = "mean")) #此处的pollutant参数可以根据需要自主选择一个或多个变量,该函数默认的统计方法(statistic)为均值和5/95分位数,也可以选择“medium”,展示中位值和5/95、25/75分位数。
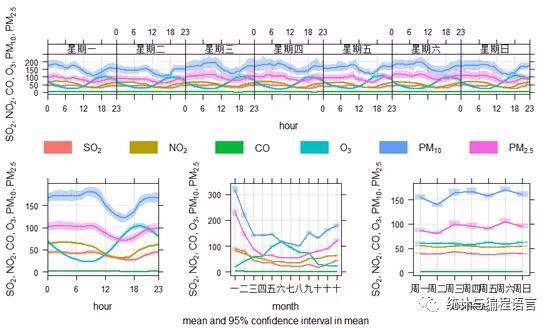
图7各项污染物的时间变化-均值及其95%置信区间(top-周与日变化,bottom-日变化、月变化、周变化)
将不同量级的多种污染物在同一图形中比较容易掩盖低浓度污染物(如SO2)的变化规律,timeVariation函数中提供了将不同量级的数据进行标准化处理(除以各自均值,以实现在同一数值范围可比)的方法,选择normalise=TRUE(默认为FALSE):
timeVariation(pollut,pollutant=c("SO2","NO2","CO","O3","PM10","PM2.5"),normalise= TRUE)
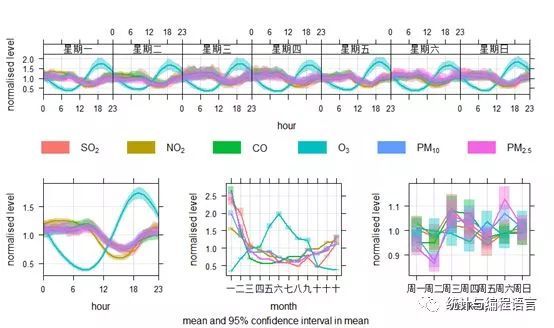
图8标准化的六项污染物时间变化图(均值及其95%置信区间)
该函数还提供了计算差值的功能,我们利用difference这一参数计算粗颗粒物浓度并展示其时间变化:
timeVariation (pollut,pollutant = c("PM2.5","PM10"),difference = TRUE)
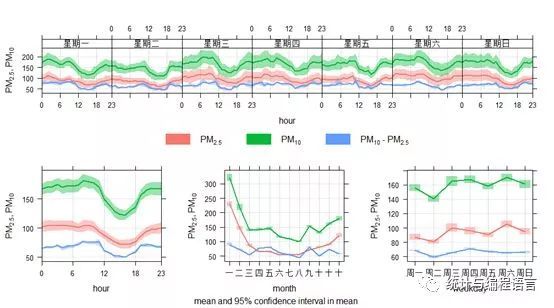
图9PM10、PM2.5以及其差值的时间变化
图9可以反映出粗颗粒物的变化特征:月变化中显示四、五月份浓度较高,说明春季扬尘污染较重;日变化中显示早晚出行高峰期浓度较高,说明该点位受道路扬尘源的影响。
此外,也可以利用plyr包中的mutate函数在原始数据集中增加、转换变量,如增加粗颗粒物(coarse)和SO2/NO2比值:
pollut2<-mutate (pollut, coarse=PM10-PM2.5,SN=SO2/NO2)
此外,group功能参数可以实现对数据进行进一步组合处理,如同时绘制不同季节、点位的数据等,我们利用group参数绘制coarse变量的季节性时间变化:
timeVariation(pollut,pollutant = "coarse",group = "season")
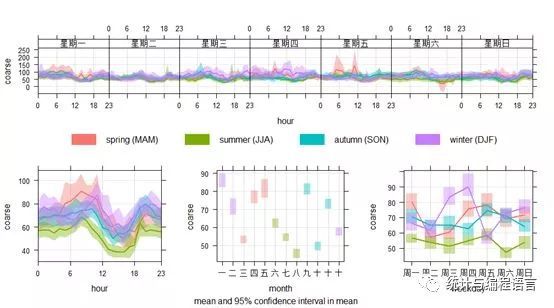
图10粗颗粒物分季节的时间变化图
在图10的日变化图(左下)中可以清楚的看到四个季节的早晚出行高峰时
段粗颗粒物浓度均出现峰值,说明道路交通扬尘是该点位粗颗粒物的重要来源,
也可以清楚地看出冬季的峰值时间较其它季节明显推迟,反映出晨昏线与昼夜
长短的季节性变化。
我们将数据集进一步整合成适用于程序语言处理的形式(由“宽”变“长”):
data2<-melt(pollut,id.vars = "date",variable.name = "pollutants",
value.name = "conc")
利用ggplot2的分面功能展示各污染物的时间变化序列:
ggplot(data2,aes(x=date,y=conc,col=pollutant))+geom_line(size=0.8)+facet_grid(pollutant~.,scales= "free")+theme(strip.text = element_text(face ="bold",size = rel(1.2)),strip.background = element_rect(fill ="lightblue",colour = "black",size = 0.5),axis.title =element_text(face = "bold"))+ylab("Conc. (ug/m3)")
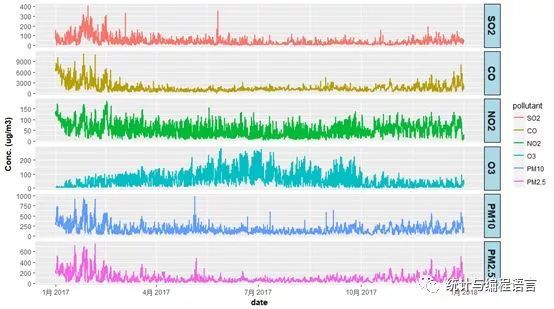
图11 各污染物分列的时间序列变化
使用ggplot2分面绘制各污染物的分季节日变化:
为了方便,我们可以直接借助先前利用timeVariation函数绘制的时间变化图获取每一类污染物的日变化数据
so2Output<-timeVariation(pollut,pollutant= "PM2.5",group = "season")
so2diurnal<-so2Output$data$hour
利用merge函数合并数据集(diurnalData)
diurnalData<-merge(so2diurnal,no2diurnal,all=TRUE)
查看数据:
head(diurnalData)

重命名第一列为季节
names(diurnalData)[1]<-"Season"
利用ggplot2(关于ggplot2的图形参数此处不再介绍)分面功能绘制各污染物分季节的日变化平均值:
ggplot(diurnalData,aes(x=hour,y=Mean,fill=Season))+geom_ribbon(aes(ymin=Lower,ymax=Upper),alpha=0.6)+geom_line(size=1.01)+facet_wrap(~pollutant,scales="free_y")+theme(axis.title.x=element_text(colour="black",face="bold"),axis.text.x= element_text(colour ="black"),axis.title.y=element_text(colour="black",face="bold"),axis.text.y= element_text(colour = "black"),strip.text = element_text(face ="bold",size = rel(1.05)),strip.background = element_rect(fill ="#d1eeee"),legend.position = "bottom")+scale_fill_manual(values=c("#CCCCFF","#CCFFCC","#99CCFF","#FFCCCC"),guide=guide_legend(title= NULL))+xlab("Local time (h)")+ylab("Mean and 95% confidenceinterval in mean")
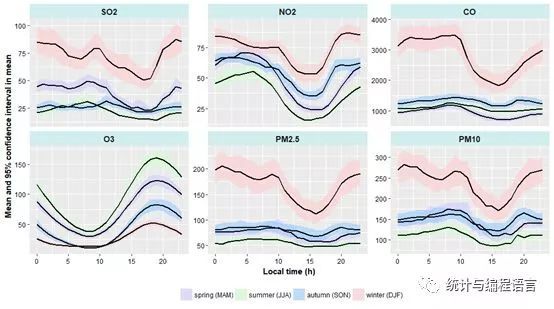
图12 各项污染物不同季节的日变化
4.污染物之间的关系
污染物之间存在一定的逻辑关系,如当局地以细颗粒物源排放为主时,PM2.5/PM10比值较高,且相关性较好;燃煤源贡献为主时,SO2/NO2比值较高,相关性较好等等。下面我们通过假定污染物之间存在线性关系来计算污染物之间比值的时间变化规律,使用linearRelation函数:linearRelation(pollut,x="SO2",y="NO2",period = "day.hour") #period还可以选择monthly, weekly等
linearRelation(pollut,x="PM10",y="PM2.5",period= "day.hour")
linearRelation(pollut,x="O3",y="NO2",period= "day.hour")
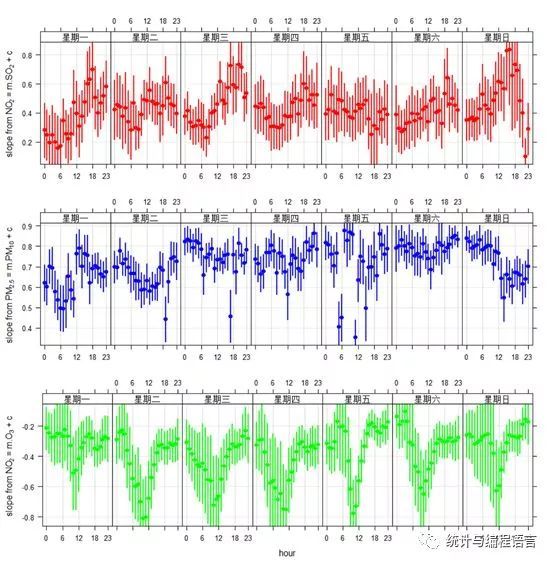
图13污染物之间的线性关系周-日变化
5.预测时间变化趋势
从前面的分析可以得知大气污染物的时间序列数据具有一定的周期性(包括明显的季节型波动、周-日变化等),由图14和15可见,PM2.5浓度ACF拖尾,PACF在1步截尾(p=1),说明PM2.5浓度的时间序列可能是平稳性时间序列,笔者情不自禁地想利用自回归滑动平均模型(ARMA)做时间变化趋势的预测分析,但当前爬取的数据集仅有一年的数据,不满足分析季节性因素的分解要求,后期积累的数据量足够时,笔者拟推出详细的时间变化预测建模。
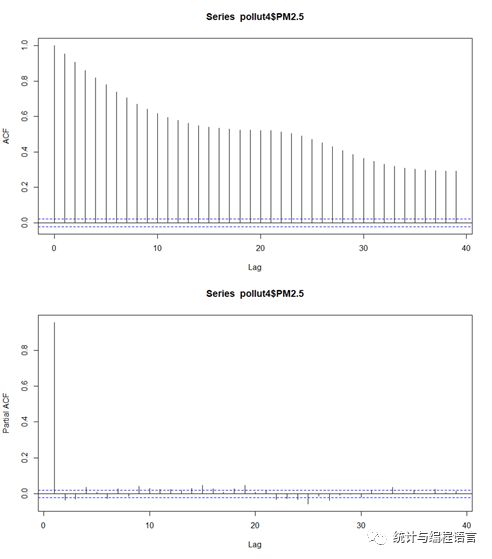
图14PM2.5的自相关图(ACF)和偏自相关图(PACF)


公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法