python3 爬取网页内容解析并存入MySQL数据库
爬取网页内容解析并存入MySQL数据库
用到的第三方库:
-
BeautifulSoup:解析网页内容,建议安装方法:
-
pip install beautifulsoup4 -
pymysql:操作数据库,建议安装方法:
-
pip install pymysql
import re
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pymysql.cursors
if __name__ == '__main__':
url = 'https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6/6699?fr=aladdin'
# 爬取网页中所有的链接url
response = urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(response, 'html.parser')
results = soup.findAll('a', href=re.compile(r'http:'))
# 创建本地MySQL链接
connection = pymysql.connect(host='localhost',
user='****', # 你的用户名
password='******', # 你的密码
db='******', # 你的数据库名称
charset='utf8mb4')
try:
# 使用with关键字获取cursor()对象
with connection.cursor() as cursor:
# 插入数据,提前在MySQL创建相应的数据库及数据表
# sql代表:在urls表中插入name, url两个字段的值
sql = 'insert into `urls` (`name`, `url`) values(%s, %s)'
for item in results:
print(item.get_text().strip(), item['href'])
# 执行SQL语句,传入参数
cursor.execute(sql, (item.get_text().strip(), item['href']))
# 提交连接
connection.commit()
finally:
# 关闭连接
connection.close()
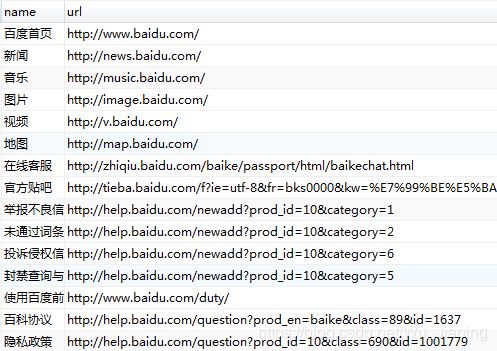
插入结果如下: