Transformer家族3 -- 计算效率优化(Adaptive-Span、Reformer、Lite-Transformer)
系列文章,请多关注
Transformer家族1 – Transformer详解和源码分析
Transformer家族2 – 编码长度优化(Transformer-XL、Longformer)
Transformer家族3 – 计算效率优化(Adaptive-Span、Reformer、Lite-Transformer)
Transformer家族4 – 通用性优化(Universal-Transformer)
Transformer家族5 – 推理加速(Faster-Transformer、TurboTransformers)
NLP预训练模型1 – 综述
1 背景
上文我们从编码长度优化的角度,分析了如何对Transformer进行优化。Transformer-XL、LongFormer等模型,通过片段递归和attention稀疏化等方法,将长文本编码能力提升到了很高的高度。基本已经克服了Transformer长文本捕获能力偏弱的问题,使得下游任务模型performance得到了较大提升,特别是文本较长(大于512)的任务上。
但Transformer计算量和内存消耗过大的问题,还亟待解决。事实上,Transformer-XL、LongFormer已经大大降低了内存和算力消耗。毕竟Transformer之所以长距离编码能力偏弱,就是因为其计算量是序列长度的平方关系,对算力需求过大,导致当前GPU/TPU不能满足需求。编码长度优化和计算量优化,二者是相辅相成的。但着眼于论文的出发点,我们还是分为两个不同的章节进行分析。毕竟总不能所有模型都放在一个章节吧(_)。
本文我们带来Adaptive-Span Transformer、Reformer、Lite-Transformer等几篇文章
2 Adaptive-Span Transformer

论文信息:2019年5月,FaceBook,ACL2019
论文地址 https://arxiv.org/pdf/1905.07799.pdf
代码和模型地址 https://github.com/facebookresearch/adaptive-span
2.1 为什么需要Adaptive-Span
之前Transformer-XL将长文本编码能力提升到了较高高度,但是否每个layer的每个head,都需要这么长的attention呢?尽管使用了多种优化手段,长距离attention毕竟还是需要较大的内存和算力。研究发现,大部分head只需要50左右的attention长度,只有少部分head需要较长的attention。这个是make sense的,大部分token只和它附近的token有关联。如下图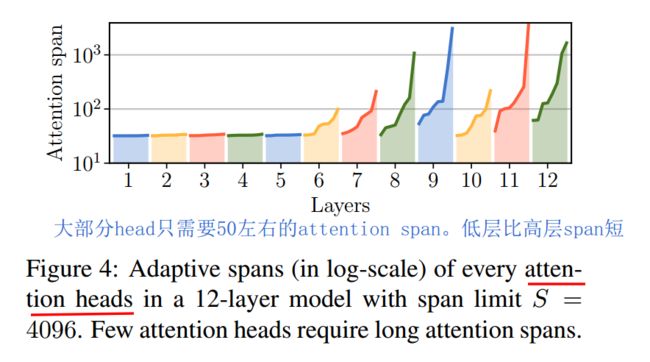 我们是否可以实现attention span长度的自适应呢?让不同的layer的不同的head,自己去学习自己的attention span长度呢?Adaptive-Span Transformer给出了肯定答案。
我们是否可以实现attention span长度的自适应呢?让不同的layer的不同的head,自己去学习自己的attention span长度呢?Adaptive-Span Transformer给出了肯定答案。
2.2 实现方案
文章设定每个attention head内的token计算,都使用同一个span长度。我们就可以利用attention mask来实现自适应span。对每个head都添加一个attention mask,mask为0的位置不进行attention计算。文章设计的mask函数如下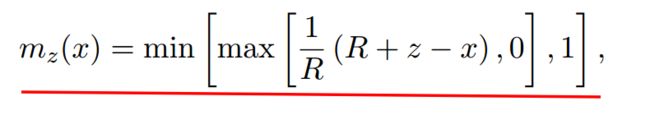
R为超参,控制曲线平滑度。其为单调递减函数,如下图。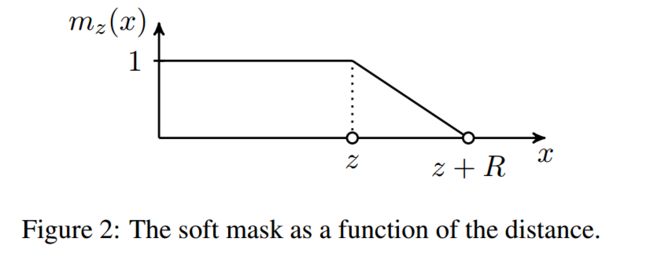
2.3 实验结果

和Transformer家族其他很多模型一样,Adaptive-span也在字符级别的语言模型上进行了验证,数据集为text8。如上,Transformer注意力长度固定为512,结论如下
- Transformer-XL长程编码能力确实很强,平均span可达3800。
- 注意力长度确实不需要总那么长,Adaptive-Span大模型上,平均长度只有245
- Adaptive-Span在算力需求很小(只有XL的1/3)的情况下,效果可以达到SOTA。
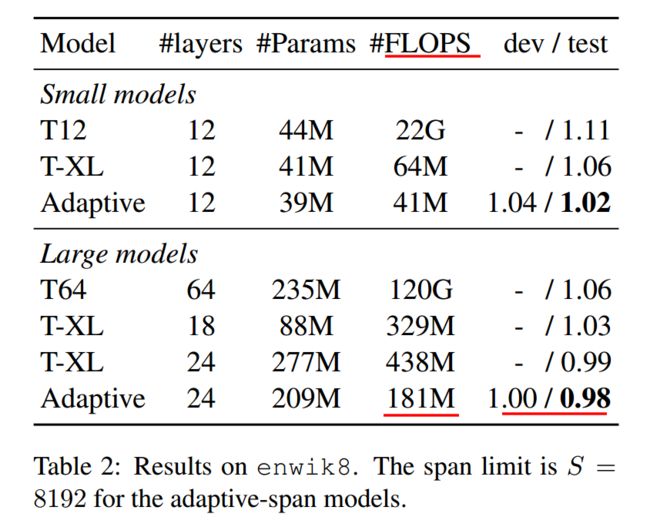 上面是在enwik8上的结果。Adaptive-Span又一次在算力很小的情况下,达到了最优效果。值得注意的是,64层的Transformer居然需要120G的计算量,又一次证明了原版Transformer是多么的吃计算资源。另外Transformer-XL在节省计算资源上,其实也算可圈可点。
上面是在enwik8上的结果。Adaptive-Span又一次在算力很小的情况下,达到了最优效果。值得注意的是,64层的Transformer居然需要120G的计算量,又一次证明了原版Transformer是多么的吃计算资源。另外Transformer-XL在节省计算资源上,其实也算可圈可点。
3 Reformer

论文信息:2020年1月,谷歌,ICLR2020
论文地址 https://arxiv.org/abs/2001.04451
代码和模型地址 https://github.com/google/trax/tree/master/trax/models/reformer
3.1 为什么需要Reformer
Transformer内存和计算量消耗大的问题,一直以来广为诟病,并导致其一直不能在长文本上进行应用。(BERT、RoBERTa均设置最大长度为512)。Reformer认为Transformer有三大问题
- attention层计算量和序列长度为平方关系,导致无法进行长距离编码
- 内存占用和模型层数呈N倍关系,导致加深Transformer层数,消耗的内存特别大
- feed-forward的dff比隐层dmodel一般大很多,导致FF层占用的内存特别大
针对这几个问题,Reformer创新性的提出了三点改进方案
- LOCALITY-SENSITIVE HASHING 局部敏感hash,使得计算量从 O(L^2)降低为O(L log L) ,L为序列长度
- Reversible Transformer 可逆Transformer,使得N层layers内存消耗变为只需要一层,从而使得模型加深不会受内存限制。
- Feed-forward Chunking 分块全连接,大大降低了feed-forward层的内存消耗。
Reformer是Transformer家族中最为关键的几个模型之一(去掉之一貌似都可以,顶多Transformer-XL不答应),其创新新也特别新颖,很多思想值得我们深入思考和借鉴。其效果也是特别明显,大大提高了内存和计算资源效率,编码长度可达64k。下面针对它的三点改进方案进行分析,有点难懂哦。
3.2 实现方案
3.2.1 LOCALITY-SENSITIVE HASHING 局部敏感hash
局部敏感hash有点难懂,Reformer针对Transformer结构进行了深度灵魂拷问
Query和Key必须用两套吗
Transformer主体结构为attention,原版attention计算方法如下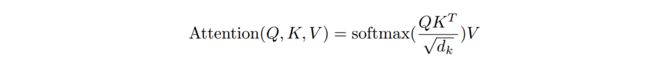
每个token,利用其query向量,和其他token的key向量进行点乘,从而代表两个token之间的相关性。归一化后,利用得到的相关性权重,对每个token的value向量进行加权求和。首先一个问题就是,query和key向量可以是同一套吗?我们可否利用key向量去和其他token的key计算相关性呢?
为此文章进行实验分析,证明是可行的。个人认为这一点也是make sense的。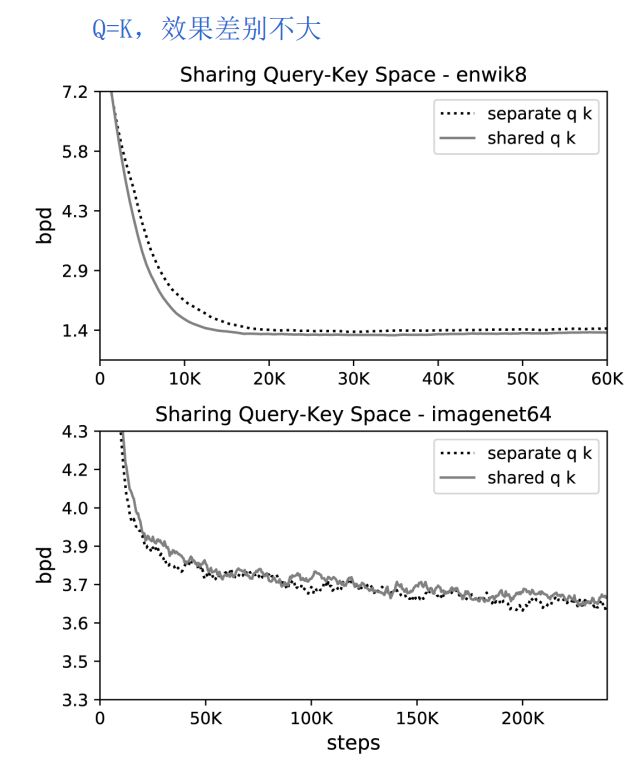 在文本和图像上,Q=K的attention,和普通attention,效果差别不大。
在文本和图像上,Q=K的attention,和普通attention,效果差别不大。
必须和每个token计算相关性吗
原版attention中,一个token必须和序列中其他所有token计算相关性,导致计算量随序列长度呈平方关系增长,大大制约了可编码最大长度。那必须和每个token计算相关性吗?其实之前Adaptive-Span Transformer也深度拷问过这个话题。它得出的结论是,对于大部分layer的multi-head,长度50范围内进行attention就已经足够了。不过Adaptive-Span采取的方法还是简单粗暴了一点,它约定每个head的attention span长度是固定的,并且attention span为当前token附近的其他token。
Adaptive-Span Transformer的这种方法显然还是没有抓住Attention计算冗余的痛点。Attention本质是加权求和,权重为两个token间的相关性。最终结果取决于较大的topk权重,其他权值较小的基本就是炮灰。并且softmax归一化更是加剧了这一点。小者更小,大者更大。为了减少计算冗余,我们可以只对相关性大的其他token的key向量计算Attention。
怎么找到相关性大的向量呢
我们现在要从序列中找到与本token相关性最大的token,也就是当前key向量与哪些key向量相关性大。极端例子,如果两个向量完全相同,他们的相关性是最高的。确定两个高维向量的相关性确实比较困难,好在我们可以利用向量Hash来计算。
Reformer采用了局部敏感hash。我们让两个key向量在随机向量上投影,将它们划分到投影区间内。
如图所示,划分了四个区间(4个桶bucket),进行了三次Hash。第一次Hash,使得上面两个向量分别归入bucket0和bucket3中,下面两个向量都归入bucket0。第二次Hash,上面两个向量和下面两个,均归入到bucket2中了。我们可以发现
- 相似的向量,也就是相关性大的,容易归入到一个bucket中
- 局部敏感Hash还是有一定的错误率的,我们可以利用多轮Hash来缓解。这也是Reformer的做法,它采取了4轮和8轮的Hash。
整个流程
经过局部敏感Hash后,我们可以将相关性大的key归入同一个bucket中。这样只用在bucket内进行普通Attention即可,大大降低了计算冗余度。为了实现并行计算,考虑到每个bucket包含的向量数目可能不同,实际处理中需要多看一个bucket。整个流程如下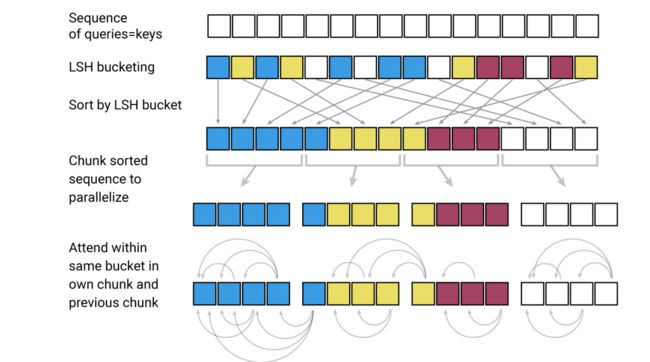
- 让query等于key
- 局部敏感Hash(LSH)分桶。上图同一颜色的为同一个桶,共4个桶
- 桶排序,将相同的桶放在一起
- 为了实现并行计算,将所有桶分块(chunk),每个chunk大小相同
- 桶内计算Attention,由于之前做了分块操作,所以需要多看一个块。
多轮LSH
为了减少分桶错误率,文章采用了多次分桶,计算LSH Attention,Multi-round LSH attention。可以提升整体准确率。如下表。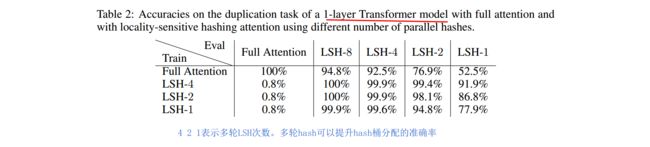
3.2.2 REVERSIBLE TRANSFORMER 可逆Transformer
LSH局部敏感Hash确实比较难理解,可逆Transformer相对好懂一些。这个方案是为了解决Transformer内存占用量,随layers层数线性增长的问题。为什么会线性增长呢?原因是反向传播中,梯度会从top layer向bottom layer传播,所以必须保存住每一层的Q K V向量,也就导致N层就需要N套Q K V。
那有没有办法不保存每一层的Q K V呢?可逆Transformer正是这个思路。它利用时间换空间的思想,只保留一层的向量,反向传播时,实时计算出之前层的向量。所以叫做Reversible。Reformer每一层分为两部分,x1和x2。输出也两部分,y1和y2。计算如下 由y1和y2,可以反向计算出x1和x2,
由y1和y2,可以反向计算出x1和x2,![]() 实操中,F为Attention,G为FeedForward,如下
实操中,F为Attention,G为FeedForward,如下 采用可逆残差连接后,模型效果基本没有下降。这也是make sense的,毕竟可逆是从计算角度来解决问题的,对模型本身没有改变。
采用可逆残差连接后,模型效果基本没有下降。这也是make sense的,毕竟可逆是从计算角度来解决问题的,对模型本身没有改变。
3.2.3 Feed-Forward chunking FF层分块
针对fead-forward层内存消耗过大的问题,Reformer也给出了解决方案,就是FF层分块。如下
3.3 实验结果
内存和时间复杂度
Reformer三个创新点,大大降低了内存和时间复杂度,消融分析如下
模型效果
如下为在机器翻译上的效果。Reformer减少了算力消耗,同时也大大增加了长文本编码能力,故模型效果也得到了提升。如下。
4 Lite Transformer

论文信息:2020年4月,MIT & 上海交大,ICLR2020
论文地址 https://arxiv.org/abs/2004.11886
代码和模型地址 https://github.com/mit-han-lab/lite-transformer
4.1 为什么要做Lite Transformer
主要出发点仍然是Transformer计算量太大,计算冗余过多的问题。跟Adaptive-Span Transformer和Reformer想法一样,Lite Transformer也觉得没必要做Full Attention,很多Attention连接是冗余的。不一样的是,它通过压缩Attention通道的方式实现,将多头减少了一半。与Base Transformer相比,计算量减少了2.5倍。并且文章使用了量化和剪枝技术,使得模型体积减小了18.2倍。
4.2 实现方案
实现方案很简单,仍然采用了原版Transformer的seq2seq结构,创新点为
- multiHead self-attention变为了两路并行,分别为一半的通道数(多头)。如下图a所示。其中左半部分为正常的fully attention,它用来捕获全局信息。右半部分为CNN卷积,用来捕获布局信息。最终二者通过FFN层融合。这个架构称为LONG-SHORT RANGE ATTENTION (LSRA),长短期Attention。
- 为了进一步降低计算量,作者将CNN转变为了一个depth wise卷积和一个线性全连接。dw卷积在mobileNet中有讲过,不清楚可自行谷歌。
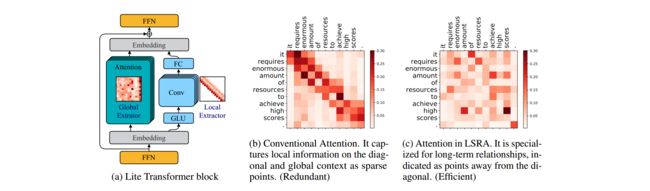
4.3 实验结果
计算复杂度

如上图,在文本摘要任务上,Lite Transformer计算量相比Base Transformer,减少了2.5倍。同时Rouge指标基本没变。
模型体积

Lite Transformer模型体积只有Transformer的2.5分之一,通过8bit量化和剪枝,最终模型体积下降了18.2倍。
5 其他
其他几篇文章,也建议拜读下
- Generating Long Sequences with Sparse Transformers (OpenAI, 2019.04)
- Adaptively Sparse Transformers (EMNLP2019, 2019.09)
- Compressive Transformers for Long-Range Sequence Modelling (2019.11)
- Transformer on a Diet (2020.02)
系列文章,请多关注
Transformer家族1 – Transformer详解和源码分析
Transformer家族2 – 编码长度优化(Transformer-XL、Longformer)
Transformer家族3 – 计算效率优化(Adaptive-Span、Reformer、Lite-Transformer)
Transformer家族4 – 通用性优化(Universal-Transformer)
Transformer家族5 – 推理加速(Faster-Transformer、TurboTransformers)
NLP预训练模型1 – 综述