一:事前准备工作:
1.最少4台服务器,当然也可以为虚拟机
2.hadoop、hbase、spark、jdk、zookeeper的安装包(需要版本都是相互兼容的,这个可以从官网看到)
3.系统为centos7
如果是新学者可以看我另一篇关于单节点大数据环境部署和安装的文章
二:Linux系统配置
更改linux名称
hostnamectl set-hostname host1(host1代表需要修改的主机名称) 修改后重启系统生效
配置/etc/hosts文件
192.168.23.128 host1
192.168.23.129 host2
192.168.23.130 host3
集群中的每一台节点都需要配置
同步linux系统时间
Linux系统各节点间时间差不能大于180秒,否则hbase会安装不上、也会出现别的问题
手工同步
date -s '2016-11-12 21:00' (系统时间设置) date查看系统时间
clock –w (将系统时间同步给硬件时间) hwclock 查看硬件时间
外网同步
1. 安装ntpdate工具
# yum -y install ntp ntpdate
2. 设置系统时间与网络时间同步
# ntpdate cn.pool.ntp.org
3. 将系统时间写入硬件时间
# hwclock --systohc
以集群主机为时间服务同步
可以参看博文:https://zhidao.baidu.com/question/627197261790582724.html
配置静态IP地址
使用以下步骤去配置CentOS7的网卡:
1.停用NetworkManager服务
#systemctl NetworkManager stop
#chkconfig NetworkManager off
2.编辑网卡配置文件(我虚拟机下网卡配置文件是ifcfg-eno16777736)
#vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
HWADDR=00:0c:29:14:34:51 #网卡MAC地址按照实际配置,刚安装好的系统不要动
TYPE=Ethernet #启用
BOOTPROTO=static #静态地址
NAME=eno16777736 #网卡名称
ONBOOT=yes #系统启动时加载网卡配置
IPADDR=192.168.1.100 #IP地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.1.1 #网关
DNS1=192.168.1.1 #DNS地址,也可修改/etc/resolv.conf
3.重启network服务(如果执行不了下面语句,则执行source 文件名,然后重启)
#systemctl network restart
建立hadoop生态圈集群运行帐号
sudo groupadd hadoop //设置hadoop用户组
adduser bigdata //添加bigdata用户
passwd bigdata //修改密码
usermod -g root bigdata //授予root权限
su bigdata //切换到bigdata用户
配置ssh免密码连入
每个结点分别产生公私密钥
ssh-keygen -t rsa 运行此语句,然后一直回车就好
cd /home/bigdata/.ssh 切换到秘钥目录
cat id_rsa.pub > authorized_keys 将公钥追加到authorized_keys文件中
单机回环ssh免密码登录测试
ssh localhost 测试是否已经可以无密钥登陆,

如果出现上面的信息,重新再ssh localhost试试
![]()
重启后ssh localhost 后,出现上面信息表示无密码登陆成功
让主结点(master)能通过SSH免密码登录两个子结点(slave)
拷贝master的id_rsa.pub文件至各子节点(默认已经切换到.ssh目录下)
scp id_rsa.pub bigdata@host2:/home/bigdata/.ssh
scp id_rsa.pub bigdata@host3:/home/bigdata/.ssh
各子节点将父节点拷贝的文件追加并生效
cat id_rsa.pub >>authorized_keys
测试无密钥连接(默认在主机服务器)
ssh host2 或者 ssh host3

三:安装Zookeeper
如果linux系统没有自带的安装jdk,那么在安装zookeeper之前必须先安装jdk,jps命令也依赖jdk
在/etc/profile.d目录下新建java.sh并添加以下内容
export JAVA_HOME=/home/bigdata/jdk7
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.ja
1. 上传zookeeper安装文件到主节点
直接将解压文件或者安装压缩包到主节点bigdata目录下
2. 创建/home/bigdata/data/zookeeper快照目录,并创建my id文件
这个目录必须和zookeeper/conf/ zoo.cfg文件的(dataDir=) 配置指是一致的。
myid文件内容为1(主节点为1,其它子节点为2、3、4等)
3. 修改/conf/zoo.cfg文件
主要修改dataDir和配置各服务节点值

如果conf下没有zoo.cfg文件则需要新建,新建文件内容如下
tickTime=2000
dataDir=/home/bigdata/zookeeper/
initLimit=5
syncLimit=2
clientPort=2181
server.1=host1:2888:3888
server.2=host2:2888:3888
4. 拷贝zookeeper安装目录和/home/bigdata/data目录至各子节点上
scp -r data/ bigdata@host2:/home/bigdata/
scp -r data/ bigdata@host3:/home/bigdata/
scp -r zookeeper/ bigdata@host2:/home/bigdata/
scp -r zookeeper/ bigdata@host3:/home/bigdata/
5.修改各子节点的/home/bigdata/data/zookeeper/myid文件值
Host2此文件修改值为2
Host3此文件修改值为3
5. N-1个节点启动zookeeper
在n-1个zookeeper中进入到zookeeper/bin目录下 执行./zkServer.sh start 命令进行启动

四:安装Hadoop
1. 上传hadoop安装文件至服务器
直接将解压文件或者安装压缩包到主节点bigdata目录下
2. 安装jdk
方法一:
切换到jdk-8u45-linux-i586.rpm文件所在目录,执行rpm –ivh jdk-8u45-linux-i586.rpm
方法二:
拷贝解压文件至/home/bigdata文件夹中,这里我是直接拷贝1.7的jdk文件,在/opt/jdk1.7.0_09目录中,接着配置JAVA_HOME宏变量及hadoop路径,这是为了方便后面操作,这部分配置过程主要通过修改/etc/profile文件来完成,在profile文件中添加如下几行代码:

然后执行: 
让配置文件立刻生效。上面配置过程每个结点都要进行一遍。
3. 配置namenode,修改site文件
1.目录准备
因为配置需要,所以在/home/bigdata/data目录下新建hadoop文件夹
mkdir hadoop
然后在其下面新建tmp和hdf文件夹
Mkdir tmp mkdir hdf
最后在hdf文件夹下新建 name和data两个文件夹
Mkdir data mkdir name
切换到hadoop/etc/hadoop目录下主要修改配置core-site.xml、hdfs-site.xml、mapred-site.xml这三个文件。
2.vim core-site.xml
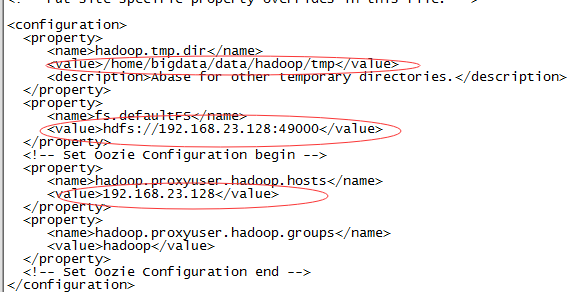
3.vim hdfs-site.xml

4. vim mapred-site.xml

5.修改yarn-env.sh

6.修改yarn-site.xml
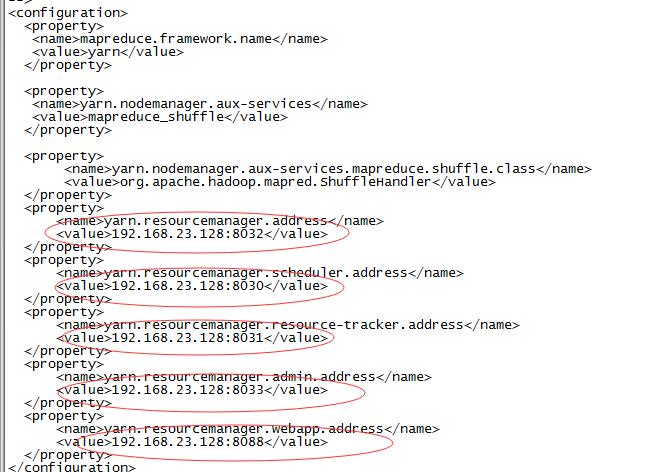
4.配置hadoop-env.sh文件
1. 新建logs和pid目录
在bigdata目录中新建logs目录和pid目录,然后在logs目录下新建hadoop目录
-
修改hadoop-env.sh文件



5.配置masters和slaves文件
1.vim masters
![]()
2.vim slaves
![]()
6.向各节点复制hadoop
1.拷贝pid目录
scp -r pid/ bigdata@host2:/home/bigdata
scp -r pid/ bigdata@host3:/home/bigdata
2.拷贝logs目录
scp -r logs/ bigdata@host2:/home/bigdata
scp -r logs/ bigdata@host3:/home/bigdata
3.拷贝hdp目录(hadoop目录)
scp -r hdp/ bigdata@host2:/home/bigdata
scp -r hdp / bigdata@host3:/home/bigdata
4.拷贝jdk目录
scp -r jdk7/ bigdata@host2:/home/bigdata
scp -r jdk7/ bigdata@host3:/home/bigdata
6. 格式化namenode
在格式化前需要在/etc/profile.d目录下设置环境变量 vim hadoop.sh 在空白文件中编写,然后source hadoop.sh文件,使其生效

因为原来不存在hadoop.sh文件,所以执行vim时会创建一个新的hadoop.sh,然后再新的文件中增加如下配置:
export HADOOP_HOME=/home/bigdata/hdp
export PATH=$PATH:$HADOOP_HOME/bin
格式化hadoop这一步在主结点master上进行操作:
1.hadoop namenode -format (主机上才执行namenode)

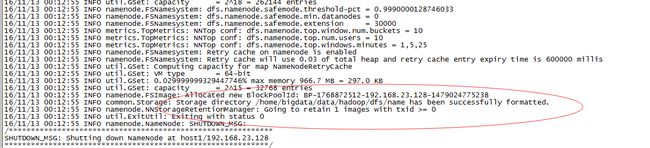
注意:上面只要出现“successfully formatted”就表示成功了。
2.hadoop datanode -format (每个子节点上执行)
8.启动hadoop
切换到/home/bigdata/hdp/sbin目录下执行./start-all.sh
在此过程中有权限问题一律用chmod 777 *
防火墙关闭 chkconfig iptables off
如果节点的datanode起不起来,报如下:
WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: host1/192.168.23.128:49000
就关掉防火墙就好了systemctl stop firewalld.service#停止firewall
systemctl disable firewalld.service#禁止firewall开机启动
9.查看集群情况
http://192.168.23.128:8088/cluster/scheduler
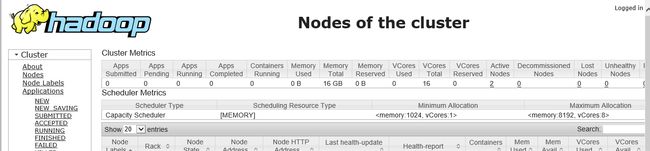
http://192.168.23.128:50070/
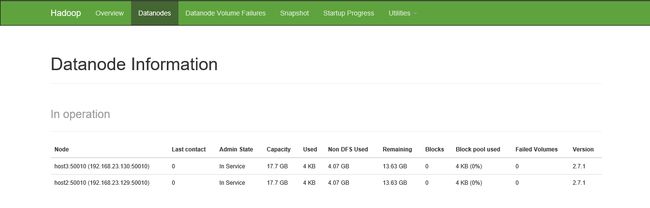
五:安装hbase
1.上传hbase安装文件至服务器
直接将解压文件或者安装压缩包到主节点bigdata目录下
2.修改hbase-env.sh
切换到/home/bigdata/hbase/conf目录下修改hbase-env.sh


3. 修改core-site.xml文件。

4.修改hbase-site.xml


5.修改regionservers

6.在hadoop中创建hbase目录
hadoop fs -mkdir /hbase/hbasedata
7. 将安装配置好的hbase目录复制到如上配置的两个节点中
scp –r hbase/ bigdata@host2:/home/bigdata/
scp –r hbase/ bigdata@host3:/home/bigdata/
8. 配置hbase shell快速启动
在/etc/profile.d/目录下新建hbase.sh,添加如下内容后保存、并执行source hbase.sh
export HBASE_HOME=/home/bigdata/hbase/
export PATH=$PATH:$HBASE_HOME/bin
9. 启动hbase集群
切换到/home/bigdata/hbase/bin目录下,执行 ./start-hbase.sh
也可以zkServer.sh start-foreground 输出日志启动方式
10. 查看hbase集群
http://192.168.23.128:16030/master-status
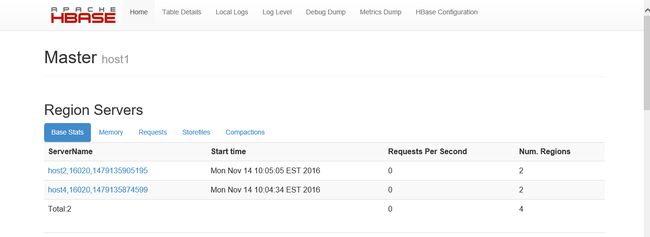
六:安装spark
1. 将spark安装文件上传到服务器
直接将解压文件或者安装压缩包到主节点bigdata目录下
2. 创建日志目录
在/home/bigdata/logs/目录下新建spark目录,并在新建目录下新建file.log文件
将/home/bigdata/logs/spark目录拷贝到其它节点上
scp –r spark bigdata@host2:/home/bigdata/logs/
scp –r spark bigdata@host2:/home/bigdata/logs/
3. 修改spark-env.sh
切换到/home/bigdata/spark/conf目录下,对spark-env.sh进行修改

4. 修改slaves

5. 修改log4j.properties

6. 将安装目录复制到其它节点
scp –r spark bigdata@host2:/home/bigdata/
scp –r spark bigdata@host2:/home/bigdata/
7. 启动spark集群
切换到/home/bigdata/spark/sbin目录下,启动spark
./start-all.sh
![]()
8. 查看spark集群
http://192.168.23.128:8080/

9.提交jar到集群作业
./spark-submit --master spark://host1:7077 --class main.scala.SparkTest /home/hadoop/spark/soft.jar
附言:
对于大数据分布式集群安装apache已经推了了一个叫ambari的自动安装开源插件,有兴趣的朋友可以去看看,地址为 http://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/