javascript 哈希表
基本概念:
哈希表(hash table )是一种根据关键字直接访问内存存储位置的数据结构,通过哈希表,数据元素的存放位置和数据元素的关键字之间建立起某种对应关系,建立这种对应关系的函数称为哈希函数。
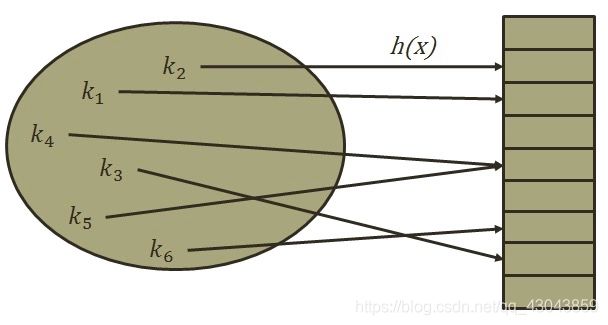
哈希表的构造方法:
假设要存储的数据元素个数是n,设置一个长度为m(m > n)的连续存储单元,分别以每个数据元素的关键字Ki(0<=i<=n-1)为自变量,通过哈希函数hash(Ki),把Ki映射为内存单元的某个地址hash(Ki),并将数据元素存储在内存单元中。
从数学的角度看,哈希函数实际上是关键字到内存单元的映射,因此我们希望通过哈希函数通过尽量简单的运算使得哈希函数计算出的花溪地址尽量均匀的背影射到一系列的内存单元中,构造哈希函数有三个要点:(1)运算过程要尽量简单高效,以提高哈希表的插入和检索效率;(2)哈希函数应该具有较好的散列型,以降低哈希冲突的概率;第三,哈希函数应具有较大的压缩性,以节省内存。
常用方法:
- 直接地址法:以关键字的某个线性函数值为哈希地址,可以表示为hash(K)=aK+C;优点是不会产生冲突,缺点是空间复杂度可能会较高,适用于元素较少的情况。
- 除留余数法:它是由数据元素关键字除以某个常数所留的余数为哈希地址,该方法计算简单,适用范围广,是经常使用的一种哈希函数,可以表示为:
hash(K=K mod C;该方法的关键是常数的选取,一般要求是接近或等于哈希表本身的长度,研究理论表明,该常数选素数时效果最好 - 数字分析法:该方法是取数据元素关键字中某些取值较均匀的数字来作为哈希地址的方法,这样可以尽量避免冲突,但是该方法只适合于所有关键字已知的情况,对于想要设计出更加通用的哈希表并不适用。
- 平方求和法:对当前字串转化为Unicode值,并求出这个值的平方,去平方值中间的几位为当前数字的hash值,具体取几位要取决于当前哈希表的大小。
- 分段求和法:根据当前哈希表的位数把所要插入的数值分成若干段,把若干段进行相加,舍去调最高位结果就是这个值的哈希值。
哈希冲突的解决方案:
在构造哈希表时,存在这样的问题:对于两个不同的关键字,通过我们的哈希函数计算哈希地址时却得到了相同的哈希地址,我们将这种现象称为哈希冲突。
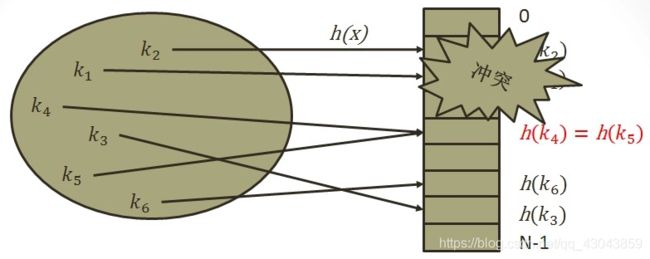
哈希冲突主要与两个因素有关
(1)填装因子,填装因子是指哈希表中已存入的数据元素个数与哈希地址空间的大小的比值,a=n/m ; a越小,冲突的可能性就越小,相反则冲突可能性较大;但是a越小空间利用率也就越小,a越大,空间利用率越高,为了兼顾哈希冲突和存储空间利用率,通常将a控制在0.6-0.9之间,而.net中的HashTable则直接将a的最大值定义为0.72 (虽然微软官方MSDN中声明HashTable默认填装因子为1.0,但实际上都是0.72的倍数)
(2)与所用的哈希函数有关,如果哈希函数得当,就可以使哈希地址尽可能的均匀分布在哈希地址空间上,从而减少冲突的产生,但一个良好的哈希函数的得来很大程度上取决于大量的实践。
1)开放定址法
Hi=(H(key) + di) MOD m i=1,2,…k(k<=m-1)
其中H(key)为哈希函数;m为哈希表表长;di为增量序列。有3中增量序列:
①线性探测再散列:di=1,2,3,…,m-1
②二次探测再散列:di=12,-12,22,-22,…±k^2(k<=m/2)
③伪随机探测再散列:di=伪随机数序列
缺点:
我们可以看到一个现象:当表中i,i+1,i+2位置上已经填有记录时,下一个哈希地址为i,i+1,i+2和i+3的记录都将填入i+3的位置,这种在处理冲突过程中发生的两个第一个哈希地址不同的记录争夺同一个后继哈希地址的现象称为“二次聚集”,即在处理同义词的冲突过程中又添加了非同义词的冲突。但另一方面,用线性探测再散列处理冲突可以保证做到:只要哈希表未填满,总能找到一个不发生冲突的地址Hk。而二次探测再散列只有在哈希表长m为形如4j+3(j为整数)的素数时才可能。即开放定址法会造成二次聚集的现象,对查找不利。
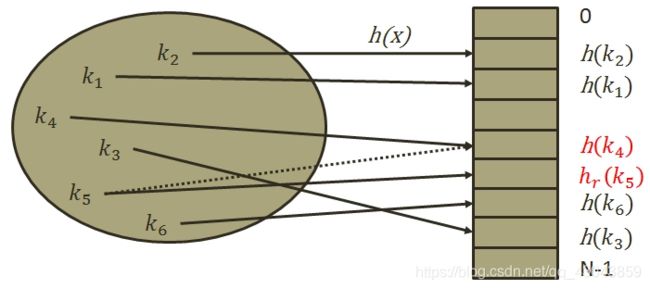
2)再哈希法
Hi = RHi(key),i=1,2,…k RHi均是不同的哈希函数,即在同义词产生地址冲突时计算另一个哈希函数地址,直到不发生冲突为止。这种方法不易产生聚集,但是增加了计算时间。
缺点:增加了计算时间。
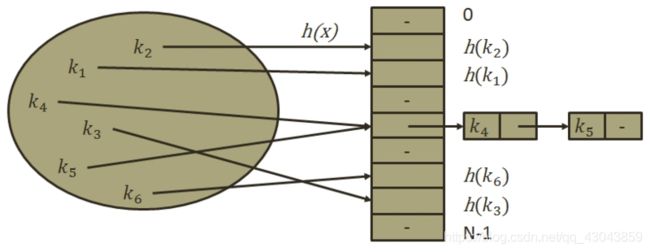
3)链地址法(拉链法)
将所有关键字为同义词的记录存储在同一线性链表中。
优点:
①拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
②由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
③开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
④在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结 点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在 用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
缺点:
拉链法的缺点是:指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
4)建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0…m-1]为基本表,每个分量存放一个记录,另设立向量OverTable[0…v]为溢出表。所有关键字和基本表中关键字为同义词的记录,不管他们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表。
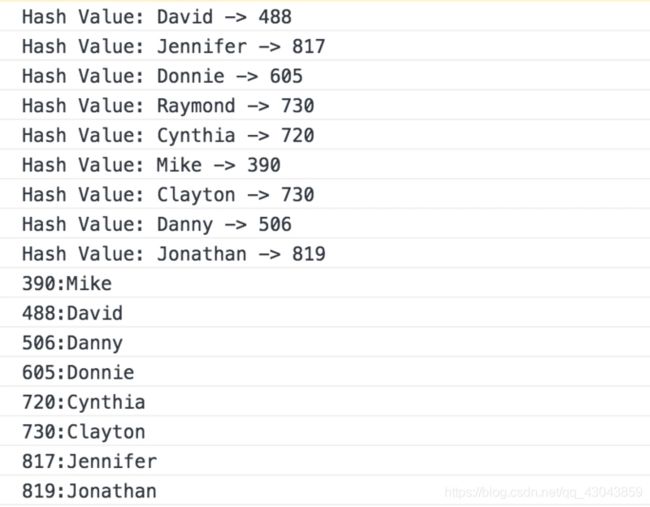
一个简单哈希函数不做冲突处理的哈希表实现
class Hash {
constructor() {
this.table = new Array(1024);
}
hash(data) {
//就将字符串中的每个字符的ASCLL码值相加起来,再对数组的长度取余
var total = 0;
for (var i = 0; i < data.length; i++) {
total += data.charCodeAt(i);
}
console.log("Hash Value: " + data + " -> " + total);
return total % this.table.length;
}
insert(key, val) {
var pos = this.hash(key);
this.table[pos] = val;
}
get(key) {
var pos = this.hash(key);
return this.table[pos]
}
show() {
for (var i = 0; i < this.table.length; i++) {
if (this.table[i] != undefined) {
console.log(i + ":" + this.table[i]);
}
}
}
}
var someNames = ["David", "Jennifer", "Donnie", "Raymond", "Cynthia", "Mike", "Clayton", "Danny", "Jonathan"];
var hash = new Hash();
for (var i = 0; i < someNames.length; ++i) {
hash.insert(someNames[i], someNames[i]);
}
hash.show();
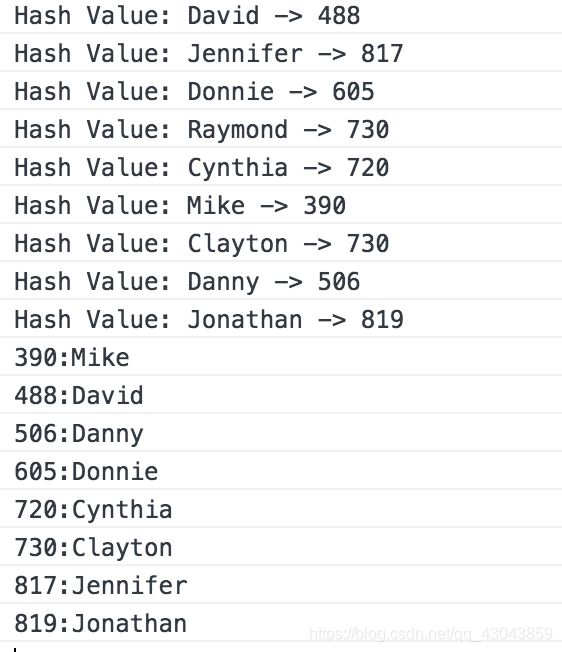
采用的是平方取中法构建哈希函数,开放地址法线性探测法进行解决冲突。
class Hash {
constructor() {
this.table = new Array(1000);
}
hash(data) {
var total = 0;
for (var i = 0; i < data.length; i++) {
total += data.charCodeAt(i);
}
//把字符串转化为字符用来求和之后进行平方运算
var s = total * total + ""
//保留中间2位
var index = s.charAt(s.length / 2 - 1) * 10 + s.charAt(s.length / 2) * 1
console.log("Hash Value: " + data + " -> " + index);
return index;
}
solveClash(index, value) {
var table = this.table
//进行线性开放地址法解决冲突
for (var i = 0; index + i < 1000; i++) {
if (table[index + i] == null) {
table[index + i] = value;
break;
}
}
}
insert(key, val) {
var index = this.hash(key);
//把取中当做哈希表中索引
if (this.table[index] == null) {
this.table[index] = val;
} else {
this.solveClash(index, val);
}
}
get(key) {
var pos = this.hash(key);
return this.table[pos]
}
show() {
for (var i = 0; i < this.table.length; i++) {
if (this.table[i] != undefined) {
console.log(i + ":" + this.table[i]);
}
}
}
}
var someNames = ["David", "Jennifer", "Donnie", "Raymond", "Cynthia", "Mike", "Clayton", "Danny", "Jonathan"];
var hash = new Hash();
for (var i = 0; i < someNames.length; ++i) {
hash.insert(someNames[i], someNames[i]);
}
hash.show();
参考: javascript 哈希表