这篇文章才是学习scrapy高效爬虫框架的正确姿势
文章目录
- 絮叨一下
- Scrapt五大基本构成
- 1.安装
- 2.新建项目
- 3.新建爬虫程序
- 4.项目目录结构
- 5.运行
- 6.解析数据
- 7.保存成json格式
- 8.scrapy shell 使用
- 9.模板的使用:crawlspider
- 10.post登陆
- 11.scrapy内置下载方法
- 下载文件 Files Pipeline
- 下载图片 Images Pipeline
- 12.下载器中间件
- 写给看到最后的你
絮叨一下
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常方便
Scrapt五大基本构成

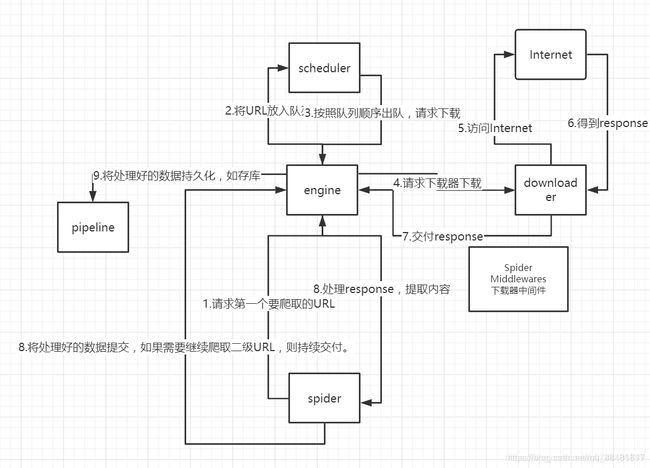
Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item
Pipeline)、Scrapy引擎(Scrapy Engine)。下面我们分别介绍各个组件的作用。(1)、调度器(Scheduler):
调度器,说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是
什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
- (2)、下载器(Downloader):
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
- (3)、 爬虫(Spider):
爬虫,是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。
用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
- (4)、 实体管道(Item Pipeline):
实体管道,用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
- (5)、Scrapy引擎(Scrapy Engine):
Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
如果还是不明白看一下csdn大佬整理的图
1.安装
-
linux下安装:
pip install scrapy安装一些依赖的文件
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
如果报错:说error: command 'x86_64-linux-gnu-gcc' failed with exit objectstatus 1那就输入命令:
sudo apt-get install python3.8-dev -
Windows安装:
pip install scrapy安装一些依赖的文件
pip install pypiwin32
2.新建项目
-
新建项目首先需要使用cd 切换进你想要存放的目录中然后输入:
scrapy startproject 项目名

3.新建爬虫程序
scrapy genspider 爬虫名 爬虫的域名注意不可以使用跟项目名重名

4.项目目录结构
-
items.py: 用来存放爬虫爬下来的数据的模型# 比如作者,以及内容 import scrapy class ZonghengItem(scrapy.Item): name = scrapy.Field() time = scrapy.Field() type = scrapy.Field() introduction = scrapy.Field() -
middlewares.py: 用来存放各种中间件的文件 -
pipelines.py: 将items的模型存储在本地磁盘中-
这里面有三个函数
使用的时候需要取消掉
settings.py中的ITEM_PIPELINES = { 'qsbk.pipelines.QsbkPipeline': 300, }# 用来处理获取的item数据 def process_item(self, item, spider): psaa # 打开爬虫的时候调用 def open_spider(self): pass # 关闭爬虫的时候调用 def close_spider(self): pass
-
-
settings.py: 本爬虫的一些配置信息 比如请求头,代理等
5.运行
- 1.使用终端进入项目目录后输入命令
scrapy crawl 爬虫名 - 2.新建一个py文件直接调用终端的方式
如果报错:from scrapy import cmdline cmdline.execute('scrapy crawl qsbk_spider'.split())ModuleNotFoundError: No module named '_cffi_backend'
使用命令:pip3 install cffi
6.解析数据
- 1.
getall()方法:获取Selector中的所有文本,返回是一个列表 - 2.
get()方法:获取Selector 中的第一个文本,返回的是一个str
7.保存成json格式
-
数据解析完毕之后,传给
pipline.py处理,可以使用yield返回
方法:from scrapy.exporters import JsonLinesItemExporter
JsonLinemExporter():每次调用item 的时候就会把item存储进硬盘中,每个字典是一行,不满足json格式栗子:
pipline.py:from scrapy.exporters import JsonLinesItemExporter class QsbkPipeline(object): def open_spider(self, spider): self.fp = open('item_json.json', 'wb') self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False, encoding='utf-8') def process_item(self, item, spider): self.exporter.export_item(item) return item def close_spider(self, spider): self.fp.close()
8.scrapy shell 使用
- 方便进行测试
- 进入项目中使用命令:scrapy shell ‘url’
9.模板的使用:crawlspider
- 创建项目:scrapy startproject 项目
- 创建爬虫:scrapy genspider -t crawl 爬虫名 url
- LinkExtractor()类:
- allow:允许的url地址
- deny:禁止的url地址
- allow_domanins:允许的域名
- deny_domanins:禁止的域名
- rule()类
- link_extractor:一个linkextractor对象用于定义爬虫的规则
- callback:满足这个url地址 应该执行那个回调函数
- follow:指定根据规则从response中提取的连接是否需要继续跟进
- process_links:从link_extractor中获得这个连接后传递给这个函数,用来过滤不需要爬的url
- 运行:scapy crawl 爬虫名
10.post登陆
- 使用request的子类FormRequest来实现,重写start_requests(self)方法,默认post请求
- 区分request以及formrequest
-
scrapy.Request(url=url,method=“POST”,body=formdata,cookies=self.cookie,headers=self.headers,callback=self.get_goods_list)
其中formdata 是字符串,需要使用json.dumps()进行格式的转换 method 默认是get请求,headers设置头文件,如果在setting中设置好了,这里可以省略,callback即为回调函数 -
scrapy.FormRequest(url=url,formdata=formdata,cookies=self.cookie,headers=self.headers,callback=self.get_goods_list),这里的formdata是dict格式的,里面不能存在数字,如果有数字用引号括起来;
-
- 举个例子:
模拟登录豆瓣:# 首先重写start_request方法 ,进行访问豆瓣并返回一个json def start_requests(self): yield scrapy.Request('https://www.douban.com/',callback=self.login) # 然后进行登录操作 def login(self,response): url = 'https://accounts.douban.com/j/mobile/login/basic' # 以dict 的形式进行封装 data = { "ck": "", "name": "Linux下撸python", "password": "12123123", "remember": "false", "ticket": "" } yield scrapy.FormRequest(url,formdata=data,callback=self.next)
11.scrapy内置下载方法
重用item pipelines 使用files pipeline 或者是 Images pipeline
- 优点:去重、异步下载效率高、方便指定文件的存储路径
下载文件 Files Pipeline
- 定义好Item 然后定义两个属性 分别是
file_urls和filesfiles_urls 是需要下载的url列表类型;files 用来接收文件下载的相关信息,下载路径等 - 在setting 中配置FILES_STORE 配置下载路径
- 在ITEM_PIPELINES 中设置scrapy.pipeines.files.FilesPipeline:1
下载图片 Images Pipeline
-
定义好Item 然后定义两个属性 分别是
images_urls和images跟Files Pipeline一样如果报错
ImportError: cannot import name '_imaging' from 'PIL' (/usr/lib/python3/dist-packages/PIL/__init__.py)请删除/usr/lib/python3/dist-packages/目录下的PIL 以及 pillow 然后pip3 install pillow进行从重新安装重写
file_path(self, request, response=None, info=None)在图片将要下载的时候会被调用,可以设置图片的存储路径def file_path(self, request, response=None, info=None): image_name = request.meta["item"]["img_name"] name = request.url name = name.split('/')[-1] path = image_name + '/' + name return path重写
get_media_requests(self,item,info)在下载图片的时候调用,发送下载请求 可以遍历 item中的image_urls 就是
for url in item[“image_urls”]:
yield Resquest(url, mate={"item":item})
```
12.下载器中间件
遇见反爬的网站,可以设置user-agent 以及 代理ip
两个类方法process_request(self,request,spider) 以及 process_response(self, request, response, spider)
- process_request(self,request,spider)
下载器发送请求的时候会被调用
返回None的时候:scrapy继续处理request 执行其他中间件
返回response的时候:不会在调用其他方法直接返回这个request
返回request的时候:不在使用之前的request而是使用新的request对象去下载数据
-
process_response(self, request, response, spider)
返回request的时候会将这个新的request传给其他中间件最终把数据返回给引擎
返回response的时候:下载器链被切断返回request会重新被下载器调度
-
举个例子
- 设置user-agent
# 修改 middlewares 中的 DownloadDownloaderMiddleware 类 def process_request(self, request, spider): User_Agent = ['Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36', 'Mozilla/5.0 (Linux; Android 8.1; PAR-AL00 Build/HUAWEIPAR-AL00; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/6.2 TBS/044304 Mobile Safari/537.36 MicroMessenger/6.7.3.1360(0x26070333) NetType/WIFI Language/zh_CN Process/tools', 'Mozilla/5.0 (Linux; Android 8.1.0; ALP-AL00 Build/HUAWEIALP-AL00; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/63.0.3239.83 Mobile Safari/537.36 T7/10.13 baiduboxapp/10.13.0.11 (Baidu; P1 8.1.0)', 'Mozilla/5.0 (Linux; Android 6.0.1; OPPO A57 Build/MMB29M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/63.0.3239.83 Mobile Safari/537.36 T7/10.13 baiduboxapp/10.13.0.10 (Baidu; P1 6.0.1)' ] user_agent = random.choice(User_Agent) # 随机获取一个ua request.headers['User_Agent'] = user_agent # 设置请求头- 设置ip代理
# 这个代理ip是我买的,还有一些可以用,分享给各位 response_ip = requests.get('http://api.xdaili.cn/xdaili-api//greatRecharge/getGreatIp?spiderId=5346c9f212dd40c5bb4813ae9ad8f7e7&orderno=YZ2020330130VXPyHU&returnType=2&count=1').content.decode() # 通过api调用接口返回数据后进行解析 ip_port = json.loads(response_ip)['RESULT'][0]['port'] ip ="http://"+ json.loads(response_ip)['RESULT'][0]['ip'] +':' + ip_port # 进行拼接ip 不要忘记了添加上http://或者是https:// request.meta['proxy'] = ip
写给看到最后的你
感谢你能看到最后,我想这便是给创作者的莫大鼓励
这篇文章只是一些基础的知识,我还在更新,毕竟还有很多要学.
公众号:Linux下撸python
期待和你再次相遇
愿你学的愉快
