卷积操作的HLS优化初步操作
背景:卷积操作运用到了三个for循环,非常耗时耗力,HLS综合之后需要耗费很多时钟周期,我们需要对卷积操作进行相应的优化,从而减少卷积运行的时间。
目的:优化卷积操作。
目录
0.原始未优化情况
0.1 testBench确保程序正确
0.2 原始时钟周期
1. 最内层pipeline
1.1直接pipeline
1.2 读写指令分开
1.3 创建变量用于存储
2. 批量读写卷积操作
2.1 array_partation
2.1.1 #define PARA_NUM 128
2.1.2 #define PARA_NUM 64
2.1.3 #define PARA_NUM 32
2.1.3 #define PARA_NUM 2
2.1.4 删掉第三个for循环的pipeline
2.1.5 用pipeline但去掉array_partation
3. 将数据实现在片上BRAM
3.1 直接运行
3.2 pipeline指令
0.原始未优化情况
//convolution codes
M_kernelNum:
for(i = 0; i < M; ++i){
N_kernelSize:
for(k = 0; k < K; ++k){
float A_PART = ALPHA*weight[i*lda+k];
K_outFeatureSize:
for(j = 0; j < N; ++j){
output[i*ldc+j] += A_PART*feature[k*ldb+j];
}
}
} //0 Init Program
mloop_kernelNum:for(i = 0; i < M; ++i){
kloop_kernelSize:for(k = 0; k < K; ++k){
float A_PART = ALPHA*weight[i*K+k];
nloop_featureSize:for(j = 0; j < N; ++j){
output[i*N+j] += A_PART*feature[k*N+j];
}
}
}
也可以写成下面这种形式。读写与运算指令分开,但是图也是一样的。
float A_PART,product,sum;
//0 Init Program
mloop_kernelNum:for(i = 0; i < M; ++i){
kloop_kernelSize:for(k = 0; k < K; ++k){
A_PART = ALPHA*weight[i*K+k];
nloop_featureSize:for(j = 0; j < N; ++j){
product=A_PART*feature[k*N+j];
sum=product+output[i*N+j];
output[i*N+j] = sum;
}
}
}
从BRAM上,读需要四个时钟周期,写需要两个时钟周期,加和乘个四个时钟周期。
0.1 testBench确保程序正确
testBench采用原始的算法与更改后的卷积算法进行对比,为了确保卷积操作是无误的。
#include
#include
#include
#include "gemmOpt.cpp"
int main(){
int M,N,K;
float ALPHA=1;
int i,j,k;
float *weight, *feature, *output_core, *output_sw;
M=16; K=27, N=173056;
//weight[M*K],feature[K*N],output[M*N]
//weight A[M*K], input B[K*N],output C[M*N]
weight = ( float *)malloc(M*K*sizeof( float)+N*K*sizeof( float)+M*N*sizeof( float));
feature = &weight[M*K];
output_core=&feature[K*N];
output_sw =( float *)malloc(M*N*sizeof( float));
volatile float *PtrMig=weight;
//initialize value
for(i=0; i %f\n", i, output_sw[i], output_core[i]);
error=1;
}
}
printf(" Comparison between Software and core finished!\n");
if(error==1)
printf(" FAILED!\n");
else
printf(" SUCCESS!\n");
return 0;
}
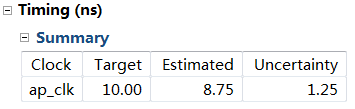
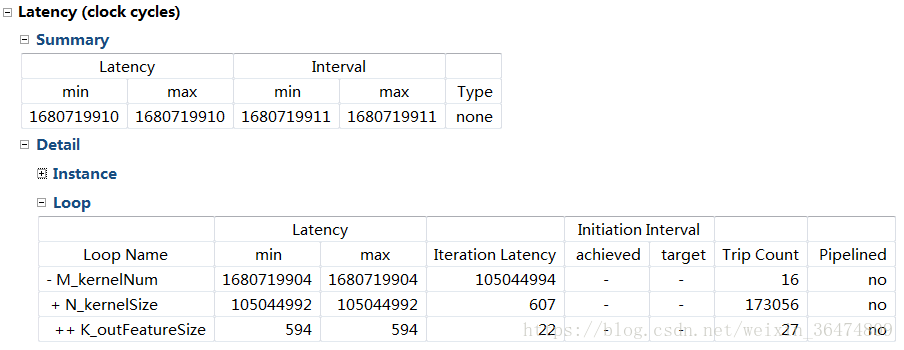
0.2 原始时钟周期
这个卷积为变长度卷积,因此不能直接展开(Unroll指令)。仿真时需要用tripcount指令确定循环上限,这样我们就能知道相应的循环latency和interval
直接运行:相应参数
M:16,N:173056,K:27
gemm_nn:A[432],B[4672512],C[2768896]clockcycles 1680719911,即16亿个时钟周期。
1. 最内层pipeline
1.1直接pipeline



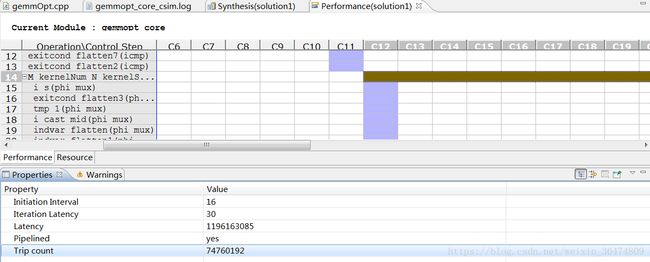
可能pipeline之后更加耗时了。时钟周期由16亿变为11亿。但时钟周期延长了。加rewind指令比不加rewind快一个时钟周期。忽略不计。但是时钟标红表明差错。
1.2 读写指令分开
之前读取,相乘,相加指令在一个for循环之中,现在我们将该指令展开。
//most inner for
for(j = 0; j < N; ++j){
#pragma HLS PIPELINE rewind
float featurePart=feature[k*N+j];
float product=A_PART*featurePart;
output[i*N+j] +=product;
}1.3 创建变量用于存储
int i,j,k;
float featurePart,A_PART,product;
M_kernelNum:
for(i = 0; i < M; ++i){
N_kernelSize:
for(k = 0; k < K; ++k){
A_PART = ALPHA*weight[i*K+k];
K_outFeatureSize:
for(j = 0; j < N; ++j){
#pragma HLS PIPELINE rewind
featurePart=feature[k*N+j];
product=A_PART*featurePart;
output[i*N+j] +=product;
}
}
} 
最耗时的语句就是读取数组的语句。我们必须想办法将数组一次性读出并且并行运算。
A_PART = ALPHA*weight[i*K+k];
featurePart=feature[k*N+j];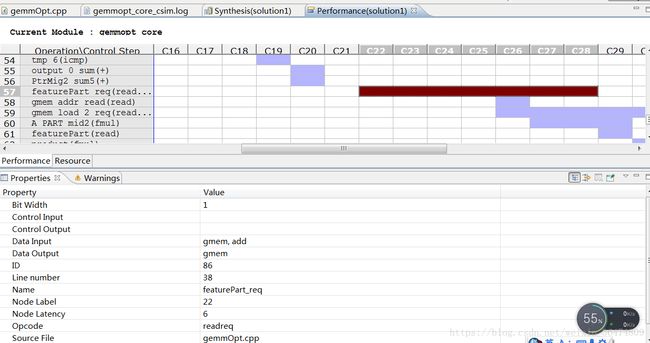
2. 批量读写卷积操作
运用宏指定并行数量,我们将卷积操作更改为下面这种模式,这种模式的卷积可以运用创建宏PARA_NUM进行并行运算。
#define PARA_NUM 1024
unsigned int paraIters=N/PARA_NUM;
int tailCalcu;
int tailNum;
if (paraIters*PARA_NUM2.1 array_partation


对最底层循环N进行pipeline,就是对更下层的进行Unroll,也就是并行
指令之中运用此指令对运算的数组进行分组,发现确实可以优化运算的时间。
2.1.1 #define PARA_NUM 128
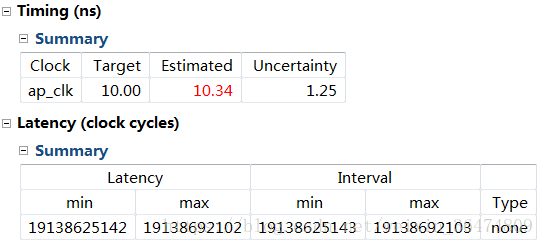
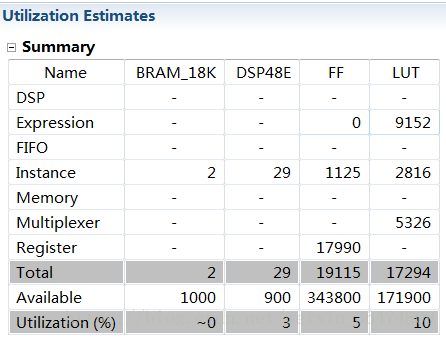
风险项多出现在read的时候

2.1.2 #define PARA_NUM 64
时延大概 95亿
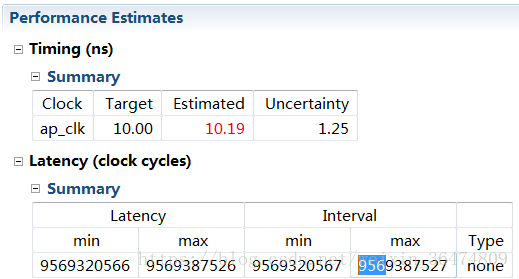

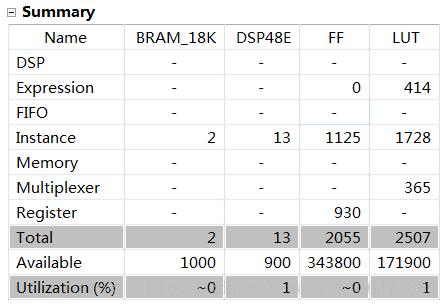
时钟周期反而更短,由191亿变为95亿。说明并非越大并行性能就越好。可能还受到其他一些影响。我们在这里看到FF和LUT的数量减少了,说明增大并行数量确实可以增大LUT的用量。但是可能在于读取的时间问题,越大的并行量反而会增加运行的时间。

但是依然没搞明白为什么减小并行数量反而带来了性能的提升。
2.1.3 #define PARA_NUM 32
时延大概47亿
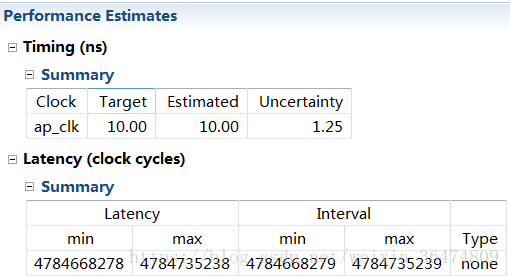


依然是读取占用较多的时钟周期,7个时钟周期,这个是乘法操作占用四个时钟周期。
2.1.3 #define PARA_NUM 2
时延大概12亿
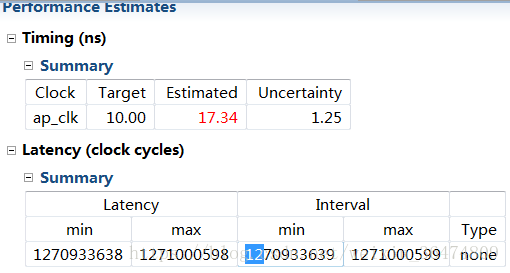

在上面那种模式之下,PARA_NUM越小则效果越好。
2.1.4 删掉第三个for循环的pipeline
PARA_NUM=2, 时延大概43亿,对比之前12亿确实需要加入pipeline流水线更快
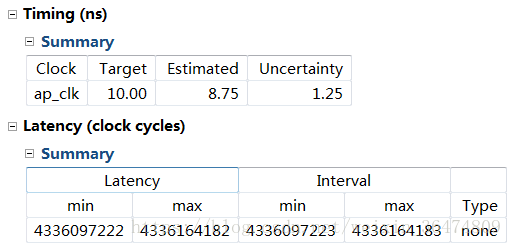
PARA_NUM=16,时延大概233亿,

果然加入pipeLine是十分必要的。
2.1.5 用pipeline但去掉array_partation
PARA_NUM 64
时延大概95亿,与加array_partation一样
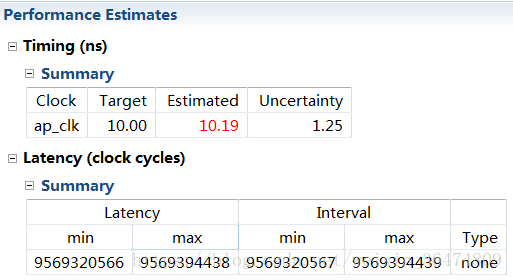
PARA_NUM 32
时延大概47亿,与不加arrayPartation一样。
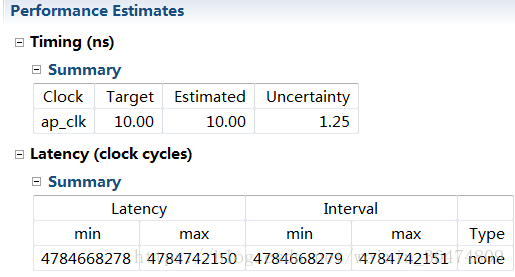
3. 将数据实现在片上BRAM
3.1 直接运行
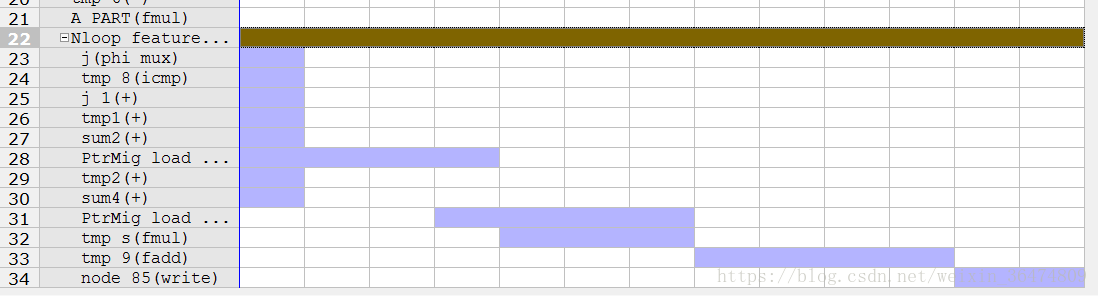
一次典型的操作。两次读,一次乘一次加,一次写。
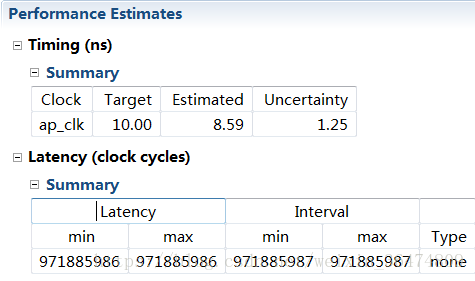
3.2 pipeline指令

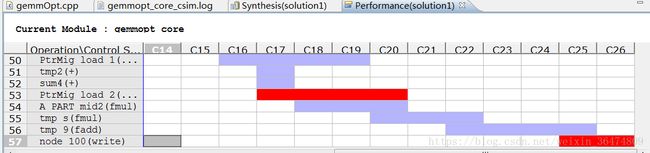
时钟周期变到8亿多,但是读和写操作作为风险项被标出来。