Siamese Network (应用篇6) :孪生网络用于图像块匹配 CVPR2017
参考论文:L2-Net: Deep Learning of Discriminative Patch Descriptor in Euclidean Space
会议水平:CVPR2017
供稿单位:中科院自动化所
1. 摘要 及 目的
利用卷积神经网络在欧式空间下学习高效性能的描述子 descriptor。作者的方法在四个方面与众不同,1.我们提出了一种渐进的抽样策略,使网络能够在几次的时间内访问数十亿的训练样本。2.从局部匹配问题的基本概念派生而来,我们强调了描述符之间的相对距离。3.对中间特征图进行额外的监督。 4.将描述符的紧凑性考虑在内。作者就是采用L2距离对特征描述子进行度量。收获到了非常好的结果(同期也有相关的工作)。
引用作者的原文更能说明问题:
The proposed L2-Net is a CNN based model without metric learning layers, and it outputs 128 dimensional descriptors, which can be directly matched by L2 distance.
Comment:作者没有测度学习层,研究的是特征描述子、特征提取层和决策层匹配的问题。
损失函数中作者融合了三个误差:其一,特征描述子之间的误差;其二,控制描述子的稠密度和过拟合;其三,二外的监督控制中间的特征图。
2. 方法 及 细节

图1. 作者使用的网络结构。3x3 Cov = 卷积层 + 批正则化 + 整流函数。 8x8 Conv = 卷积 + 批正则化。典型的全卷积结构,降采样通过跨步卷积实现(stride = 2)。每层卷积层后面都跟随批正则化。作者进行了小的修改,批正则化层的权重核 偏置没有更新,固定为1和0.在设计描述子过程中,标准化是很关键的一部,作者采用Local Response Normalization 层作为输出层,产生单位描述子。L2-Net 将32x32的输入图像块转换成128维的特征向量。注意:右侧的网络架构是作者借鉴了前面的工作,也就是center-surround模型。这里不深入研究。
引用原文:Since normalization is an important step in designing descriptors, we use a Local Response Normalization layer (LRN) as the output layer to produce unit descriptors.
2.1 训练数据和与处理技巧
两个标准的测试集:Brown dataset 和 HPatches dataset。对于每一个图像块,作者进行去均值和对比度归一化。也就是我们平常所说的去除均值除以标准差。
For each patch, we remove the pixel mean calculated across all the training patches, and then contrast normalization is applied, i.e., subtracted by the mean and divided by the standard deviation。
2.2 训练集进行渐进抽样
主要是因为在训练样本中,非匹配的图像对远远多于匹配的图像对,所有的非匹配对不可能完全遍历到,所以一个好的采样策略很重要。(其实是一种非常简单的采样策略)
引用原文:In local patch matching problem, the number of potential non-matching (negative) patches is orders of magnitude larger than the number of matching (positive) patches. Due to the so large amount of negative pairs, it is impossible to traverse all of them, therefore a good sampling
strategy is very crucial.
2.3 损失函数设计(精华)
1. 特征之间的测度
2. 描述子的特征维度应该最大限度去相关 (作者谈到这个事似乎也没解释清楚)
3. 对中间的特征图也要施加约束 (其实可以用正则化来解释的)
2.3 训练参数
We train the network from scratch using SGD with a starting learning rate of 0.01, momentum of 0.9 and weight decay of 0.0001. The learning rate is divided by 10 every 20 epochs, and the training is done with no more than 50 epochs. For the training of CS L2-Net, we initialize the two towers using the well trained L2-Net. The parameters of the left tower in Fig. 1-(b) is fixed and we fine tune the right tower until convergence. We let p1 = p2 = q/2 = 64, Data augmentation (optional) is achieved online by randomly rotating (90, 180, 270 degree) and flipping.
3. 实验与结论
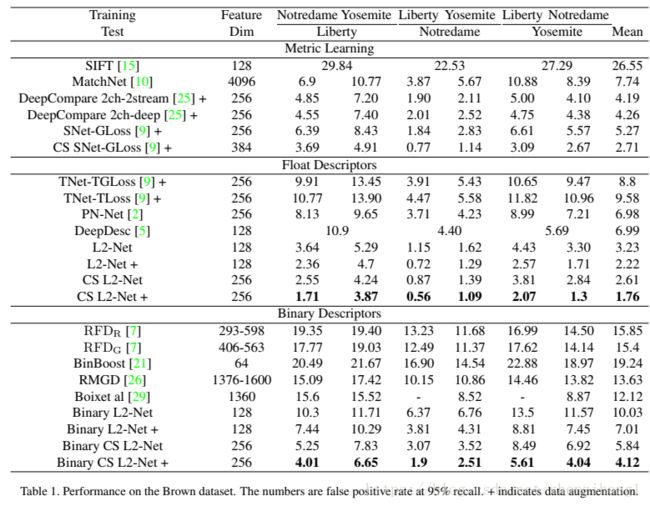
这张表有两个经验值得学习:
1. 数据增强的效果:确实数据增强可以提升模型的性能
2. 数据处理的效果:同等情况下描述子的浮点表达形式明显优于二值表达形式
3.关于结构的探讨:一般情况下不赞成使用池化效应。同时赞成使用不同深度的框架
现在纠结的是,同样使用的类似的、简单的网络结构,为什么作者可以得到如此好的结果??? 原因一定是出现在损失函数的构造上!!!
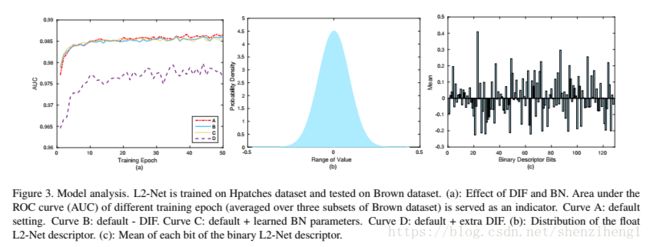
特征维度紧致的重要性。We try to train L2-Net without E2, however, the network does not converge. Due to the large amount of training samples fed to the network, it is easier for the network to memorize the training data rather than learn to generalize. Without E2, strong overfitting happens and the dimensions of the output descriptor are highly correlated. Therefore, compactness is of crucial importance to the progressive sampling strategy. By restricting compactness, the network actually tends to extract uncorrelated features containing more information。
Comment:其实这是作者自己操控的试验训练过程。如果直接应用数据库,里面有大量相关性非常强的图像对,这就会造成网络去记忆训练数据,而不是泛化的去学习特征。因此,其实吧,作者提及到的特征紧密型之所以没有数理证明,是因为训练数据相对独立,这就暗含着特征维度间相对去相关。
L2距离的优势。还好还好 也就一般啦...
DIF的有效性,实验还没有重复出来....
批归一化的收益:这个应该是所有人都关心的,批归一化一般可以加快收敛速度这没的说,关键是BatchNorm对提高模型的准确度到底贡献几何?The weighting α and bias β are fixed to be 1 and 0 in our BN layers, as we find learning them makes the output feature maps (and descriptors) in poor distribution. In this experiment, the weighing and bias parameters of all BN layers is learned except the two BN layers before DIF (as DIF depends on the normalized features). The training procedure is shown by curve C in Fig. 3-(a). Comparing curve A with C, we can find that updating α and bias β leads to minor performance decline. As an illustration to this phenomenon, suppose a ∼ N (μ1, σ1) and b ∼ N (μ2, σ2) are two random variables obeying gaus-sian distribution. It is not difficult to understand that the easiest way to separate them is to increase |μ1 - μ2| while
decrease |σ1| and |σ2|. As a result, learning α and β may cause the extracted feature to be sharp and non-zero distributed, which damages the performance. Fixing them is based on the principal that we want the feature maps (and descriptors) of different patches to be independent identically distributed. In this way, the network is forced to extract features that are highly discriminative rather than biased。作者的设置方法是DIF前两个BN层没有进行学习,作者解释的原因是DIF依赖归一化特征,过多的使用BN层会破坏不同对图相间的独立同分布性质,又绕回去了,我们要的是泛化的判别能力,而不是记忆训练集的能力。
ConcluSion:In this paper, we propose a new data-driven descriptor that can be matched in Euclidean space and significantly outperforms state-of-the-arts. Its good performance is mainly attributed to a new progressive sampling strategy
and a dedicated loss function containing three terms. By progressive sampling, we manage to visit billions of training samples. By going back to the basic concept of matching (NNS), we thoroughly explore the information in each batch. By requiring compactness, we successfully handle overfitting. By utilizing intermediate feature maps, we further boost the performance.
4.补充材料
4.1 Brown数据集
M. Brown, G. Hua and S.A.G. Winder. Discriminative learning of local image descriptors. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010. 1, 2, 3, 5
4.2 HPatch 数据集
V. Balntas, K. Lenc, A. Vedaldi and K. Mikolajczyk. HPatches: A benchmark and evaluation of handcrafted and learned local descriptors. In CVPR, 2017. 1, 3,5