CUFFT库(cufft_C2C,cufft_R2C,cufft_C2R,cufft_Z2C,cufft_D2Z,cufft_Z2D)
CUDA的cufft库可以实现(复数C-复数C),(实数R-复数C)和(复数C-实数R)的单精度,双精度福利变换。其变换前后的输入,输出数据的长度如图所示。在C2R和R2C模式中,根据埃尔米特对称性(Hermitian symmetry),变换后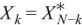 ,*代表共轭复数。CUFFT的傅里叶变换类型则利用了这些冗余,将计算量降到最低。
,*代表共轭复数。CUFFT的傅里叶变换类型则利用了这些冗余,将计算量降到最低。
注意:下表都是单精度(C-表示float复数,R表示float实数)。而双精度标识(Z表示double复数,D表示double实数)

下面分别给出示例程序:
(1)C2C(Z2Z)模式
1.单精度代码
#include"iostream"
#include"cuda_runtime_api.h"
#include"device_launch_parameters.h"
#include"cufft.h"
using namespace std;
//FFT反变换后,用于规范化的函数
__global__ void normalizing(cufftComplex* data, int data_len)
{
int idx = blockDim.x*blockIdx.x + threadIdx.x;
data[idx].x /= data_len;
data[idx].y /= data_len;
}
void Check(cudaError_t status)
{
if (status != cudaSuccess)
{
cout << "行号:" << __LINE__ << endl;
cout << "错误:" << cudaGetErrorString(status) << endl;
}
}
int main()
{
const int Nt = 256;
const int BATCH = 1;
//BATCH用于批量处理一批一维数据,当BATCH=2时
//则将0-1024,1024-2048作为两个一维信号做FFT处理变换
cufftComplex* host_in, *host_out, *device_in, *device_out;
//主机内存申请及初始化--主机锁页内存
Check(cudaMallocHost((void**)&host_in, Nt * sizeof(cufftComplex)));
Check(cudaMallocHost((void**)&host_out, Nt * sizeof(cufftComplex)));
for (int i = 0; i < Nt; i++)
{
host_in[i].x = i + 1;
host_in[i].y = i + 1;
}
//设备内存申请
Check(cudaMalloc((void**)&device_in, Nt * sizeof(cufftComplex)));
Check(cudaMalloc((void**)&device_out, Nt * sizeof(cufftComplex)));
//数据传输--H2D
Check(cudaMemcpy(device_in, host_in, Nt * sizeof(cufftComplex), cudaMemcpyHostToDevice));
//创建cufft句柄
cufftHandle cufftForwrdHandle, cufftInverseHandle;
cufftPlan1d(&cufftForwrdHandle, Nt, CUFFT_C2C, BATCH);
cufftPlan1d(&cufftInverseHandle, Nt, CUFFT_C2C, BATCH);
//执行fft正变换
cufftExecC2C(cufftForwrdHandle, device_in, device_out, CUFFT_FORWARD);
//数据传输--D2H
Check(cudaMemcpy(host_out, device_out, Nt * sizeof(cufftComplex), cudaMemcpyDeviceToHost));
//设置输出精度--正变换结果输出
cout << "正变换结果:" << endl;
cout.setf(20);
for (int i = 0; i < Nt; i++)
{
cout << host_out[i].x << "+j*" << host_out[i].y << endl;
}
//执行fft反变换
cufftExecC2C(cufftInverseHandle, device_out, device_in, CUFFT_INVERSE);
//IFFT结果是真值的N倍,因此要做/N处理
dim3 grid(Nt / 128);
dim3 block(128);
normalizing << > > (device_in, Nt);
//数据传输--D2H
Check(cudaMemcpy(host_in, device_in, Nt * sizeof(cufftComplex), cudaMemcpyDeviceToHost));
//设置输出精度--反变换结果输出
cout << "反变换结果:" << endl;
cout.setf(20);
for (int i = 0; i < Nt; i++)
{
cout << host_in[i].x << "+j*" << host_in[i].y << endl;
}
cin.get();
return 0;
} 2.双精度代码
#include"iostream"
#include"cuda_runtime_api.h"
#include"device_launch_parameters.h"
#include"cufft.h"
using namespace std;
//FFT反变换后,用于规范化的函数
__global__ void normalizing(cufftDoubleComplex* data,int data_len)
{
int idx = blockDim.x*blockIdx.x + threadIdx.x;
data[idx].x /= data_len;
data[idx].y /= data_len;
}
void Check(cudaError_t status)
{
if (status != cudaSuccess)
{
cout << "行号:" << __LINE__ << endl;
cout << "错误:" << cudaGetErrorString(status) << endl;
}
}
int main()
{
const int Nt =256;
const int BATCH = 1;
//BATCH用于批量处理一批一维数据,当BATCH=2时
//则将0-1024,1024-2048作为两个一维信号做FFT处理变换
cufftDoubleComplex* host_in, *host_out, *device_in, *device_out;
//主机内存申请及初始化--主机锁页内存
Check(cudaMallocHost((void**)&host_in, Nt * sizeof(cufftDoubleComplex)));
Check(cudaMallocHost((void**)&host_out, Nt * sizeof(cufftDoubleComplex)));
for (int i = 0; i < Nt; i++)
{
host_in[i].x = i + 1;
host_in[i].y = i + 1;
}
//设备内存申请
Check(cudaMalloc((void**)&device_in, Nt * sizeof(cufftDoubleComplex)));
Check(cudaMalloc((void**)&device_out, Nt * sizeof(cufftDoubleComplex)));
//数据传输--H2D
Check(cudaMemcpy(device_in, host_in, Nt * sizeof(cufftDoubleComplex), cudaMemcpyHostToDevice));
//创建cufft句柄
cufftHandle cufftForwrdHandle, cufftInverseHandle;
cufftPlan1d(&cufftForwrdHandle, Nt, CUFFT_Z2Z, BATCH);
cufftPlan1d(&cufftInverseHandle, Nt, CUFFT_Z2Z, BATCH);
//执行fft正变换
cufftExecZ2Z(cufftForwrdHandle, device_in, device_out, CUFFT_FORWARD);
//数据传输--D2H
Check(cudaMemcpy(host_out, device_out, Nt * sizeof(cufftDoubleComplex), cudaMemcpyDeviceToHost));
//设置输出精度--正变换结果输出
cout << "正变换结果:" << endl;
cout.setf(20);
for (int i = 0; i < Nt; i++)
{
cout << host_out[i].x<< "+j*" << host_out[i].y << endl;
}
//执行fft反变换
cufftExecZ2Z(cufftInverseHandle, device_out, device_in, CUFFT_INVERSE);
//IFFT结果是真值的N倍,因此要做/N处理
dim3 grid(Nt/128);
dim3 block(128);
normalizing << > > (device_in,Nt);
//数据传输--D2H
Check(cudaMemcpy(host_in, device_in, Nt * sizeof(cufftDoubleComplex), cudaMemcpyDeviceToHost));
//设置输出精度--反变换结果输出
cout << "反变换结果:" << endl;
cout.setf(20);
for (int i = 0; i < Nt; i++)
{
cout << host_in[i].x << "+j*" << host_in[i].y << endl;
}
cin.get();
return 0;
} #include"iostream"
#include"cuda_runtime_api.h"
#include"device_launch_parameters.h"
#include"cufft.h"
using namespace std;
#define Check(call) \
{ \
cudaError_t status = call; \
if (status != cudaSuccess) \
{ \
cout << "行号:" << __LINE__ << endl; \
cout << "错误:" << cudaGetErrorString(status) << endl; \
} \
}
//FFT反变换后,用于规范化的函数
__global__ void normalizing(cufftDoubleReal* data, int data_len)
{
int idx = blockDim.x*blockIdx.x + threadIdx.x;
if (idx> > (device_in, Nt);
//数据传输--D2H
Check(cudaMemcpy(host_in, device_in, Nt * sizeof(cufftDoubleReal), cudaMemcpyDeviceToHost));
//设置输出精度--反变换结果输出
cout << "反变换结果:" << endl;
cout.setf(20);
for (int i = 0; i < Nt; i++)
{
cout << host_in[i] << endl;
}
cin.get();
return 0;
}