scrapy中spider和crawlspider的区别
spider和crawlspider都是用来实现数据解析的爬虫模块,但是还是有很大区别的.
原理来说都可以达到目的,但是应用情况嫩实现数量级的区别.
建立方式:
scrapy genspider 爬虫名 指定域
scrapy genspider -t crawl 爬虫名 指定域
spider有parse函数
crawl spider没有parse函数
crawl spider生成了一个rules,内含一个元祖或者列表,包含rule对象
rule标识规则,包含linkextractor,callback,follow等参数.
linkextractor连接提取器,可以通过正则,或者xpath或者css规则提取.
callback标识经过提取器取出来的url地址响应的回调函数,
重点是follow=true/falase 标识是否在当前页面中继续使用该规则进行深层提取.
如果一个被提取的url满足多个Rule,那么会从rules中选择一个满足匹配条件的Rule执行
另外,由于没有请求参数,crawlspider无法进行meta参数的传递,这就限制了他的一部分功能,比如下面的网页,这种
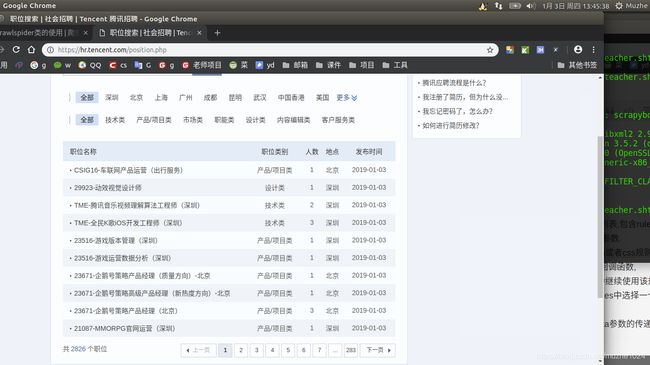
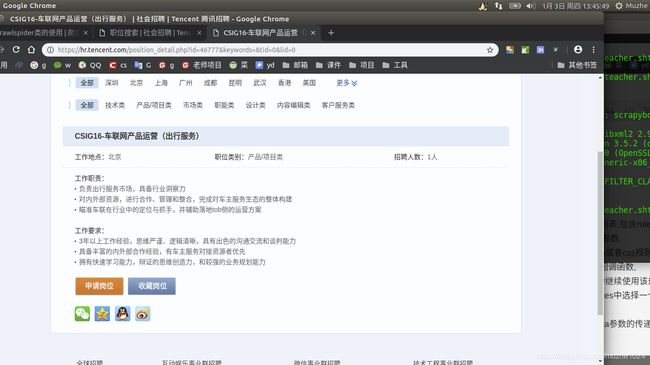
如果要求提取所有第二层页面中的职位发布信息,而且需要发布时间,用crawlspider提取的话,能很快匹配第二页数据,但是发布时间需要拼接,实现其来很麻烦,就不适合使用crawlspider,
如下图
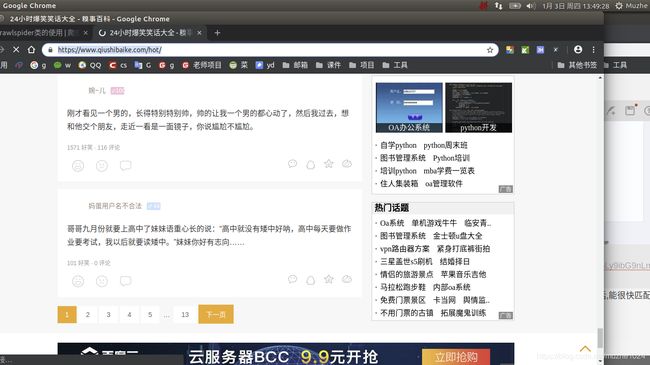
像这样的网站,数据都在同一个页面内,翻页后的数据格式页相同,用crawlspider就能实现快速的提取和翻页解析
注意:一般我们提取翻页信息会直接匹配"下一页"标签的链接,但是使用框架来爬取的时候,一般用匹配的是页数标签的链接,因为框架默认开启了多进程爬取,使用页数标签的连接进行解析,就相当于程序执行时候,就在1,2,3,4,5,13这些页面中解析,就是同时在进行6个页面的抓取,而用下一页的方法就只在两页中爬取,并且比如第五页连接内的页数标签内还会有性的页码,就会更快的执行完成整个项目.这是数量级的变化.