ug902-ch1:High-Level Synthesis-Optimizing the Design
文章目录
- 1. Clock, Reset, and RTL Output
- 2. Optimizing for Throughput
- Function and Loop Pipelining
- Rewinding Pipelined Loops for Performance
- Flushing Pipelines
- Automatic Loop Pipelining
- Addressing Failure to Pipeline
- Static Variables
- Partitioning Arrays to Improve Pipelining
- Dependencies with Vivado HLS
- Removing False Dependencies to Improve Loop Pipelining
- Scalar Dependencies
- Optimal Loop Unrolling to Improve Pipelining
- 2.7 Exploiting Task Level Parallelism: Dataflow Optimization
- 2.7.1 canonical Form: 规范形式
- 2.7.2 Canonical Body
- 2.7.3 Dataflow Checking
- 2.7.4 Dataflow Optimization Limitations
- Single-producer-consumer Violations
- Bypassing Tasks
- Feedback Between Tasks
- Conditional Execution of Tasks
- Loops with Multiple Exit Conditions
- 2.7.5 Configuring Dataflow Memory Channels
- 2.7.6 Specifying Arrays as Ping-Pong Buffers or FIFOs
- 2.7.7 Specifying Compiler-FIFO Depth
- 2.7.8 Stable Arrays
- 2.7.9 Using ap_ctrl_none Inside the Dataflow
- 3 Optimizing for Latency
- 1.Using Latency Constraints
- 2.Merging Sequential Loops to Reduce Latency
- 3.Flattening Nested Loops to Improve Latency
- 4 Optimizing for Area
- 1.Data Types and Bit-Widths
- 2.Function Inlining
- 3.Mapping Many Arrays into One Large Array
- 4.Array Mapping and Special Considerations
- 5.Array Reshaping
- 6.Function Instantiation
- 7.Controlling Hardware Resources
- 5 Optimizing Logic
- 1.Controlling Operator Pipelining
- 2.Optimizing Logic Expressions
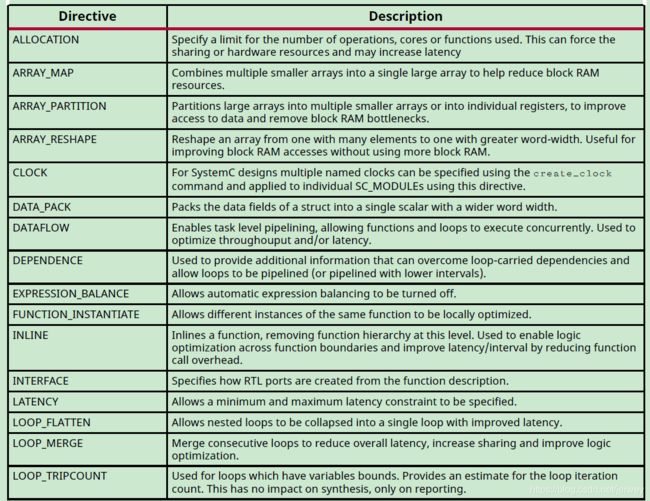
本节概述了可用于指导Vivado HLS生成满足所需性能和区域目标的微体系结构的各种优化和技术。 下表列出了Vivado HLS提供的优化指令。

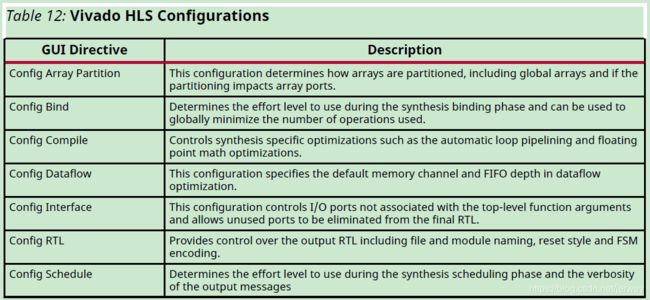
除了优化指令之外,Vivado HLS还提供了许多配置设置。配置设置用于更改合成的默认行为。配置设置如下表所示

除了优化指令之外,Vivado HLS还提供了许多配置设置。 配置设置用于更改综合的默认行为。 下表显示了配置设置。
有关如何应用优化和配置的详细信息在Applying Optimization Directives。
可以使用Solution→ Solution Settings → General ,并使用“Add ”按钮选择配置。
The Clock, Reset and RTL output are discussed together. The clock frequency along with the
target device is the primary constraint that drives optimization. Vivado HLS seeks to place as
many operations from the target device into each clock cycle. The reset style used in the final
RTL is controlled, along setting such as the FSM encoding style, using the config_rtl
configuration.
The primary optimizations for optimizing for throughput are presented together in the manner in
which they are typically used: pipeline the tasks to improve performance, improve the flow of
data between tasks, and optimize structures to improve address issues which may limit
performance.
Optimizing for latency uses the techniques of latency constraints and the removal of loop
transitions to reduce the number of clock cycles required to complete.
A focus on how operations are implemented - controlling the number of operations and how
those operations are implemented in hardware - is the principal technique for improving the area.
In addition to the pragmas and directives, Vivado HLS provides a way to integrate an existing
optimized RTL into the HLS design flow. See RTL Blackbox for more information.
1. Clock, Reset, and RTL Output
2. Optimizing for Throughput
使用以下优化来提高吞吐量或减少启动间隔(II)。
Function and Loop Pipelining
Pipelining应用对象:Functions 和 loops
作用:流水线允许操作并发发生:每个执行步骤不必在开始下一个操作之前完成所有操作
pipelining
| Function | loop | |
|---|---|---|
函数或循环是使用流水线指令实现流水线。指令是在构成函数或循环体的区域中指定的。初始化间隔(II)默认为1(如果没有指定),但是可以显式指定。
流水线仅应用于指定的区域,而不应用于下面的层次结构。但是,下面层次结构中的所有循环都会自动展开?。在指定函数下面的层次结构中的任何子函数都必须单独流水线。如果子函数是流水线的,则其上的流水线函数可以利用流水线的性能。
相反,流水线顶层函数之下的任何非流水线的子函数都可能成为流水线性能的限制因素。
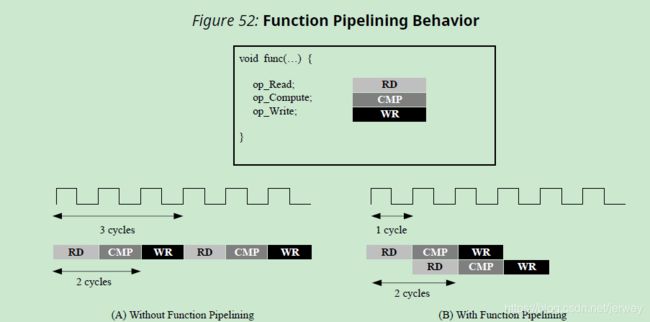
Functions and Loops 流水线方式的区别:
Function: 流水线将永远运行下去。
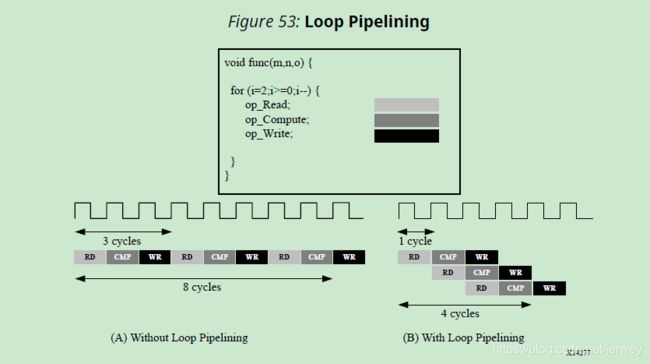
Loops: 管道将执行直到循环的所有迭代都完成为止。下图总结了这种行为差异
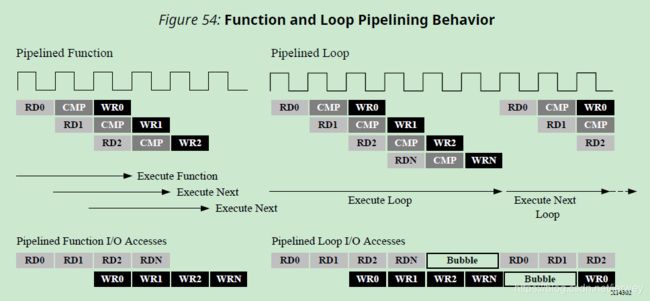
流水化的函数将不断地读取新的输入并写入新的输出。相反,因为一个loop必须在开始下一个循环之前先完成循环中的所有操作,a pipelined loop会在data stream;中产生“气泡bubble””。
Rewinding Pipelined Loops for Performance
PIPELINE pragma has an optional command “rewind”
为了避免前面图中显示的bubble问题,当此loop是top function or of a dataflow process的最外层结构时(且数据流区域被多次调用),此命令允许对rewind loop,的连续调用的迭代重叠。
当此循环是top函数或数据流进程的最外层构造(并且多次调用数据流区域)时,此命令将使重绕循环的连续调用的迭代重叠。
下图显示了在循环流水线化时使用rewind选项时的操作。在loop迭代计数结束时,loop开始重新执行。虽然它通常会立即重新执行,但延迟是可能的,并在GUI中显示和描述。
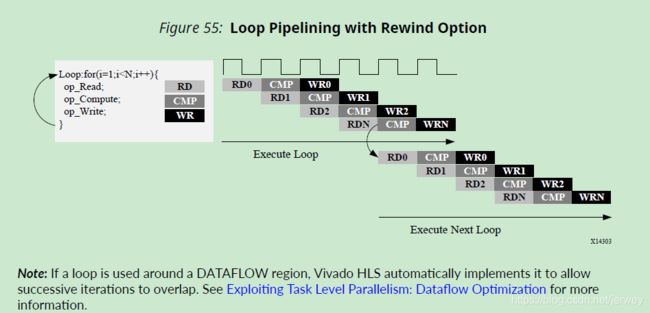
Flushing Pipelines
只要数据在管道的输入端可用,管道就会继续执行。如果没有可用的数据来处理,管道将会停止。
在某些情况下,希望有一个可以“emptied””或“flushed”的管道。提供了flush选项来执行此操作。
当一个pipeline被“flushed”,此pipeline停止读取新输入 当没有可用的(由pipeline开始处的数据有效信号确定)但继续处理,关闭每个连续的pipeline阶段,直到最终输入已处理到管道的输出为止。
Automatic Loop Pipelining
config_compile配置允许根据迭代计数自动地对循环进行流水线操作。Solution > Solution Settings >General > Add > config_compile.
pipeline_loops选项设置迭代限制。所有迭代计数低于此限制的循环都自动流水线。默认值为0:不执行自动循环管道操作。
for (y = 0; y < 480; y++) {
for (x = 0; x < 640; x++) {
for (i = 0; i < 5; i++) {
// do something 5 times
...
}
}
}
如果pipeline_loops选项被设置为6,那么上面代码段中最内层的for循环将被自动流水线化。这相当于下面的代码片段:
for (y = 0; y < 480; y++) {
for (x = 0; x < 640; x++) {
for (i = 0; i < 5; i++) {
#pragma HLS PIPELINE II=1
// do something 5 times
...
}
}
}
如果在设计中有不希望使用automatic pipelining的loops,请将带有off选项的管道指令应用于该loop。
off选项防止automatic loop pipelining.
IMPORTANT!
Vivado HLS在执行所有用户指定的指令之后应用config_compile pipeline_loops选项。例如,如果Vivado HLS将用户指定的UNROLL指令应用于循环,则首先将循环展开,并且不能应用自动循环管道。
Addressing Failure to Pipeline
当一个函数被流水线操作时,下面层次结构中的所有循环都会自动展开。这是进行管道操作的必要条件。如果循环有可变边界,则无法展开。这将阻止函数被流水线化。
Static Variables
静态变量用于在循环迭代之间保持数据,通常在最终实现中产生寄存器。 如果在流水线函数中遇到这种情况,vivado_hls可能无法充分优化设计,这会导致启动间隔超过所需时间。
Partitioning Arrays to Improve Pipelining
数组被实现为块RAM,它最多只有两个数据端口。这可能会限制读/写(或加载/存储)密集型算法的吞吐量。通过将数组(一个块RAM资源)分割成多个较小的数组(多个块RAM),可以提高带宽,从而有效地增加端口的数量。使用ARRAY_PARTITION指令对数组进行分区。Vivado HLS提供三种类型的数组分区,如下图所示。划分的三种风格是:
block:原始数组被分割成大小相等的块,这些块由原始数组中连续的元素组成。
cyclic:原始数组被分割成大小相等的块,将原始数组的元素交错排列。
complete:默认操作是将数组拆分为各个元素。这相当于将存储解析为寄存器。
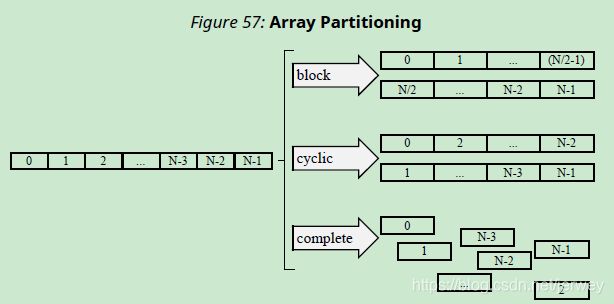
对于block分区和cyclic分区,factor选项指定要创建的数组数量。在前面的图中,使用了因子2,即将数组分成两个较小的数组。如果数组中的元素数不是因子的整数倍,则最后数组的元素数较少。
在对多维数组进行分区时,使用dimension选项指定要分区的维度。下图显示了如何使用dimension选项来划分以下示例代码:
void foo (...) {
int my_array[10][6][4];
...
}
如果dimension=0,则对所有维度进行分区。

数组自动分区
config_array_partition配置决定如何根据元素的数量对数组进行自动分区。可以通过菜单访问此配置
Solution → Solution Settings → General → Add → config_array_partition.
可以调整分区阈值,并且可以使用throughput_driven选项完全自动化分区。当选择了throughput_driven选项时,Vivado HLS会自动对数组进行分区,以实现指定的吞吐量。
Dependencies with Vivado HLS
Removing False Dependencies to Improve Loop Pipelining
Scalar Dependencies
一些标量依赖关系很难解决,通常需要对源代码进行更改。
Optimal Loop Unrolling to Improve Pipelining
默认情况下,loops在Vivado HLS中保持rolled。
Vivado HLS提供了使用unroll指令展开for循环或部分展开for循环的能力
本例假设数组a[i]、b[i]和c[i]被映射到块ram。
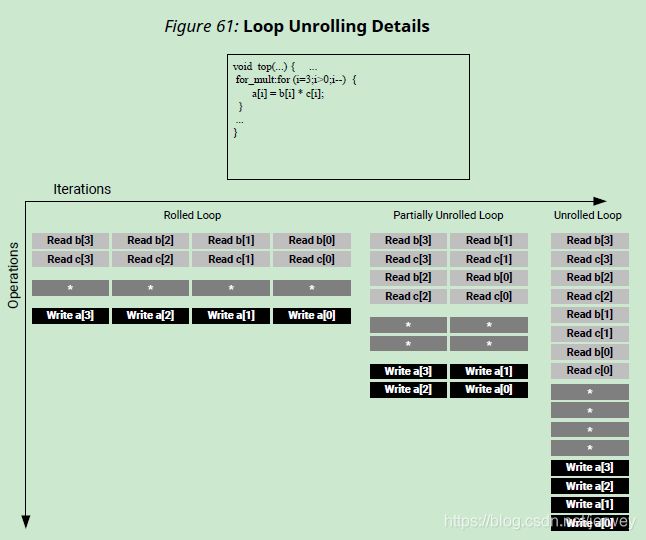
- Rolled Loop:这个实现需要四个时钟周期,只需要一个乘法器,每个块RAM可以是一个单端口块RAM。
- Partially Unrolled Loop:在本例中,循环部分展开的系数为2。这个实现需要两个乘法器和双端口RAM来支持在同一个时钟周期内对每个RAM进行两次读写。然而,这个实现只需要两个时钟周期就可以完成:一半的启动间隔和一半的滚动循环版本的延迟。
- 展开循环:在完全展开的版本中,所有的循环操作都可以在一个时钟周期内执行。然而,这个实现需要四个乘数。更重要的是,这个实现需要在相同的时钟周期中执行4个读和4个写操作。因为一个块RAM最多只有两个端口,所以这个实现需要对数组进行分区。
使用范围:
要执行循环展开,可以将UNROLL指令应用于设计中的各个loops。或者,您可以将UNROLL指令应用于一个function,该function将在该function的范围内展开所有循环。
如果循环是完全展开的,那么在数据依赖项和资源允许的情况下,所有操作都将并行执行。如果循环的一个迭代中的操作需要前一个迭代的结果,那么它们不能并行执行,而是在数据可用时立即执行。一个完全展开和完全优化的循环通常会涉及循环体中逻辑的多个副本。
Partially unrolling the loop by a factor of 8 will allow each of the channels (every 8th sample) to be processed in parallel (if the input and output arrays are also partitioned in a cyclic manner to allow multiple accesses per clock cycle). If the loop is also pipelined with the rewind option, this design will continuously process all 8 channels in parallel if called in a pipelined fashion (i.e., either at the top, or within a dataflow region).
void foo (dout_t d_out[N], din_t d_in[N]) {
#pragma HLS ARRAY_PARTITION variable=d_i cyclic factor=8 dim=1 partition
#pragma HLS ARRAY_PARTITION variable=d_o cyclic factor=8 dim=1 partition
int i, rem;
// Store accumulated data
static dacc_t acc[CHANNELS];
// Accumulate each channel
For_Loop: for (i=0;i。。。
2.7 Exploiting Task Level Parallelism: Dataflow Optimization
Dataflow Optimization对于一组连续的任务(例如,functions and/or loops)非常有用,如下图所示。
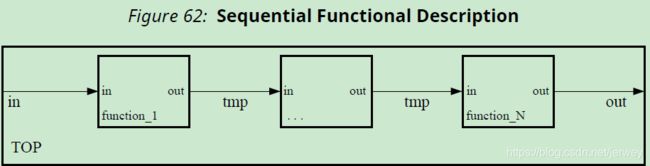
上面的图显示了三个任务链的具体情况,但是通信结构可能比显示的更复杂。
使用这一系列连续的任务,dataflow优化创建了一个并发进程的体系结构,如下所示。数据流优化是一种提高设计吞吐量和延迟的强大方法。
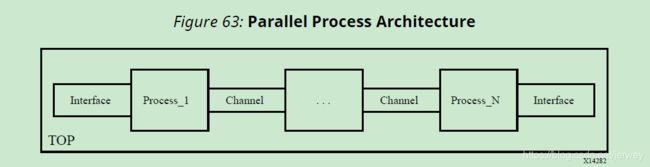

如果不增加硬件开销,就无法实现这种并行。
当某个特定区域(如函数体或循环体)被标识为应用dataflow优化的区域时,Vivado HLS将分析该函数或循环体并创建单独的通道来对数据流建模,从而将每个任务的结果存储在数据流区域中。
这些channels对于scalar variables可以是简单的fifo,对于非标量变量(比如数组)可以是ping-pong (PIPO) buffers。
每个通道还包含指示FIFO或乒乓缓冲区何时满或空的信号。这些信号表示完全由数据驱动的握手接口。
通过使用单独的fifo和/或ping-pong缓冲区,Vivado HLS释放每个任务以其自己的速度执行,并且吞吐量仅受输入和输出缓冲区的可用性限制。与普通流水线实现相比,这允许更好的任务执行交错,但这是以额外的FIFO 或 用于乒乓球缓冲区的块RAM寄存器为代价的。上图说明了下图中相同示例的数据流区域实现的结构。
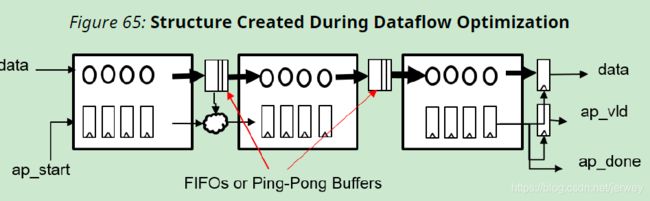
与静态流水线解决方案statically pipelined solution相比,Dataflow优化有可能提高性能。 Dataflow使用FIFO和/或乒乓缓冲区,以更灵活和分布式的握手体系结构代替了严格的集中控制流水线停顿原理。数据流优化不限于一系列流程,而是可以在任何DAG结构上使用。 它可以产生两种不同的重叠形式:在迭代中(如果进程与FIFO连接),以及通过PIPO和FIFO在不同的迭代之间进行。
2.7.1 canonical Form: 规范形式
Vivado HLS变换区域以应用DATAFLOW优化。 Xilinx建议使用规范形式在该区域(称为规范区域)内编写代码。 数据流优化有两种主要的规范形式:
1.不内联函数的函数的规范形式。
void dataflow(Input0, Input1, Output0, Output1)
{
#pragma HLS dataflow
UserDataType C0, C1, C2;
func1(read Input0, read Input1, write C0, write C1);
func2(read C0, read C1, write C2);
func3(read C2, write Output0, write Output1);
}
2. Loop body中的Dataflow
For the for loop (where no function inside is inlined), the integral loop variable should have:对于For循环(其中没有内联函数),整环变量应该有:
a. 在循环头中声明并设置为0的初始值
b. 循环条件是一个正的常数值或常数函数参数
c. 以1递增.
d. Dataflow pragma需要在循环内部.
void dataflow(Input0, Input1, Output0, Output1){
for (int i = 0; i < N; i++){
#pragma HLS dataflow
UserDataType C0, C1, C2;
func1(read Input0, read Input1, write C0, write C1);
func2(read C0, read C0, read C1, write C2);
func3(read C2, write Output0, write Output1);
}
}
2.7.2 Canonical Body
在规范区域内,规范主体应遵循以下准则
- Use a local, non-static scalar or array/pointer variable, or local static stream variable. A local
variable is declared inside the function body (for dataflow in a function) or loop body (for
dataflow inside a loop). - A sequence of function calls that pass data forward (with no feedback), from a function to
one that is lexically later, under the following conditions:
a. Variables (except scalar) can have only one reading process and one writing process.
b. Use write before read (producer before consumer) if you are using local variables, which
then become channels.
c. Use read before write (consumer before producer) if you are using function arguments.
Any intra-body anti-dependencies must be preserved by the design.
d. Function return type must be void.
e. No loop-carried dependencies among different processes via variables.
• Inside the canonical loop (i.e., values written by one iteration and read by a following
one).
• Among successive calls to the top function (i.e., inout argument written by one
iteration and read by the following iteration).
2.7.3 Dataflow Checking
Vivado HLS有一个dataflow 检查器,当启用该检查器时,它将检查代码是否符合建议的规范形式(canonical form)。否则它将向用户发出错误/警告消息。默认情况下,此检查器设置为警告。您可以通过在config_dataflow TCL命令的严格模式中选择off来将检查器设置为error或禁用它
config_dataflow -strict_mode (off | error | warning)
2.7.4 Dataflow Optimization Limitations
DATAFLOW优化可优化任务(功能和循环)之间的数据流,理想情况下可优化流水线化的功能和循环,以实现最佳性能。 不需要将这些任务一个接一个地链接起来,但是在数据传输方式上有一些限制。
以下行为可以阻止或限制Vivado HLS通过DATAFLOW优化执行的重叠:
• Single-producer-consumer violations违规
• Bypassing tasks
• Feedback between tasks
• Conditional execution of tasks
• Loops with multiple exit conditions
IMPORTANT! 如果存在任何这些编码样式,Vivado HLS将发出一条消息来描述这种情况。
Note: The dataflow viewer in the Analysis Perspective may be used to view the structure when the DATAFLOW directive is applied.
分析透视图中的数据流查看器可用于在应用DATAFLOW 指令时查看结构。
。。。
Single-producer-consumer Violations
Vivado HLS要执行数据流优化,在任务之间传递的所有元素必须遵循单生产者-消费者模型。每个变量必须从单个任务中驱动,并且只能由单个任务使用。在下面的代码示例中,temp1展开并被Loop2和Loop3使用。这违反了单一生产者-消费者模式。
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N];
Loop1: for(int i = 0; i < N; i++) {
temp1[i] = data_in[i] * scale;
}
Loop2: for(int j = 0; j < N; j++) {
data_out1[j] = temp1[j] * 123;
}
Loop3: for(int k = 0; k < N; k++) {
data_out2[k] = temp1[k] * 456;
}
}
改进版本使用函数分割function Split来创建单生产者-消费者设计。在这种情况下,数据从loop1流到函数分割,然后流到loop2和loop3。现在数据在所有4个任务之间流动,Vivado HLS可以执行数据流优化。
void Split (in[N], out1[N], out2[N]) {
// Duplicated data
L1:for(int i=1;i<N;i++) {
out1[i] = in[i];
out2[i] = in[i];
}
}
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N], temp2[N]. temp3[N];
Loop1: for(int i = 0; i < N; i++) {
temp1[i] = data_in[i] * scale;
}
Split(temp1, temp2, temp3);
Loop2: for(int j = 0; j < N; j++) {
data_out1[j] = temp2[j] * 123;
}
Loop3: for(int k = 0; k < N; k++) {
data_out2[k] = temp3[k] * 456;
}
}
Bypassing Tasks
Feedback Between Tasks
当一个任务的输出被DATAFLOW区域中的前一个任务使用时,将发生反馈。在DATAFLOW区域中不允许任务之间的反馈。当Vivado HLS检测到反馈时,它会根据情况发出警告,并且可能不会执行DATAFLOW优化。
Conditional Execution of Tasks
DATAFLOW优化并不优化有条件执行的任务。下面的示例强调了这种限制。在本例中,Loop1和Loop2的条件执行阻止Vivado HLS优化这些循环之间的数据流,因为数据不是从一个循环流向下一个循环。
void foo(int data_in1[N], int data_out[N], int sel) {
int temp1[N], temp2[N];
if (sel) {
Loop1: for(int i = 0; i < N; i++) {
temp1[i] = data_in[i] * 123;
temp2[i] = data_in[i];
}
}
else {
Loop2: for(int j = 0; j < N; j++) {
temp1[j] = data_in[j] * 321;
temp2[j] = data_in[j];
}
}
Loop3: for(int k = 0; k < N; k++) {
data_out[k] = temp1[k] * temp2[k];
}
}
为了确保在所有情况下都执行每个循环,您必须转换如下面的示例所示的代码。在本例中,条件语句被移动到第一个循环中。两个循环总是被执行,数据总是从一个循环流向下一个循环。
void foo(int data_in[N], int data_out[N], int sel) {
int temp1[N], temp2[N];
Loop1: for(int i = 0; i < N; i++) {
if (sel) {
temp1[i] = data_in[i] * 123;
}
else {
temp1[i] = data_in[i] * 321;
}
}
Loop2: for(int j = 0; j < N; j++) {
temp2[j] = data_in[j];
}
Loop3: for(int k = 0; k < N; k++) {
data_out[k] = temp1[k] * temp2[k];
}
}
Loops with Multiple Exit Conditions
在数据流区域中不能使用具有多个出口点的循环。在下面的示例中,Loop2有三个退出条件
2.7.5 Configuring Dataflow Memory Channels
Vivado HLS将任务之间的通道实现为乒乓缓冲区或FIFO缓冲区,具体取决于数据的生产者和消费者的访问模式:
- 对于标量、指针和引用参数,Vivado HLS将通道实现为FIFO
- 如果参数(生产者或消费者)是一个数组,Vivado HLS将通道实现为一个乒乓缓冲区或FIFO,如下所示:
○ 如果Vivado HLS确定按顺序访问数据,则Vivado HLS将存储通道实现为深度为2的FIFO通道。.
○ 如果Vivado HLS无法确定是否按顺序访问数据或确定以任意方式访问数据,则Vivado HLS将存储通道实现为乒乓缓冲区,即作为两个Block RAM,每个RAM由 使用者或生产者数组的最大size定义。
Note:乒乓缓冲确保通道始终有能力容纳所有样本而不损失。然而,在某些情况下,这可能是一种过于保守的方法
要显式指定任务之间使用的默认通道,请使用config_dataflow配置(There is no pragma equivalent)。 此配置为设计中的所有通道设置默认通道。 为了减小通道中使用的内存大小并允许迭代内重叠,可以使用FIFO。 要在FIFO中显式设置深度(即元素数),请使用-fifo_depth选项。
指定FIFO通道的大小将覆盖默认方法。如果设计中存在任务,其能够以比指定的FIFO大小更大的速度生成或消耗样本,则FIFOs可能变为空的(或满的)。在这种情况下,设计将停止操作,因为它无法读(或写)。这可能会导致陷入僵局deadlock状态。
Note:如果出现了死锁deadlocked的情况,那么只有在执行C/RTL co-simulation或在完整的系统中使用该模块时才会看到这种情况。
当设置fifo的深度,Xilinx建议初始深度设置为=要传输数据的最大值(例如,任务之间传递的数组的大小),在程序设计通过C/RTL co-simulation后,然后减少fifo的大小,但要确保C/RTL co-simulation仍然没有问题。如果RTL co-simulation失败,则FIFO的大小可能太小,无法防止出现stalling or a deadlock情况。
解决deadlock的方法:
当设置fifo的深度,Xilinx建议最初设置深度最大数量的传输数据值(例如,数组的大小之间传递任务),确认设计通过C/RTL co-simulation,然后减少fifo的大小,确保C/RTL co-simulation仍然完成没有问题。如果RTL co-simulation失败,则FIFO的大小可能太小,无法防止出现stalling or a deadlock情况。
2.7.6 Specifying Arrays as Ping-Pong Buffers or FIFOs
默认数组都实现为乒乓,以支持随机访问。如果需要,还可以调整这些缓冲区的大小。例如,在某些情况下,例如绕过某个任务时,可能会出现性能下降。
为了减轻对性能的影响,可以通过使用如下所示的STREAM directive来增加这些缓冲区的大小,从而为生产者和消费者提供更多的缓冲空间。
(pragma HLS stream作用:在使用DATAFLOW优化时,将特定数组实现为FIFO或RAM存储通道。STREAM 指定将特定存储通道实现为具有可选特定深度的FIFO。)
void top ( ... ) {
#pragma HLS dataflow
int A[1024];
#pragma HLS stream off variable=A depth=3
producer(A, B, …); // producer writes A and B
middle(B, C, ...); // middle reads B and writes C
consumer(A, C, …); // consumer reads A and C
如果将顶层函数接口上的数组设置为接口类型ap_fifo、axis或ap_hs,则数组自动指定为streaming。
在设计内部,如果需要实现FIFO,则必须使用STREAM指令将所有阵列指定为streaming。
Note:当STREAM指令应用于一个数组时,在硬件中实现的FIFO,并且FIFO包含与数组相同的元素。 -depth选项可用于指定FIFO的大小。
STREAM指令还用于更改config_dataflow配置指定的默认实现中DATAFLOW区域中的任何数组。
- 如果config_dataflow default_channel设置为乒乓,那么任何数组都可以通过将STREAM指令应用到数组中来实现FIFO。
注意:要使用FIFO实现,必须以流的方式访问数组。 - 如果config_dataflow default_channel设置为FIFO或Vivado HLS已自动确定以streaming方式访问DATAFLOW区域中的数据,则仍可以通过将STREAM指令(带有-off option)应用于数组来将任何数组实现为乒乓实现。
IMPORTANT! 为了保留访问,可能有必要通过使用volatile限定符来防止编译器优化(尤其是消除死代码)。
当DATAFLOW区域中的数组被指定为streaming并实现为FIFO时,通常不要求FIFO保存与原始数组相同数量的元素。DATAFLOW区域中的tasks在每个数据样本可用时立即消耗它。
带有-fifo_depth选项的config_dataflow命令或带有-depth的STREAM指令可用于将FIFO的大小设置为确保数据流永不停止所需的最小元素数量。
如果选择了off选项,则off选项设置乒乓缓存的深度(块的数量)。深度至少为2。
2.7.7 Specifying Compiler-FIFO Depth
Start Propagation
编译器可能会自动创建一个start FIFO来将一个start令牌传播到内部进程。这样的fifo有时会成为性能的瓶颈,在这种情况下,您可以使用以下命令增加默认大小(固定为2)
config_dataflow -start_fifo_depth
如果生产者和消费者之间需要一个无界的松弛(unbounded slack),并且内部流程可以永远运行,完全且安全地由它们的输入或输出(fifo或PIPOs)驱动,那么可以使用pragma在给定的数据流区域内删除这些start fifo,用户承担风险
#pragma HLS DATAFLOW disable_start_propagation
Scalar Propagation
编译器通过进程之间的scalar FIFO自动传播C / C ++代码中的某些标量。 此类FIFO有时可能是性能的瓶颈或导致死锁,在这种情况下,可以使用以下命令设置大小(默认值设置为-fifo_depth):
config_dataflow -scalar_fifo_depth
2.7.8 Stable Arrays
stable pragma可用于标记数据流区域的输入或输出变量。 假设用户保证此删除确实是正确的,则其效果是删除其相应的同步。
void dataflow_region(int A[...], ...
#pragma HLS stable variable=A
#pragma HLS dataflow
proc1(...);
proc2(A, ...);
如果没有稳定的编译指示,并且假定proc2读取了A,则proc2对于它所在的数据流区域,将是初始同步的一部分(通过ap_start)。 这意味着proc1在proc2也准备好再次启动之前不会重新启动,这将防止数据流迭代重叠,并可能导致性能损失。 稳定的实用指示表明此同步对于保持正确性不是必需的。 在前面的示例中,如果没有稳定的编译指示,并且假设proc2绕过任务读取了proc2,则将导致性能下降。 有了稳定的编译指示,编译器假定:
• if A is read by proc2, then the memory locations that are read will not be overwritten, by any other process or calling context, while dataflow_region is being executed.
• if A is written by proc2, then the memory locations written will not be read, before their definition, by any other process or calling context, while dataflow_region is being
executed.
典型的情况是,仅当数据流区域尚未启动或已完成执行时,调用方才更新或读取这些变量。
2.7.9 Using ap_ctrl_none Inside the Dataflow
ap_ctrl_none块级I / O协议避免了ap_ctrl_hs和ap_ctrl_chain协议所隐含的严格同步方案。 这些协议要求该区域中的所有进程执行完全相同的次数,以便更好地匹配C行为。
但是,在某些情况下,例如,我们的目的是让执行更频繁的更快的进程将工作分配给几个更慢的进程。 对于任何数据流区域(“循环数据流”除外),可以指定
#pragma HLS interface ap_ctrl_none port=return
只要满足以下所有条件:
- The region and all the processes it contains communicates only via FIFOs (hls::stream,
streamed arrays, AXIS); that is, excluding memories. - All the parents of the region, up to the top level design, must fit the following requirements:
○ They must be dataflow regions (excluding “dataflow-in-loop”).
○ They must all specify ap_ctrl_none.
这意味着在层次结构中具有ap_ctrl_none的数据流区域的父级不能是:
• A sequential or pipelined FSM
• A dataflow region inside a for loop (“dataflow-in-loop”)
这个pragma的结果是ap_ctrl_chain不用于同步该区域内的任何进程。它们是根据输入fifo中的数据可用性和输出fifo中的空间来执行或停止的。例如
void region(...) {
#pragma HLS dataflow
#pragma HLS interface ap_ctrl_none port=return
hls::stream<int> outStream1, outStream2;
demux(inStream, outStream1, outStream2);
worker1(outStream1, ...);
worker2(outStream2, ....);
In this example, demux can be executed twice as frequently as worker1 and worker2. For example, it can have II=1 while worker1 and worker2 can have II=2, and still achieving a global II=1 behavior.
Note:
• Non-blocking reads may need to be used very carefully inside processes that are executed less frequently to ensure that C simulation works.
• The pragma is applied to a region, not to the individual processes inside it.
• Deadlock detection must be disabled in co-simulation. This can be done with the
-disable_deadlock_detection option in cosim_design.
3 Optimizing for Latency
1.Using Latency Constraints
2.Merging Sequential Loops to Reduce Latency
3.Flattening Nested Loops to Improve Latency
4 Optimizing for Area
1.Data Types and Bit-Widths
- 为数据类型使用适当的精度
- 确定要实现为ram或寄存器的任何数组的大小。任何过大元素的区域影响都会浪费硬件资源。
- 特别注意乘法、除法、模数或其他复杂的算术运算。如果这些变量比需要的大,则会对区域和性能产生负面影响