LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
前言:这篇paper提出的BigGAN可谓是截至2018年在生成图片质量和多样性方面性能最好的GAN了,作者是赫瑞瓦特大学的Andrew Brock,目前在谷歌实习,这位实习生得到Goodfellow等多位前辈的关注,另外两名是来自谷歌DeepMind团队的Jeff Donahue和Karen Simonyan。BigGAN到底多强大?与BigGAN出现之前最好GAN模型SA-GAN相比,性能(IS指标)提高两倍,SA-GAN的IS得分52.52,FID得分18.65,BigGAN的IS得分166.5,FID得分7.4,而真实的图片的IS得分也不过才233。该paper的实验在512块TPU上进行,一块TPU的性能相当于十几块甚至更多GPU的性能,而一块TPU在实验中的用电量相当于美国一户家庭半年的用电量。该一作称:“这些模型所需的不是算法的改进,而是计算力的进步。当你增加模型容量并增大每步所显示的图像数量时,你就会得到双重组合带来的效果。”
原文链接
译文
目录
1、背景知识
2、两个衡量GAN性能的指标——IS&FID
3、paper正文
3.1 文章动机
3.2 文章贡献
3.3 背景介绍
3.4 扩大GAN规模
3.5 分析BigGAN不稳定原因
3.5.1 从G的角度思考
3.5.2 从D的角度思考
3.6 实验分析
3.7 结论
4、personal idea
1、背景知识
关于最简单的GAN,下面这张图很好的解释了GAN:

提到GAN,最小最大化,博弈是听到比较多的词了,那么minmax到底是怎么做的?下图截图自李宏毅老师的视频:

2、两个衡量GAN性能的指标——IS&FID
首先,我们需要知道,GAN的生成效果好坏到底与什么有关,经过前人归纳,得到Quality(生成图片的质量)和Variety(生成多样性)可以用来粗略衡量GAN的性能,因此,便出现了两种指标IS和FID来衡量质量和多样性,推导可见。
IS可衡量生成图像的质量和多样性,感觉还是侧重质量,因为衡量多样性,有更好的指标FID,因此在paper中我们看到它二者就知道是衡量什么啦。
IS得分越高,说明生成的图像质量越高,FID得分越低,说明生成的图像多样性越高。
补充一下:其实后来有论文对这个指标进行改进,IS指标和FID指标还是有一定缺陷的,但是鉴于多数论文都采用这两个指标,所以本文也用了这两个指标来衡量模型性能。
3、paper正文
3.1 文章动机
“Despite recent progress in generative image modeling, successfully generating high-resolution, diverse samples from complex datasets such as ImageNet remains an elusive goal. To this end, we train Generative Adversarial Networks at the largest scale yet attempted, and study the instabilities specific to such scale.”虽然SA-GAN已经可以生成质量还不错的图像,但是其还有很大的提升空间,尤其是从复杂数据集,比如ImageNet中生成高分辨率、多样化样本仍然是一个难题。尤其是多样性,之前的paper可能都不是太令人满意。
其实,我 个人觉得,BigGAN的性能提高了,就是说生成器训练的更逼真了,那么Goodfellow最开始提出GAN时的动机就都可以作为该paper的动机,至于Goodfellow说GAN有什么用,还请参考Generative Adversarial Networks(2016)为什么要提出GANs部分。
3.2 文章贡献
原文在Introduction部分,表明此项工作的意义,之前的SA-GAN的IS得分52.5距离真实图片的IS得分233还有一定差距,而本文将IS提高到166.5。本文主要从GAN生成的图像与ImageNet数据集图像之间的保真度和多样性方面做了一些贡献。
按照原文,总结一下 BigGAN 的贡献:
-
通过大规模 GAN 的应用,BigGAN 实现了生成上的巨大突破,参数量扩大两到四倍,batchsize扩大八倍;
-
采用先验分布 z 的“截断技巧”,允许对样本多样性和保真度进行精细控制;
-
在大规模 GAN 的实现上不断克服模型训练问题,采用技巧减小训练的不稳定,但完全的稳定性只能以极高的性能成本实现。
We make the following three contributions towards this goal:
• We demonstrate that GANs benefit dramatically from scaling, and train models with two to four times as many parameters and eight times the batch size compared to prior art. We introduce two simple, general architectural changes that improve calability, and modify a regularization scheme to improve conditioning, demonstrably boosting performance.
• As a side effect of our modifications, our models become amenable to the “truncation trick,” a simple sampling technique that allows explicit, fine-grained control of the tradeoff between sample variety and fidelity.
• We discover instabilities specific to large scale GANs, and characterize them empirically. Leveraging insights from this analysis, we demonstrate that a combination of novel and existing techniques can reduce these instabilities, but complete training stability can only be achieved at a dramatic cost to performance.
3.3 背景介绍
当GAN应用于图像时,G和D通常是卷积神经网络,没有稳定技术,训练十分脆弱,因此对于稳定性研究成为一个重要方向,目前,有两条研究方向来增强其稳定性:一个是改变目标函数以鼓励收敛;一个是通过梯度惩罚(?相当于加个正则项)来限制D或者归一化(这两种都是为抵消损失函数的无界性,确保D能够为G的每一个点处提供梯度)。
Much recent research has accordingly focused on modifications to the vanilla GAN procedure to impart stability, drawing on a growing body of empirical and theoretical insights (Nowozin et al., 2016; Sønderby et al., 2017; Fedus et al., 2018). One line of work is focused on changing the objective function (Arjovsky et al., 2017; Mao et al., 2016; Lim & Ye, 2017; Bellemare et al.,
2017; Salimans et al., 2018) to encourage convergence. Another line is focused on constraining D through gradient penalties (Gulrajani et al., 2017; Kodali et al., 2017; Mescheder et al., 2018) or normalization (Miyato et al., 2018), both to counteract the use of unbounded loss functions and ensure D provides gradients everywhere to G.
在这所有的工作中与我们最相关的就是SA-GAN中用的Spectral Normalization(谱归一化),或许你会问SA-GAN是什么?它就是一种利用了Attention机制的GAN,那Attention又是什么?Attention就是能够加强自己想要注意的地方的权重,加了Attention机制后,可以将边界描述的更好。SA-GAN可参见。下图摘自SA-GAN论文中加了Attention机制后的图像示例:

虽然整篇paper一直在提SA-GAN,但其实用到SA-GAN中的谱归一化来提高D的稳定性才是本文的重点,那么谱归一化又是什么呢?简单来说是为了提高GAN的稳定性而用到的一种方法,这其实是一种数学技巧,主要用于D的训练过程中。经过一系列推导,判别器的损失函数改为Wassertein距离(取代原来的KL散度或JS散度),以使D满足Lipschitz continuity(一种使得函数表现比较稳定的条件),必须要求D的损失函数f满足1-Lipschitz,于是,又有一些式子推导(具体推导可见)来证明满足什么条件就满足1-Lipschitz了,最终得到的结论是:只要使各卷积层的参数矩阵除以自身的最大奇异值(又称谱范数)即可满足1-Lipschitz约束。但是实际上在求取最大奇异值时,为了计算快,用了power iteration算法(“幂迭代法”)来求近似解。
另外,在Background部分作者还提到了其他paper中几种用于增强稳定性的方法,鉴于本文后面与这些相关性不大,不予展述。
3.4 扩大GAN规模
本文的基准模型采用的是SA-GAN模型,训练两次D、训练一次G如此循环训练,此外,本文用了正交初始化代替标准初始化。既然叫BigGAN,那么模型一定是扩大了规模,如何扩大的呢?1、batch size增大(增加8倍,IS提高46%) 2、通道数加倍(IS提高21%) 3、单纯增加深度并没有改进,后来采用残差块结构改进深度网络。这其中,还用了几个小trick:作者注意到G中的conditional BatchNorm层嵌入大量参数,所以使用shared embedding(we opt to use a shared embedding, which is linearly projected to each layer’s gains and biases)(训练速度提高37%);另外,采用skip-k方式将噪声z加入到G的多个层而不仅仅是初始输入层(The intuition behind this design is to allow G to use the latent space to directly influence features at different resolutions and levels of hierarchy.)(IS提高4%,训练速度提高18%)。性能提升可见下表:
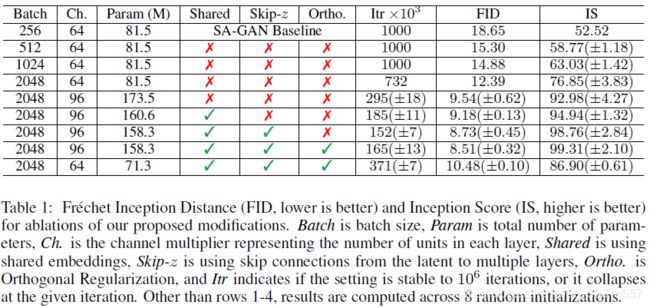
前面的这些工作其实多数是前人研究好了,作者拿来用的,中间用了很多参考文献,那作者自己提出的新的idea呢?就是下面要说的truncation trick(截断技巧),文中对截断技巧是如下解释的:We call this the Truncation Trick: truncating a z vector by resampling the values with magnitude above a chosen threshold leads to improvement in individual sample quality at the cost of reduction in overall sample variety.具体操作就是在对先验分布z采样的过程中,通过设置阈值的方法来截断z的采样,其中超出范围的值被重新采样以落入该范围内,这个阈值可以根据IS指标和FID指标决定。为什么会想到用这个截断技巧呢?其实我们在输入z时,往往用N(0,1)或U[-1,1]分布,但实际上我们可以自由选择任何潜在分布,本文附录E中也做了许多对比实验,发现Beinoulli{0,1}分布和Censored Normal Max(N(0,1),0)分布似乎好一些,但是效果并不是非常明显,相比之下,截断技巧的效果就明显一些。随着阈值下降,生成的图片质量越来越好,但由于阈值下降,采样范围会变窄,造成生成取向单一化,生成多样性不足的问题,即IS(衡量质量)一直变大,而FID(衡量多样性)先变小后变大。如下图所示:

看上图中的(b)我们可以看出出现“饱和伪影”现象,这种现象是由于一些大模型不适合截断引起的,为抵消这种情况,作者采用Orthogonal Regularization(正交正则化),这其实就是令W尽可能是一个正交矩阵,这样使得权重系数彼此之间的干扰非常小,受截断之后消失的部分对结果影响不会太大。作者寻找了一种较好的正则化方法,式子如下:
![]()
3.5 分析BigGAN不稳定原因
3.5.1 从G的角度思考
对G来说,通过前人研究发现W的前三个奇异值对训练崩溃最相关,采用权重更新公式:![]() ,
,![]()
虽然G的改进可能会提高稳定性,但是不足以保证稳定性,所以还需要研究判别器D。
3.5.2 从D的角度思考
作者观察到D的奇异值在整个训练的过程中都会增长,但是只会在崩溃时跳跃而不是爆炸,作者尝试了R1 zero-centered penalty:![]() ,在默认r=10下,IS降低45%,即便是r=1,IS依然降低20%。Repeating this experiment with various strengths of Orthogonal Regularization, DropOut , and L2 , reveals similar behaviors for these regularization strategies: with high enough penalties on D, training stability can be achieved, but at a substantial cost to performance.D可能只是记住了训练集而非记住了训练集的一些特征。
,在默认r=10下,IS降低45%,即便是r=1,IS依然降低20%。Repeating this experiment with various strengths of Orthogonal Regularization, DropOut , and L2 , reveals similar behaviors for these regularization strategies: with high enough penalties on D, training stability can be achieved, but at a substantial cost to performance.D可能只是记住了训练集而非记住了训练集的一些特征。
综上,GAN的思想就是训练好D之后再去训练G,D最佳是必要条件,但不足以用于训练稳定性,使用小规模D或在D中使用Dropout会通过降低记忆范围来改善训练,但这会降低训练速度。通过一些列实验作者得出结论:稳定性不仅仅是来自G或者D,而是来自他们对抗的相互作用中。It is possible to enforce stability by strongly constraining D, but doing so incurs a dramatic cost in performance. With current techniques, better final performance can be achieved by relaxing this conditioning and allowing collapse to occur at the later stages of training, by which time a model is sufficiently trained to achieve good results.
3.6 实验分析

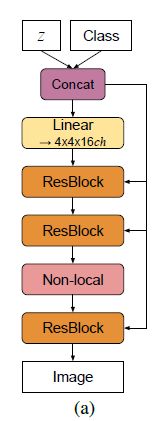
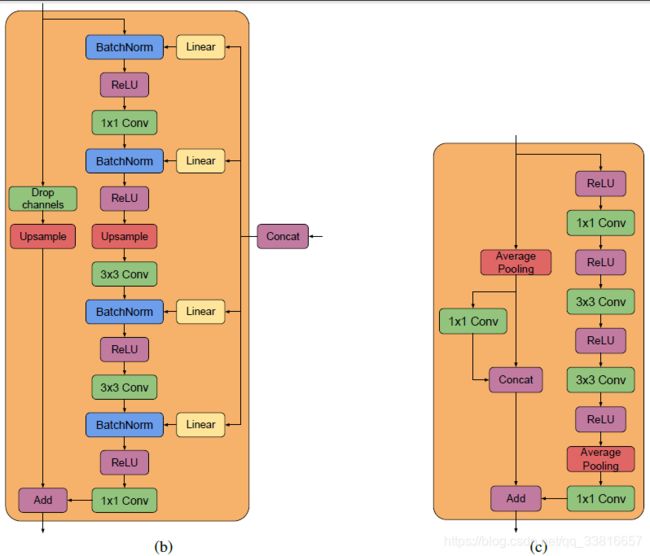

实验还引入了BigGAN-deep模型,并指出BigGAN-deep效果优于BigGAN效果。
通过在不同样本间插值,发现样本的最近邻在视觉上是不同的,这表明BigGAN模型并非单纯记住了训练数据。
通过实验发现,ImageNet数据集上样本数目少的类在生成时比样本数目多的类困难。
另外,作者还在JFT-300M数据集上进行实验,该实验数据集比ImageNet数据集大两个数量级,实验表明作者的模型也要表现的好一些。与在ImageNet GAN上训练的模型不同,在没有大量正规化的情况下训练倾向于崩溃,在JFT-300上训练的模型在10万次迭代中保持稳定,表明超越ImageNet到更大的数据集上可能会缓解GAN训练稳定性的问题。
3.7 结论
作者已经证明,对于多个类别的自然图像进行训练的GAN在保真度和多样性方面都非常利于扩大规模。另外,还对大规模GAN的训练行为进行分析,并根据权重的奇异值表征其稳定性,并讨论了稳定性和性能之间的相互作用。
4、personal idea
正如作者自己所说,这不是算法的改进,而是计算力的提升,BigGAN的提出是否会像ResNet的提出一样,拼的是机器性能,所谓的AI大计算是否将来不会是问题?
通过阅读本paper,对GAN也算是捋了一下,一些式子看不懂还要多感谢一些博主的解释。特征值、特征向量、奇异值、奇异向量原来这么有用。W奇异分解(SVD)成![]() ,左右两边的U和V是对W做旋转变换,只有中间的
,左右两边的U和V是对W做旋转变换,只有中间的 才是做伸缩变换。
才是做伸缩变换。
35页的paper,附录部分看的不是特别仔细,作者做了大量实验,个人感觉实验设计这一块还需要锻炼作者为什么这么设计这个实验的思维。