CS224n笔记——Subword Model(十二)
系列文章
Lecture 1: Introduction and Word
Lecture 2: Word Vectors and Word Senses
Lecture 12: Subword Model
目录
- 1. ELMO
- 2. GPT
- 2.1 无监督pretrain
- 2.2 有监督finetune
- 3. BERT
very nice的BERT入门级讲解
1. ELMO
首先介绍一下ELMo(Embeddings from Language Models)算法,可去观摩原文查看更详细的内容。在之前word2vec及GloVe的工作中,每个词对应一个vector,对于多义词无能为力,或者随着语言环境的改变,这些vector不能准确的表达相应特征。ELMo的作者认为好的词表征模型应该同时兼顾两个问题:
- 一是词语用法在语义和语法上的复杂特点;
- 二是随着语言环境的改变,这些用法也应该随之改变。
ELMo算法过程为:
- 先在大语料上以language model为目标训练出bidirectional LSTM模型;
- 然后利用LSTM产生词语的表征;
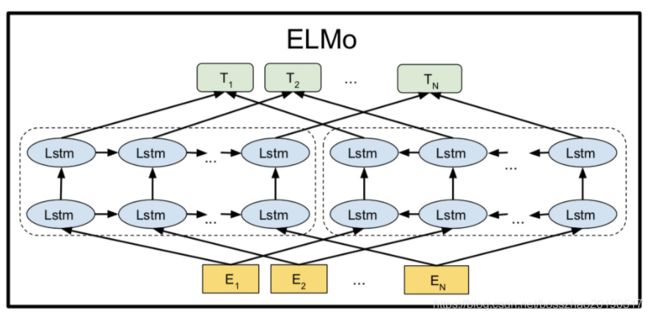
ELMo模型包含多layer的bidirectional LSTM,可以这么理解:
高层的LSTM的状态可以捕捉词语意义中和语境相关的那方面的特征(比如可以用来做语义的消歧),而低层的LSTM可以找到语法方面的特征(比如可以做词性标注)。
Bidirectional language models
ELMo模型有两个比较关键的公式:

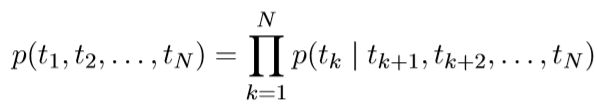
这里可以看出预测句子概率
p ( t 1 , t 2 , . . . , t n ) p(t1,t2,...,tn) p(t1,t2,...,tn)
有两个方向:正方向和反方向。
(t1,t2,…tn)是一系列的tokens 。

这里的Θx代表token embedding, Θs代表softmax layer的参数。
word feature
对于每一个token,一个L层的biLM模型要计算出共2L+1个表征:
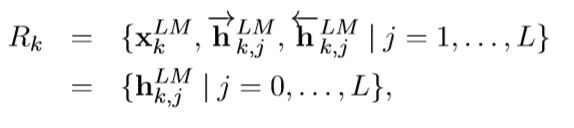
第二个“=”可以理解为:
当 j=0 时,代表token层。当 j>0 时,同时包括两个方向的hidden表征。
2. GPT
这部分介绍GPT模型
GPT的训练分为两个阶段:1)无监督预训练语言模型;2)各个任务的微调。
模型结构图:

2.1 无监督pretrain
使用语言模型最大化下面的式子:
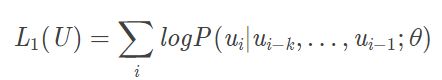
其中 k 是上下文窗口大小,θ 是语言模型参数,使用一个神经网络来模拟条件概率 P
在论文中,使用一个多层的transformer decoder来作为LM(语言模型),可以看作transformer的变体。将transformer decoder中Encoder-Decoder Attention层去掉作为模型的主体,然后将decoder的输出经过一个softmax层,来得到目标词的输出分布:

这里 U = ( u i − k , … , u i − 1 ) U=(u_{i-k},\dots,u_{i-1}) U=(ui−k,…,ui−1)表示 ui 的上下文, W e W_e We是词向量矩阵, W p W_p Wp是位置向量矩阵。
2.2 有监督finetune
在这一步,我们根据自己的任务去调整预训练语言模型的参数 θ,

最后优化的式子为:

在自己的任务中,使用遍历式的方法将结构化输入转换成预训练语言模型能够处理的有序序列:

3. BERT
Bert(原文)是谷歌的大动作,公司AI团队新发布的BERT模型,在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。可以预见的是,BERT将为NLP带来里程碑式的改变,也是NLP领域近期最重要的进展。
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
BERT采用了Transformer Encoder的模型来作为语言模型,Transformer模型来自于经典论文《Attention is all you need》, 完全抛弃了RNN/CNN等结构,而完全采用Attention机制来进行input-output之间关系的计算,如下图中左半边部分所示:
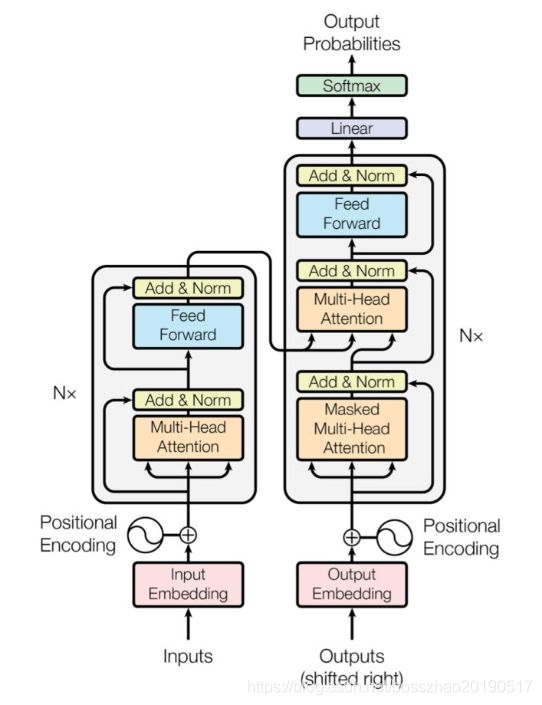
Bert模型结构如下:
BERT模型与OpenAI GPT的区别就在于采用了Transformer Encoder,也就是每个时刻的Attention计算都能够得到全部时刻的输入,而OpenAI GPT采用了Transformer Decoder,每个时刻的Attention计算只能依赖于该时刻前的所有时刻的输入,因为OpenAI GPT是采用了单向语言模型。