论文阅读分享1. YOLO you only look once
YOLOv1: You Only Look Once: Unified, Real-Time Object Detection(你只看一次:统一的,实时的物体检测 )
文章地址:https://arxiv.org/abs/1506.02640
YOLOv2:YOLO9000:Better, Faster, Stronger(YOLO9000:更好、更快、更强)
文章地址:https://arxiv.org/abs/1612.08242
本人菜鸟出道,研一学生一枚,阅读些许论文,为增加自己的印象并易于日后查看,姑且将自己对于论文的一些理解发于该博客之上,若有错误,请多多包涵,欢迎指教与讨论。
WHY YOLO:端到端检测(end to end):将目标检测作为单个回归问题,直接从图像像素到边界框坐标和类概率
与之前的一些物体检测方法(RCNN, Fast RCNN, Faster RCNN)不同,YOLO只需一步就可以从图片得到候选区域及物体。因此YOLO检测物体的速度很快Titan X: YOLO:45fps fast YOLO:150ps. 速度远超RCNN等方法。
目标方法的比较
| RCNN |
Fast RCNN |
Faster RCNN |
YOLO |
||
| 区域建议模块 (region proposal module) |
区域建议模块 (region proposal module)
|
区域建议网络 (Region Proposal Networks)
|
YOLO Network |
||
| 特征提取网络 (feature extraction network) |
检测网络 (detection network) |
Fast RCNN |
|||
| 分类器 (classifier) |
定位器 (locator) |
特征提取(feature extraction ) |
|||
| 分类(classification) |
回归 (regression) |
||||
YOLOv1的检测过程

使用YOLO来检测物体的流程:
1、将图像resize到448 * 448作为神经网络的输入
2、运行神经网络,得到一些bounding box坐标、box中包含物体的置信度和class probabilities
3、进行非极大值抑制,筛选Boxes
Unified Detection(统一的检测)

YOLO将输入图像划分为S*S的栅格(grid),每个栅格负责检测中心落在该栅格中的物体
每一个栅格预测B个边界框(bounding boxes),以及这些边界框的confidence scores,如果这个栅格中不存在一个 object,则confidence score应该为0;否则的话,confidence score则为 predicted bounding box与 ground truth box之间的 IOU(intersection over union)。
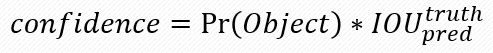
YOLO对每个边界框有5个预测:x, y, w, h, 和 confidence:
x, y 为边界框中心坐标 [0:1](1对于每个grid的边长) w, h为边界框长和宽 [0:1] (1对于图像的边长) confidence为预测其为目标的可能性
每个栅格(grid)还预测 C个类别物体的条件率, 测试阶段,利用下式计算边界框对于每个类的得分
![]()
![]()
所以 输出形式为(S×S×(B×5+C)
因为YOLOv1中采用的降采样为64,输入图片尺寸为448*448,所以S=7, 因为采用了VOC2007,和VOC2012数据集,所以C=20,且每一个栅格采用了两个边界框,即B=2,因此输出为(7*7*30)
YOLOv1在这个方法下造成了一个缺点:每个网格只能预测1个类别,对中心点相同的物体会造成漏检。该缺点在v2下得到解决。
输出结构如下:


YOLOv1的网络结构:
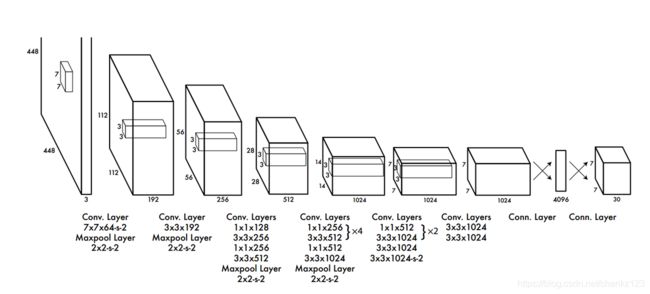
YOLO检测网络:24个卷积层和2个全连接层
YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception模块,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
YOLOv1的训练方法:
首先利用ImageNet 1000-class的分类任务数据集预训练(Pretrain)卷积层。使用上述网络中的前20 个卷积层,加上一个均值池化层,最后加一个全连接层,作为预训练的网络。
将预训练的结果的前20层卷积层应用到检测中,并加入剩下的4个卷积层及2个全连接。 同时为了获取更精细化的结果,将输入图像的分辨率由 224* 224 提升到 448* 448。 (此处应该是没有用448的图片进行微调,在v2中采用)
将所有的预测结果都归一化到 0~1,使用 ?=0.1的Leaky RELU 作为激活函数
为了防止过拟合,在第一个全连接层后面接了一个 prob=0.5 的 Dropout(随机失活) 层。
YOLOv1的损失函数:
YOLO采用平方和误差损失函数:
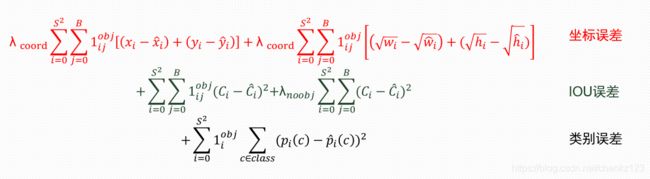
![]() 用来判断该栅格内是否有物体存在, 因此YOLO可以很好的避免背景错误,false positives小。
用来判断该栅格内是否有物体存在, 因此YOLO可以很好的避免背景错误,false positives小。
为了均衡 8维的localization error和20维的classification error,论文加大了8维坐标的损失权重:λ_coord取5 减少了不包含对象的框的置信度预测的损失权重 λ_noobj取0.5 对有object的框的置信度损失权重取1 对不同大小的box预测中,相比于大box预测偏一点,小box预测偏相同的尺寸对IOU的影响更大,因此对长宽采用平方根
YOLOv1的实验结论及优缺点:

优点: 平均准确率(mAP):63.4% 速度:45FPS 假阳性(将背景检测为物体)的概率小
缺点:1、每个网格只能预测1个类别,对中心点相同的物体会造成漏检。 2、位置精确性差,对于小目标物体以及物体比较密集的也检测不好
YOLOv2的改进:
YOLOv2在V1的版本之上提出了一些改进措施,来提升网络的性能
| tricks |
YOLOv1 |
|
YOLOv2 |
||||||
| Batch Normalization |
|
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
| High Resolution Classifier |
|
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
|
| Convolutional |
|
|
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
|
| Anchor Boxes |
|
|
✔ |
✔ |
|
|
|
|
|
| New network |
|
|
|
✔ |
✔ |
✔ |
✔ |
✔ |
|
| Dimension Clusters |
|
|
|
|
✔ |
✔ |
✔ |
✔ |
|
| Location prediction |
|
|
|
|
✔ |
✔ |
✔ |
✔ |
|
| Passthrough |
|
|
|
|
|
✔ |
✔ |
✔ |
|
| Multi-Scale |
|
|
|
|
|
|
✔ |
✔ |
|
| Hi-res detector |
|
|
|
|
|
|
|
✔ |
|
| VOC2007 mAP |
63.4 |
65.8 |
69.5 |
69.2 |
69.6 |
74.4 |
75.4 |
76.8 |
78.6 |

新的网络结构darknet-19 : 减少了网络层数:19个卷积层 取消了全连接层:采用全局均值池化代替 降低了参数量,加快了网络的训练速度
Batch Normalization (进行批量归一化),避免了过拟合
High Resolution Classifier (高分辨率分类器),先使用224的图片进行预训练,再使用448的图片进行微调
Convolutional With Anchor Boxes:1、使用Anchor Boxes来预测边界框,将输入图像的尺寸从448 * 448缩减到416 * 416,使S为奇数,有中心栅格。 2、改变输出形式为(S×S×(B×(5+C))使每个网格能预测多个物体
Dimension Clusters :采用k-means生成Anchor Boxes代替手动设计anchor(猜测对数据集采用k-means)
Fine-Grained Features(细粒度功能):参考恒等映射,增加一个直通单元,将上一层26*26*512->13*13*2048,与原始特征连接,提高性能
Multi-Scale Training(多尺度训练):使用不同大小的图片训练,大小为32的倍数(该模型的降采样为32),每10个批次换,适应各个尺度,在速度与准确率之间做了折衷.(可以选择满足自己的运行速度下,精度最高的尺度)
| 图片大小 |
mAP |
FPS |
| 288 × 288 |
69.0 |
91 |
| 352 × 352 |
73.7 |
81 |
| 416 × 416 |
76.8 |
67 |
| 480 × 480 |
77.8 |
59 |
| 544 × 544 |
78.6 |
40 |
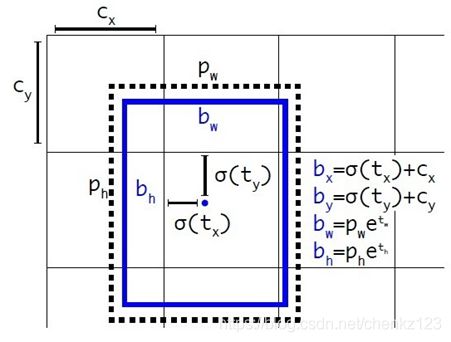
Direct location prediction: YOLOv2网络为每个栅格预测5个边界框(对应5个anchor boxes),每个bounding box预测5个坐标
![]()
YOLOv2结果:
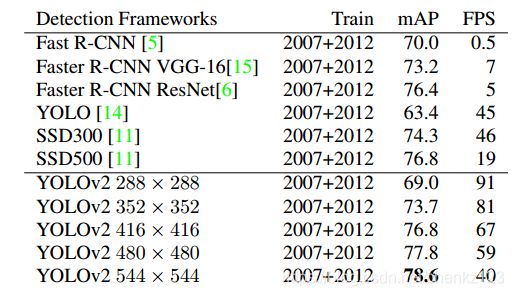
YOLO9000(该方法看的有点懵):

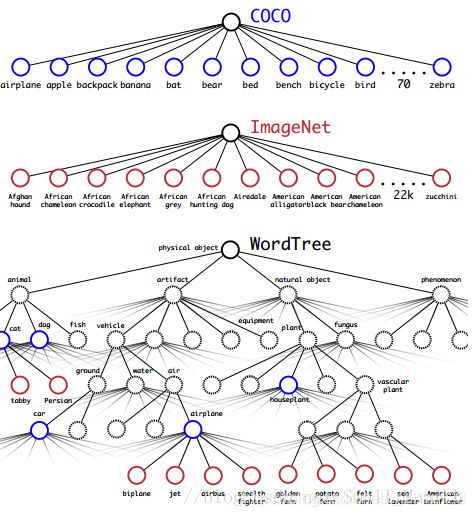
stronger(联合训练分类和检测数据的机制)将检测和分类任务进行协同训练,使用分层树表示类别进行类别标记
问题1:softmax结果互斥:多标签模型组合数据集, 分层分类(A:AB,AC:ACD,ACF),使用WordNet 有向图->树 WordTree
可以在每一个节点上对其分支进行softmax ![]() 与WordTree的数据集组合:将类别映射到树中
与WordTree的数据集组合:将类别映射到树中
使用COCO检测数据集和完整的ImageNet版本中的前9000个类来创建我们的组合数据集,对COCO进行过采样,使得1(coco):4 19.7 mAP
缺点:因为COCO没有服装设备类,所以在该类效果差
参考文档
https://arxiv.org/abs/1506.02640
https://arxiv.org/abs/1612.08242
https://blog.csdn.net/hrsstudy/article/details/70305791
https://blog.csdn.net/hrsstudy/article/details/70767950
https://blog.csdn.net/small_munich/article/details/79548149