hadoop和spark分布式集群搭建及简单运用
hadoop和spark分布式集群搭建及简单运用
-
- hadoop和spark分布式集群搭建及简单运用
- 1Hadoop集群部署
-
- 1-1Hadoop简介
- 1-2 环境及软件说明
- 1-2-1 虚拟机软件
- 1-2-2 JDK
- 1-2-3 Xshell
- 1-2-4 hadoop安装包
- 1-3 配置基础环境
- 1-3-1固定IP地址
- 1-3-2 安装配置JAVA环境
- 1-3-3 修改Hostname
- 1-4配置Hadoop
- 1-5 测试HDFS及存储数据
- 1-5-1存储数据
- 1-6 Yarn和MapReduce配置及程序设计
- 1-6-1配置计算调度系统Yarn和计算引擎MapReduce
- 1-6-2 MapReduce测试
- 1-6-3 Java开发MapReduce程序
-
- 2spark分布式集群搭建及设计
-
- 2-1 Spark配置
- 2-1-1 Scala配置
- 2-1-2 下载安装配置spark
- 2-1 Spark配置
-
- 3实验及结果对比分析与优化建议
-
- 3-1 MapReduce worldcount程序设计
- 3-2 spark worldcount程序设计
- 3-3实验结果及分析
- 3-3-1MapReduce运行结果
- 3-3-2 spark运行结果
-
- 1Hadoop集群部署
- hadoop和spark分布式集群搭建及简单运用
1Hadoop集群部署
1-1Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统HDFS(Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
1-2 环境及软件说明
我的环境是在虚拟机中配置的,Hadoop集群中包括4个节点:1个Master,3个Salve,节点之间局域网连接,可以相互ping通,节点IP地址分布如下:
虚拟机系统 机器名称 IP地址
Centos7 Master 172.16.153.53
Centos7 Salve1 172.16.153.54
Centos7 Salve2 172.16.153.55
Centos7 Slave3 172.16.153.56
Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;3个Salve机器配置DataNode 和TaskTracker的角色,负责分布式数据存储以及任务的执行。
1-2-1 虚拟机软件
VMware Workstation
1-2-2 JDK
jdk-8u91-linux-x64.rpm
1-2-3 Xshell
Xshell 5
1-2-4 hadoop安装包
hadoop-2.7.3.tar.gz
1-3 配置基础环境
1-3-1固定IP地址
命令vim /etc/sysconfig/network-scripts/ifcfg-ens33(防止重启后IP的变化)

1-3-2 安装配置JAVA环境
把jdk-8u91-linux-x64.rpm拷贝到/usr/local目录下,然后在local下执行rpm -ivh jdk-8u91-linux-x64.rpm命令进行jdk解压安装,会默认安装在/usr/java/目录下。

编辑/etc/profile文件,配置JAVA_HOME、PATH、CLASSPATH,保存后执行source /etc/profile命令使java环境变量配置生效。

1-3-3 修改Hostname
在centos7环境下,执行hostnamectl set-hostname master命令,将主机名称设置为master(重新登陆后生效:systemctl restart network)。

修改四台机器的/etc/host,让他们通过名字相互认识对方;关闭防火墙:systemctl stop fireward;废除防火墙:systemctl disable fireward;编辑/etc/hosts/文件,预先添加slave1、slave2、slave3

1-4配置Hadoop
把hadoop-2.7.3.tar.gz拷贝到/usr/local目录下,使用命名tar –xvf hadoop-2.7.2.tar.gz解压安装hadoop

修改hadoop-env.sh文件:
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改export JAVA_HOME 语句为 export JAVA_HOME=/usr/java/default(把jdk的位置告诉hadoop);
把hadoop执行命令的路径加到path环境中去:
vi /etc/profile
追加 export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin

执行source etc/profile使配置生效。
测试hadoop命令是否可以直接执行,任意目录下敲hadoop
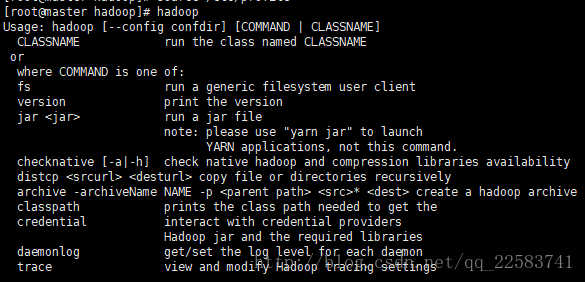
克隆3台slave后,修改/usr/local/hadoop/etc/hadoop/core-site.xml,保存完成后执行hdfs namenode -format格式化hdfs。(格式化仅在master中进行)

在master中启动namenode:命令hadoop-daemon.sh start namenode,命令jps查看是否启动成功
![]()
在slave中启动datanode:命令hadoop-daemon.sh start datanode,命令jps查看是否启动成功
![]()
由此hadoop最基础hdfs的环境搭建完成,由Namenode管理者三台DataNode,可以通过http://172.16.153.53:50070/web界面观察集群运行状况。

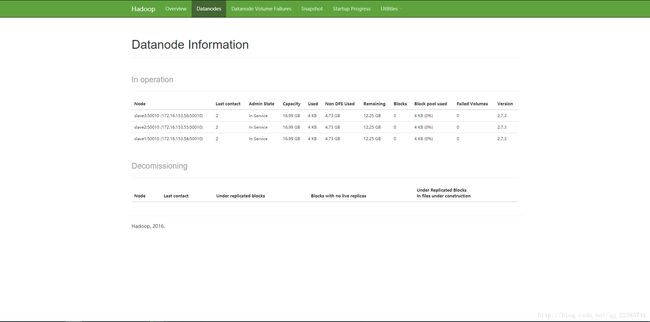
对集群进行集中式管理:修改master上/usr/local/hadoop/etc/hadoop/slaves文件,每一个slave占一行
slave1
slave2
slave3
由此可以在master上操作所有的slave;使用start-dfs.sh启动集群,并观察结果,使用stop-dfs.sh停止集群。
在master上配置免密SSH远程登陆:
ssh slave1
输入密码
exit
此时需要密码才能登陆
cd
ls -la
cd .ssh
ssh-keygen -t rsa (四个回车)
#会用rsa算法生成私钥id_rsa和公钥id_rsa.pub
ssh-copy-id slaveX(拷贝三份在其他slave上)
ssh-copy-id master(拷贝一份在自己master上)
再次ssh slave1
此时应该不再需要密码。
1-5 测试HDFS及存储数据
1-5-1存储数据
命令:hadoop fs -ls / 观察集群存储情况;往hdfs里面放数据如下:命令hadoop fs -put ./文件名;
使用hdfs dfs 或者hadoop fs命令对文件进行增删改查的操作
hadoop fs -ls /
hadoop fs -put file /
hadoop fs -mkdir /dirname
hadoop fs -text /filename
hadoop fs -rm /filename
1-6 Yarn和MapReduce配置及程序设计
1-6-1配置计算调度系统Yarn和计算引擎Map/Reduce
Yarn系统上Master上跑着RescueManager,slave上跑着NodeManager;
在master和slave上yarn-site.xml的配置:

通过Start-yarn.sh启动yarn集群

通过网页http://172.16.153.53:8088/观察yarn集群

master上配置mapred-site.xml(此文件没有,自己创建)。

1-6-2 MapReduce测试
find /usr/local/hadoop -name *example*.jar 查找示例文件
通过hadoop jar xxx.jar wordcount /input /output来运行示例程序
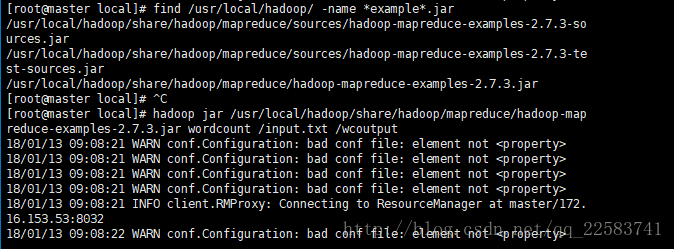


1-6-3 Java开发MapReduce程序
配置系统环境变量HADOOP_HOME,指向hadoop安装目录(如果你不想招惹不必要的麻烦,不要在目录中包含空格或者中文字符)把HADOOP_HOME/bin加到PATH环境变量(非必要,只是为了方便)
2spark分布式集群搭建及设计
2-1 Spark配置
2-1-1 Scala配置
下载安装配置Scala在master和slave上:下载地址为:http://www.scala-lang.org/files/archive/scala-2.10.3.tgz;执行如下命令:tar -zxvf scala-2.10.3和mv scala-2.10.3 scala;在/etc/profile 中增加环境变量SCALA_HOME,并使之生效:export SCALA_HOME=/usr/local/scala和export PATH=.: PATH: P A T H : SCALA_HOME/bin就此,Scala安装配置完毕。
2-1-2 下载安装配置spark
在master和slave进行如下配置,下载spark: spark-2.1.2-bin-hadoop2.7.tgz执行如下命令:
tar -zxvf spark-2.1.2-bin-hadoop2.7.tgz和mv spark-2.1.2-bin-hadoop2.7 spark,在/etc/profile 中增加环境变量SPARK_HOME,并使之生效:Export SPARK_HOME=/usr/local/spark和export PATH=.:$PATH:$SCALA_HOME/bin:$SPARK_HOEM/bin;修改spark-env.sh配置文件:cd /usr/local/spark和cp spark-env.sh.template spark-env.sh添加如下配置:SCALA_HOME=/usr/local/scala和JAVA_HOEM=/usr/local/jdk
修改conf/slaves文件;命令:cp slaves.temple slaves将计算节点的主机名添加到该文件,一行一个,slave1,slave2,slave3(每行一个slave),由此,spark环境配置完成,启动集群:
cd/usr/local/spark
sbin/start-all.sh
可以看到,在master上启动了一个名称为Master的进程,在slaves1和slaves2上启动了一个名称为Worker的进程,如下所示,我这里也启动了Hadoop集群:
主节点msater上:

slave节点上:

我们也可以通过网页观察spark集群状况:http://172.16.153.53:8080
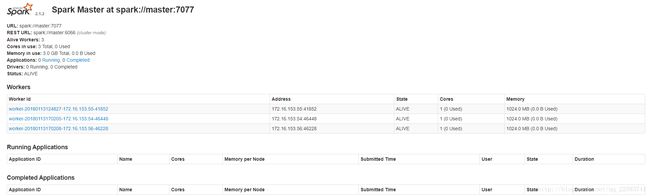
由此,spark的分布式环境基本搭建完成。
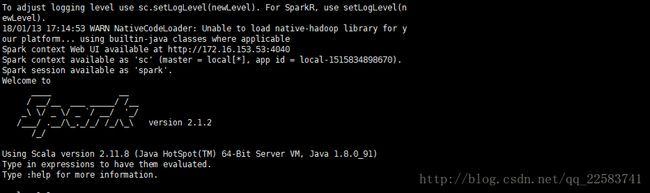
我们进入spark的bin目录,使用“spark-shell”控制台:
应该无错出现下面界面:
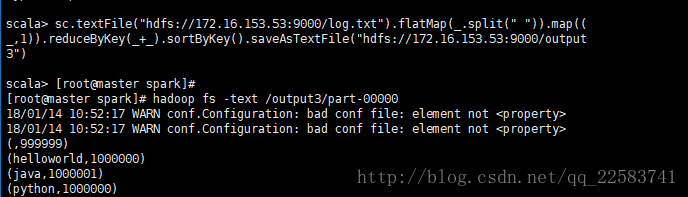
测试下:访问hdfs上的文件进行计算:sc.textFile("hdfs://172.16.153.53:9000/log.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortByKey().saveAsTextFile("hdfs://172.16.153.53:9000/output3")
3实验及结果对比分析与优化建议
3-1 MapReduce worldcount程序设计
把数据集Test.txt上传至hdfs分布式集群上,使用MapReduce的wordcount程序运行上传至hdfs的数据集,计算数据集中各个单词出现的次数。
3-2 spark worldcount程序设计
取到hdfs上的数据集Test.txt,同样使用spark的worldcount程序,计算出数据集中的各个单词出现的次数。
3-3实验结果及分析
Spark和MapReduce计算269.2MBTest.txt数据集,统计其中单词出现频率。
3-3-1MapReduce运行结果

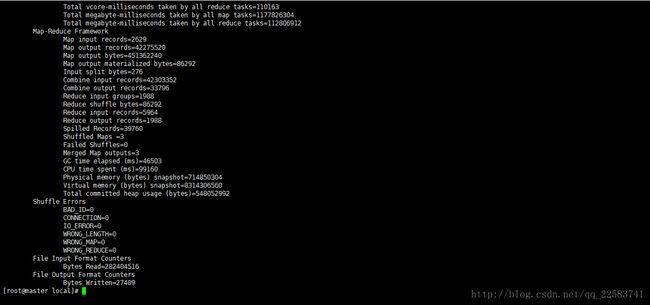


计算出结果大概花8分钟。
3-3-2 spark运行结果
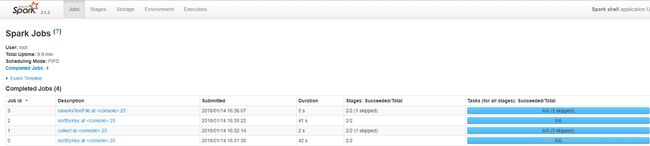

计算结果花了不到100秒。
由此我们可以得出结论,spark的运行速度远远比MapReduce快得多。