必须要掌握的面试重点——索引和事务(附讲B-树与B+树)
依托MySql说索引和事务
- 一,索引
- 1,概念
- 2,作用
- 3,到底什么才能作为索引(一定要看吆 B-树与B+树)
- 4,使用场景
- 5,使用
- 6, 面试相关问题
- 二,事务
- 1,为什么要使用事务
- 2,事物的概念
- 3,事物的四个基本特性
- 4,事务的使用
- 5,事物的相关面试题
一,索引
1,概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引, 并指定索引的类型,各类索引有各自的数据结构实现。
2,作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助。
3,到底什么才能作为索引(一定要看吆 B-树与B+树)
1)如果没有索引的话,此时的查找方式就是顺序遍历
2)在数据结构中,什么样的数据结构查找速度快快呢?
A.哈希表
B.二叉搜索树
思考:用哈希作为索引可行吗?
不太行
例如执行sql语句
select name from student
where id = 10;
类似这种情况的查找用hash完全可行
但是当执行sql语句为
select name from student
where id = '1%';
当遇到模糊匹配时,hash就无能为力了
因为hash查找需要明确知道key的值,
才能通过hash函数计算得到下标,进而查找到数据
针对模糊查询这样的场景,二叉搜索树是更合适的,
虽然不能确定到底是哪个key,
但是可以把相关所有结点都获取到
事实上,mysql中的索引结构,既不是使用hash表,也不是二叉搜索树,而是使用B+树(N叉搜索树)这样的结构
3)下面我们就来认识一下B+树
在认识B+树前先来简单了解一下B-树(注意念做B树,不是B减数)
如图所示为B-树:
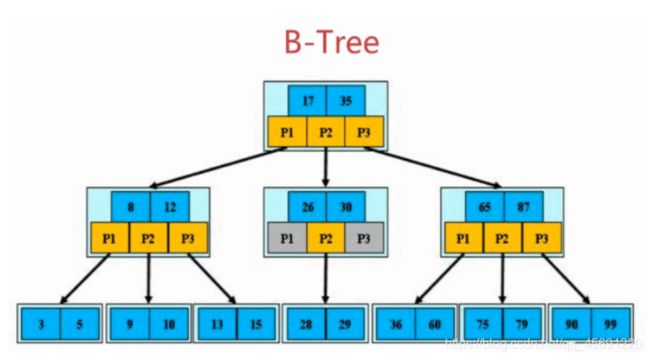
B-Tree中每个结点都可以存储多个数据,多个数据就划分出了一定的区间,进一步的数据结合着这样的区间来摆放
,使得树的高度更低,产找效率更高
如下图:B+树:

-
认识B+树:
1.B-树中非叶子结点可能存储数据,B+树数据一定在叶子节点上,非叶子结点只用来辅助进行查找
2.每一层兄弟结点之间都是连通的(类似于链表)(遍历起来更方便,尤其是指定区间查找的时候) -
B+树优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
4,使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引
5,使用
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建 对应列的索引。
注意:
主键索引与其他列的索引不太一样
- 主键索引中叶子节点存储的就是一条一条的记录,借助主键进行查找,依次到位就能完成查找
- 其他列索引存储的主键的id值,先根据索引找到主键id,在拿着主键id在主键索引中查找
所以通过主键索引查找的速率高于使用其它索引查找的速率
- 查看索引
show index from 表名;- 创建索引
create index 索引名 on 表名(字段名);- 删除索引
drop index 索引名 on 表名;
6, 面试相关问题
1)索引的背景是什么,索引解决了什么问题?
避免进行遍历,优化查询速度
2)索引工作原理
底层数据结构,B+树(最好还能描述B+树相关特点,和hash比有啥优势(能处理模糊匹配的问题),和二叉搜索树比有啥优势(高度更低,查找效率更高),和B树比有啥优势)
二,事务
1,为什么要使用事务
先建一张测试表
drop table if exists accout;
create table accout(
id int primary key auto_increment,
name varchar(20) comment '账户名称',
money decimal(11,2) comment '金额' );
insert into accout(name, money) values
('阿里巴巴', 5000),
('四十大盗', 1000);比如说,四十大盗把从阿里巴巴的账户上偷盗了2000元
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗'; 假如在执行以上第一句SQL时,出现网络错误,或是数据库挂掉了,阿里巴巴的账户会减少2000,但是 四十大盗的账户上就没有了增加的金额。
解决方案:使用事务来控制,保证以上两句SQL要么全部执行成功,要么全部执行失败。
2,事物的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
3,事物的四个基本特性
- 1,原子性
一个事务是一个不可分割的工作单位,其中包括的操作,要么就全部执行完,要么就一个都不做。
如果执行过程中,第一步成功了,第二步出现了问题,为了避免数据出现错误,往往都会进行回滚(rollback)
定义中一个都不做,不是真的没做,而是通过回滚把数据恢复了
- 2,一致性(正确性)
事务执行前后,数据要处在一种合法的情况
例如:
A卡内金额:5000
B卡内金额:1000
此时 A—>B 2000,
隐含条件:
1)转账之前和转账之后,都得保证AB卡内金额总数为6000
2)金额不能为负
- 3,持久性:
事务一旦被提交(执行完了),对于数据库的修改应该就是永久性的,接下来的其它操作/故障,都不会影响刚才事务的正确性。
事务1:A—B 1000
事务2:A—B1000
当事务1执行成功之后,后面无论出现什么极端情况(事务2无论咋样),都不会对事务1造成影响
- 4,隔离性
多个事务并发执行的时候,事物的内部操作和其它事物的内部操作是相互隔离的,没有影响
1)并发能提升程序的执行效率,如果在不影响数据正确性的前提下,我们还是希望尽可能的让多个操作(事务)并发执行
2)隔离性就是描述并发过程中所对应的一些问题
3)并发操作数据库可能带来的问题(这几个问题不仅仅是数据库中会出现,只要是并发编程中,都可能会涉及)
- 脏读
例:有AB两名同学,A在敲代码,B在看A敲代码,A写了一个类Student,定义了一个属性 String
name,然后B就离开了,A继续写最后在提交代码前又把name删了,此时B就发生了脏读,读到了脏数据,错误的数据。
此时我们对隔离性没有做出任何要求,于是就产生脏读了
为了避免脏读,在写操作的时候加锁(即写的时候不允许读,提高了隔离降性,也就降低了并发性)。
- 不可重复读
一个事务内读取两次数据的结果不一致
在写操作加锁的基础上:A写了一个Student类,定义了一个Sting name 属性,提交,之后同学们就看到了,看着看着,A修改了Student类,删除了name属性,再次提交,B更新代码后发现,咦,刚才看到的不见了!!
刚才对写操作加锁之后,虽然能够解决脏读问题,但是不可重复读问题依然存在,为了避免不可重复读,可以对读操作也加锁,(隔离性进一步提高,并发性进一步降低了)
- 幻读
同一个事务内多次查询返回的结果集不一样.
刚才给读加锁的时候,只是给"读Student"来加锁.此时我不能在你们读Student的时候修改Student.但是我可以改其他的类例如改Score类。
当我下次再提交代码的时候,同学们就会发现,刚才还没有Score这个类,现在咋就有了呢?
为了解决幻读问题还得进一步提高隔离性."串行化"
B读代码的时候A就去休息不要做任何修改(不只是Student,其他类也不要动).A在写代码的时候,B就去休息,啥都不要读.
并行就没了-(完全是串行执行)隔离性是最高的.多个事务之间不会有任何影响.
附加:
MySQL中的事务隔离级别(手动设置这个级别,调节并发性和隔离性)
-
read uncommitted允许读取未提交的数据,并行最大,隔离最低会产生脏读问题
-
read committed,只允许读取提交的数据,相当于写加锁,并行降低了- -点隔离提高了- -点 能够避免脏读问题,但是存在不可重复读
-
repeatable read,读写的时候都加锁,此时并行进一步降低 隔离进-步提高了,能够避免不可重复度问题,存在幻读问题(默认隔离级别)4. serializable,严格串行执行,隔离程度最高,并行程度最低,能够避免幻读问题.
4,事务的使用
(1)开启事务:start transaction;
(2)执行多条SQL语句
(3)回滚或提交:rollback/commit;
说明:rollback即是全部失败,commit即是全部成功。
start transaction;
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;
5,事物的相关面试题
1,你了解事务吗????
回答:
1)事物的背景(没有事务会有什么问题/事务解决的问 题)
2)事物的特性(4个特性)一定得按自己理解表达,不要背书
3)重点讲解隔离性
a)问题背景:并行和并发
b)并发事务中带来的问题:(3个问题)
c)每个问题该如何解决
d)mysql数据库中对应的隔离级别
事务的进阶问题:
1:事务该如何实现
2:你是否知道分布式系统中如何实现事务
3:如何实现跨行转账