QNX---- 第5章 多核处理
QNX--- 第5章 多核处理
俗话说“三个臭皮匠,顶个诸葛亮”,计算机系统也是如此。在计算机系统中,两个或两个以上的处理器可以大大提高性能。多处理系统可以采用以下形式:
离散或传统:一种系统,它有独立的物理处理器,以多处理模式连接到一个板级总线上。
多核:一种具有一个物理处理器和多个互连cpu的芯片,在芯片级总线上。多核处理器通过并发提供更大的计算能力,提供更大的系统密度,并以低于单处理器芯片的时钟速度运行。多核处理器还可以减少散热、功耗和电路板面积(从而降低系统成本)。
多处理包括几种操作模式:
非对称多处理(AMP),单独的操作系统或相同操作系统的单独实例化在每个操作系统上运行CPU。
对称多处理(SMP), 操作系统的单一实例化可以同时管理所有cpu,应用程序可以加载到任何一个cpu上。
混合多处理(BMP), 操作系统的单一实例化同时管理所有CPU,但每个应用程序都被锁定在一个特定的CPU上。
确定系统上有多少个处理器,查看系统页面的num_cpu条目。
非对称多处理(AMP)
不对称多处理提供了与传统单处理器系统相似的执行环境。它为移植遗留代码提供了一个相对简单的路径,并提供了控制cpu使用方式的直接机制。在大多数情况下,它允许您使用标准的调试工具和技术。
AMP可以:
•同质化——每个CPU运行相同类型和版本的操作系统
•异构——每个CPU运行不同的操作系统或相同操作系统的不同版本
QNX Neutrino's的分布式编程模型允许您在同构环境中充分利用多个cpu。在一个CPU上运行的应用程序可以透明地与其他CPU上的应用程序和系统服务(例如,设备驱动程序、协议栈)通信,而不需要传统的处理器间通信形式所带来的高CPU利用率。
在异构系统中,必须实现一个专有通信方案,或者选择两个共享一个公共基础设施(可能基于IP)的操作系统进行处理器间通信。为了避免资源冲突,OS还应该提供访问共享硬件组件的标准化机制。
使用AMP,可以决定应用程序使用的共享硬件资源如何在cpu之间进行分配。通常,这种资源分配在引导期间静态发生,包括物理内存分配、外围设备使用和中断处理。虽然系统可以动态地分配资源,但这样做需要cpu之间进行复杂的协调。
在AMP系统中,一个进程总是在同一个CPU上运行,即使其他CPU是空闲的。因此,一个CPU最终可能会被低估或过度使用。为了解决这个问题,系统可以允许应用程序从CPU动态迁移到另一个CPU。但是,这样做可能涉及到复杂的状态检查,或者在应用程序在一个CPU上停止并在另一个CPU上重新启动时可能出现服务中断。另外,如果cpu运行不同的操作系统,这种迁移即使不是不可能,也是很困难的。
对称多处理(SMP)
在多核设计中分配资源可能很困难,特别是当多个软件组件不知道其他组件如何使用这些资源时。对称多处理通过在系统的所有cpu上只运行QNX Neutrino RTOS的一个副本来解决这个问题。因为OS在任何时候都能洞察所有的系统元素,所以它可以在多个cpu上分配资源,而应用程序设计的输入很少或根本不需要。此外,QNX Neutrino还提供了内置的标准化原语,例如pthread_mutex_lock()、pthread_mutex_unlock()、pthread_spin_lock()和pthread_spin_unlock(),它们可以让多个应用程序安全轻松地共享这些资源。
通过只运行一个QNX Neutrino副本,SMP可以动态地将资源分配给特定的应用程序,而不是cpu,从而可以更好地利用可用的处理能力。它还可以让系统跟踪工具收集操作统计信息和应用程序交互,从而了解如何优化和调试应用程序。
例如,IDE中的系统分析器可以跟踪线程从一个CPU到另一个CPU的迁移,以及操作系统原语的使用、事件调度、应用程序到应用程序的消息传递和其他事件,所有这些都可以通过高分辨率的时间戳完成。应用程序同步也变得更加容易,因为使用的是标准的OS原语而不是复杂的IPC机制。
QNX Neutrino使应用程序内的执行线程可以在任何CPU上并发运行,使应用程序可以随时使用芯片的全部计算能力。QNX Neutrino的抢占和线程优先排序功能帮助确保CPU周期流向最需要它们的应用程序。
QNX Neutrino RTOS的微核方法
SMP通常与在高端服务器上运行的Unix和Windows NT等高端操作系统相关联。这些大型单片系统往往相当复杂,这是许多人多年开发的结果。由于这些大型内核包含所有操作系统服务的大部分,因此支持SMP的更改是广泛的,通常需要在整个代码中进行大量修改和使用专门的自旋锁。
另一方面,QNX Neutrino包含一个非常小的微内核,周围环绕着充当资源管理器的进程,提供文件系统、字符I/O和网络等服务。仅通过修改微内核,所有其他操作系统服务都可以充分利用SMP,而无需进行编码更改。如果这些服务提供进程是多线程的,那么它们的许多线程将被调度到可用的处理器中。即使是单线程服务器也可以从SMP系统中获益,因为它的线程将被调度到其他服务器和客户端进程旁边的可用处理器上。
作为这种微内核方法的证明,支持smp的QNX Neutrino 内核/进程管理器只增加了几千字节的额外代码。SMP版本是为这些主处理器系列设计的:
• ARM (procnto-smp)
• x86 (procnto-smp)
x86版本可以在任何符合Intel多处理器规范(MP规范)的系统上启动,最多可以使用32个奔腾处理器。QNX Neutrino也支持在P4和Xeon处理器中发现的英特尔超线程技术。
procnto-smp管理器还将在单个非smp系统上运行。由于构建双处理器奔腾主板的成本与构建单处理器主板的成本几乎相同,因此可以通过简单地添加第二个CPU来交付具有成本效益的解决方案。操作系统本身只有几千字节大,这一事实也使SMP能够被认真地用于小型cpu密集型嵌入式系统,而不仅仅是高端服务器。
启动x86 SMP系统
微内核本身包含很少的硬件或系统特定的代码。确定系统功能的代码被隔离在启动程序中,启动程序负责初始化系统、确定可用内存等。收集的信息被放到一个内存表中,这个表对微内核和所有进程都可用(以只读方式)。
startup-bios程序设计用于兼容Intel MP规范(1.4版或更高版本)的系统。本启动程序负责:
•确定处理器的数量
•确定本地和I/O APIC的地址
•初始化每个附加处理器
复位后,只有一个处理器将执行复位代码。这个处理器称为启动处理器(BP)。对于发现的每一个附加处理器,运行startup-bios代码的BP将:
•初始化处理器
•切换到32位保护模式
•分配处理器自己的页面目录
•设置禁用中断的处理器旋转,等待内核释放。
SMP微核是如何工作的
在释放并运行附加处理器之后,所有处理器都被认为是线程调度的对等点。
调度
调度策略遵循与单处理器系统相同的规则。也就是说,最高优先级的线程将在可用的处理器上运行。如果一个新线程准备好作为系统中最高优先级的线程运行,它将被分派到适当的处理器。如果选择多个处理器作为潜在的目标,那么微内核将尝试将线程分派到上一次运行的处理器。这种关联被用作减少线程从一个处理器迁移到另一个处理器的尝试,这会影响缓存的性能。
在SMP系统中,调度器在确定如何调度其他线程方面具有一定的灵活性,它的目标是优化缓存使用和最小化线程迁移。这可能意味着一些处理器将运行低优先级的线程,而高优先级的线程将等待在它上次运行的处理器上运行。下次运行低优先级线程的处理器做出调度决策时,它将选择高优先级线程。
无论如何,在单处理器系统上存在的实时调度规则将在SMP系统上得到保证。
内核锁定
在单处理器系统中,每次只允许一个线程在微内核中执行。大多数内核操作的持续时间都很短(在奔腾级处理器上通常只有几微秒)。微内核还被设计成完全可抢占和可重新启动的,用于那些需要更多时间的操作。这种设计可以保持微内核的精简和快速,而不需要大量的细粒度锁。值得注意的是,在通过内核的主代码路径中放置许多锁会明显减慢内核的速度。每个锁通常涉及处理器总线事务,这会导致处理器停顿。
在SMP系统中,QNX Neutrino在一个可抢占和可重新启动的内核中只维护一个线程的思想。微内核可以在任何处理器上输入,但每次只允许一个处理器访问。
对于大多数系统,在微内核上花费的时间只占处理器工作负载的一小部分。因此,当冲突发生时,它们应该是例外而不是常态。对于微内核来说尤其如此,传统的操作系统服务(如文件系统)是独立的进程,而不是内核本身的一部分。
处理机间中断(ipi)
处理器之间通过IPIs(处理器间中断)进行通信。IPIs可以有效地调度和控制多个处理器上的线程。例如,当:
•一个高优先级的线程准备好了;
•在另一个处理器上运行的线程被一个信号击中;
•在另一个处理器上运行的线程被取消;
•在另一个处理器上运行的线程被销毁。
临界区
线程和进程使用互斥体、condvars和信号量等标准POSIX基元来控制对它们之间共享的数据结构的访问。在SMP系统中,这些工作不需要更改。
许多实时系统还需要保护对中断处理程序和拥有该处理程序的线程之间共享数据结构的访问。线程间使用的传统POSIX原语不能供中断处理程序使用。这里有两个解决方案:
•一个是从中断处理程序中删除所有工作,并在线程时执行所有工作。考虑到我们的快速线程调度,这是一个非常可行的解决方案。
•在运行QNX Neutrino RTOS的单处理器系统中,中断处理程序可能抢占线程,但线程永远不会抢占中断处理程序。这允许线程通过在非常短的时间内禁用和启用中断来保护自己不受中断处理程序的影响。
非smp系统上的线程用以下代码保护自己:

不幸的是,这段代码将在SMP系统上失败,因为线程可能在一个处理器上运行,而中断处理程序同时在另一个处理器上运行!
更好的解决方案是使用线程和中断处理程序都可以使用的新的排除锁。这是由以下原语提供的,它们在单处理器和SMP机器上都可以工作:
InterruptLock(intrspin_t* spinlock )
尝试获取一个自旋锁,一个在中断处理程序和线程之间共享的变量。代码将在一个紧密的循环中旋转,直到获得锁为止。在禁用中断之后,代码将获得锁(如果线程获得了锁)。锁必须尽快释放(通常在几行C代码中没有循环)
InterruptUnlock(intrspin_t* spinlock )
释放锁并重新启用中断。
混合多处理(BMP)
绑定多处理提供了非对称多处理模型的调度控制,同时保留了对称多处理的硬件抽象和管理。
BMP与SMP类似,但是可以指定线程可以在哪个处理器上运行。可以在同一个系统上同时使用SMP和BMP,允许一些线程从一个处理器迁移到另一个处理器,而其他线程则被限制为一个或多个处理器。
与SMP一样,操作系统的一个副本维护所有系统资源的总体视图,允许在应用程序之间动态分配和共享它们。但是,在应用程序初始化期间,由系统设计器确定的设置强制应用程序的所有线程只在指定的CPU上执行。
与全SMP操作相比,这种方法有以下几个优点:
•通过允许共享相同数据集的应用程序只在相同的CPU上运行,可以消除缓存抖动,从而降低SMP系统的性能。
•它提供了比SMP更简单的应用程序调试,因为应用程序中的所有执行线程都运行在单个CPU上。
•通过让共享数据在单个CPU上运行,它可以帮助使用技术同步共享数据的遗留应用程序正确运行。(这句如何准确翻译?)
对于BMP,锁定在一个CPU上的应用程序不能使用其他CPU,即使它们是空闲的。然而,QNX Neutrino RTOS允许动态地更改指定的CPU,而无需进行检查点,然后停止并重新启动应用程序。
QNX Neutrino通过runmask支持硬处理器的概念。runmask中设置的每个位都代表一个线程可以运行的处理器。默认情况下,线程的runmask设置为所有的,允许它在任何处理器上运行。0x01的值将允许线程只在第一个处理器上执行。
默认情况下,进程或线程的子进程不会继承runmask;有一个单独的继承掩码。
通过仔细使用这些掩码,系统设计人员可以进一步优化系统的运行时性能(例如,将非实时进程降级到特定处理器)。但是,通常情况下,这是不必要的,因为当高优先级的线程准备就绪时,实时调度器总是会立即抢占低优先级的线程。处理器锁定可能只会影响缓存的效率,因为可以防止线程迁移。可以通过以下方式为新线程或进程指定runmask:
•设置继承结构的runmask成员,并在调用spawn()时指定spawn_speciit_cpu标记
或者:
•在启动程序时使用on实用程序的-C或-R选项。这也将进程的继承掩码设置为相同的值。
可以通过以下方式更改现有线程或进程的runmask:
•使用_NTO_TCTL_RUNMASK或_NTO_TCTL_RUNMASK_GET_AND_SET_INHERIT命令到ThreadCtl()内核调用
或者:
•使用slay实用程序的-C或-R选项。如果还使用-i选项,slay会将继承掩码设置为相同的值。
可行的迁移策略
作为AMP和SMP之间的中点,BMP提供了一种可行的迁移策略,如果希望实现完整的SMP,但是担心现有代码可能在真正的并发执行模型中不正确地运行。
可以将遗留代码移植到多核系统,并最初将其绑定到单个CPU,以确保正确的操作。通过明智地将应用程序(可能是单个线程)绑定到特定的cpu,可以将潜在的并发问题隔离到应用程序和线程级别。解决这些问题将允许应用程序完全并发运行,从而最大化多处理器提供的性能收益。
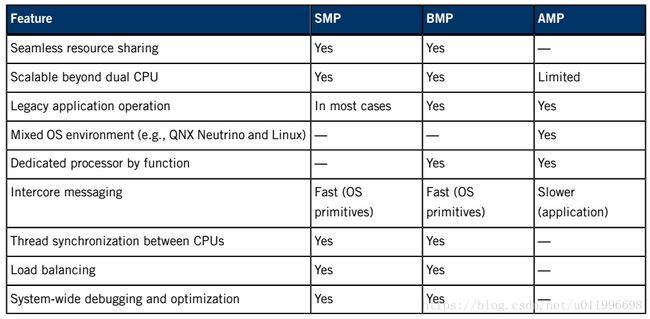
AMP、SMP和BMP之间选择
AMP、SMP和BMP之间的选择取决于您试图解决的问题:
•AMP可以很好地处理遗留应用程序,但在两个cpu之外的可伸缩性有限。
•SMP提供了透明的资源管理,但是还没有为并发性设计好的软件可能会有问题。
•BMP提供了许多与SMP相同的优点,但保证了单处理器应用程序将正确运行,极大地简化了遗留软件的迁移。如下表所示,从这些模型中进行选择的灵活性能够在性能、可伸缩性和易于迁移之间取得最佳平衡。