一、代码练习
1.定义HybridSN

三维卷积部分:
-
conv1:(1, 30, 25, 25), 8个7x3x3 的卷积核 ==>(8, 24, 23, 23)
-
conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
-
conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
最后输出为 16 个节点,是最终的分类类别数。
代码如下:
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Conv3d(1,8,(7,3,3))
self.conv2 = nn.Conv3d(8,16,(5,3,3))
self.conv3 = nn.Conv3d(16,32,(3,3,3))
self.conv2d = nn.Conv2d(576,64,(3,3))
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.out = nn.Linear(128, class_num)
self.dropout = nn.Dropout(p=0.4)
def forward(self,x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = x.view(-1,x.shape[1]*x.shape[2],x.shape[3],x.shape[4])
x = F.relu(self.conv2d(x))
x = x.view(x.size(0),-1)
x = self.fc1(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
x = self.out(x)
return x
运行结果如下:
第一次运行:
accuracy 0.9498 9225
第二次运行:
accuracy 0.9786 9225
第三次运行:
accuracy 0.9560 9225
可以看到精确度浮动较大,说明网络并没有训练好,可能是因为训练数据过少导致的。
2. 基于学习率衰减的优化
将学习率设置为0.0001,并随着训练次数增加减少学习率
代码如下:
net = HybridSN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
def adjust_learning_rate(optimizer, lr):
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 开始训练
total_loss = 0
net.train()
for epoch in range(100):
lr = 0.0001
if epoch > 40:
lr = 0.00001
if epoch > 75:
lr = 0.000001
adjust_learning_rate(optimizer, lr)
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
第一次运行结果:
accuracy 0.9780 9225
第二次运行结果:
accuracy 0.9778 9225
第三次运行结果:
accuracy 0.9808 9225
第四次运行结果:
accuracy 0.9802 9225
第五次运行结果:
accuracy 0.9797 9225
可以看到精确度稳定在98%左右。
3. SENet实现
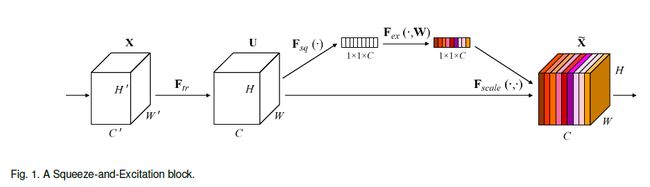
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。
代码如下:
class SELayer(nn.Module):
def __init__(self,channel,reduction=16):
super(SELayer,self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel,channel//reduction,bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel//reduction,channel,bias=False),
nn.Sigmoid()
)
def forward(self,x):
b,c,_,_ = x.size()
y = self.avg_pool(x).view(b,c)
y = self.fc(y).view(b,c,1,1)
return x*y.expand_as(x)
class HybridSN(nn.Module):
def __init__(self,reduction=16):
super(HybridSN, self).__init__()
self.conv1 = nn.Conv3d(1,8,(7,3,3))
self.conv2 = nn.Conv3d(8,16,(5,3,3))
self.conv3 = nn.Conv3d(16,32,(3,3,3))
self.conv2d = nn.Conv2d(576,64,(3,3))
self.se = SELayer(64,reduction)
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.out = nn.Linear(128, class_num)
self.dropout = nn.Dropout(p=0.4)
def forward(self,x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = x.view(-1,x.shape[1]*x.shape[2],x.shape[3],x.shape[4])
x = F.relu(self.conv2d(x))
x = self.se(x)
x = x.view(x.size(0),-1)
x = self.fc1(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
x = self.out(x)
return x
经过多次训练后,精确度基本维持在98%上下,相比于没有加SE模块的网络更加稳定,且精度有所上升。
SENet提升分类效果的原理:SENet通过对通道进行加权,强调有效信息,抑制无效信息,相当于对原始信息做了一次分类,从而使网络更加关注有效信息,减少对无效信息的关注,在训练样本较少的情况下能有效提高学习效果和学习效率。
二、视频学习
1. 语义分割中的自注意力机制与低秩重建
Attention机制继在NLP领域取得主导地位后,近两年在CV领域也取得了重要应用。率先将其引入的是Nonlocal。仅2018年,在语义分割领域就有多篇高影响力文章出炉,如 PSANet,DANet,OCNet,CCNet,以及今年的Local Relation Net。此外,针对 Attention 数学形式的优化,又衍生出A2Net,CGNL。而 A2Net 又开启了“低秩”重建的探索,同一时期的SGR,Beyonds Grids,GloRe,LatentGNN 都可以此归类。上述四文皆包含如下三步:1.像素到语义节点映射 2.语义节点间推理 3.节点向像素反映射。其中,step 2的意义尚未有对比实验验证,目前来看,step 1 & 3 构成的对像素特征的低秩重建发挥了关键作用。关于如何映射和反映射,又有了APCNet 和EMANet等相关工作。
Nonlocal
Nonlocal中的核心操作为:

结构图如下:

其实,这里f和g 的具体选择,对效果影响不大。在实验中,query和key共享,节省一些参数,并且这样计算出的 f 是个对称矩阵。甚至可以考虑将θ,Ф,σ 转换省略,直接用x本身计算,而把 1*1卷积放在模块之前之后,这样的效果也不逊色。当然,不同的任务应该对应于不同的最优选项。今年 arxiv 有篇文章详细对比分析了这些细节在不同任务中的影响。此处最关键的是加权平均,而非θ,Ф,σ转换。
这里f计算时,只考虑了像素的特征,而没有考虑相对位置。倘若也将像素坐标位置 (x,y)考虑进来,其实就是全图版的 MeanShift Filter,一种经典的保边滤波算法。Nonlocal 还可以溯源到经典的 Non-local means 和 BM3D。其功效也来源于此,即高维 feature map里存在大量的冗余信息,该类算法可以消除大量噪音。Kaiming 组的另一篇文章分析了 Nonlocal 对模型鲁棒性的提升,考虑到上述的去噪效果,这个结论是显而易见的。效果如下:

2. 图像语义分割前沿进展
自适应图像语义分割技术
图像语义分割技术目前面临大小各异、形状复杂、环境多变、类别众多的挑战。
ResNet通过跳层连接增加多尺度能力
2.1 从卷积出发提高卷积神经网络多尺度能力
富尺度空间的深度神经网络通用架构

右边结构增加了层类多尺度信息提取能力,且计算量要小于通常的神经网络架构。
可以与其他类型神经网络兼容。
2.2 从池化出发提高卷积神经网络多尺度能力
图像语义分割既需要细节又需要全局信息。
传统神经网络对细节信息提取较好,但对全局信息来说消耗资源非常多。
带状池化:使用条形的Pooling,可以得到各向异性的信息。
Strip Pooling模块
