深度之眼Pytorch框架训练营第四期——Hook函数与CAM算法
文章目录
- Hook函数与CAM算法
- 1、Hook函数概念
- 2、Hook函数与特征图提取
- (1)`Tensor.register_hook`
- (2)`Module.register_forward_hook`
- (3)`Module.register_forward_pre_hook`
- (4)`Module.register_backward_hook`
- (5)采用hook函数,实现特征图可视化
- 3、CAM(class activation map,类激活图)
Hook函数与CAM算法
1、Hook函数概念
Hook 是 PyTorch 中一个十分有用的特性。利用它,我们可以不必改变网络输入输出的结构,方便地获取、改变网络中间层变量的值和梯度。这个功能被广泛用于可视化神经网络中间层的 feature、gradient,从而诊断神经网络中可能出现的问题,分析网络有效性。总的说来,一共有四种Hook函数:
- torch.Tensor.register_hook(hook)
- torch.nn.Module.register_forward_hook
- torch.nn.Module.register_forward_
pre_hook
- torch.nn.Module.register_backward_hook
2、Hook函数与特征图提取
(1)Tensor.register_hook
- 功能:注册一个反向传播hook函数,Hook函数仅一个输入参数,为张量的梯度
hook_fn(grad) -> Tensor or None
- 使用方法:
.register_hook(hook_fn),其中hook_fn为一个用户自定义的函数,输出为一个 Tensor 或者是 None (None 一般用于直接打印梯度)。反向传播时,梯度传播到变量 z,再继续向前传播之前,将会传入hook_fn。如果hook_fn的返回值是 None,那么梯度将不改变,继续向前传播,如果hook_fn的返回值是Tensor类型,则该Tensor将取代 z 原有的梯度,向前传播。 - 实例:
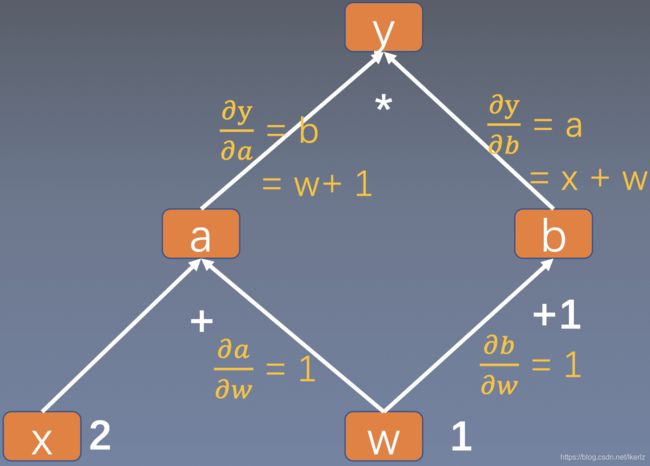
从上面的计算图可以看出, a a a, b b b, y y y均不是叶子结点,因此在反向传播时,梯度会被清除,那么应该得到这些节点的梯度呢?
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
a_grad = list()
def grad_hook(grad):
a_grad.append(grad)
handle = a.register_hook(grad_hook)
y.backward()
# 查看梯度
print("gradient:", w.grad, x.grad, a.grad, b.grad, y.grad)
print("a_grad[0]: ", a_grad[0])
handle.remove()
# gradient: tensor([5.]) tensor([2.]) None None None
# a_grad[0]: tensor([2.])
从上面可以看出,对节点 a a a注册一个函数后,可以得到 a a a的梯度,那么应该如何通过注册函数修改梯度呢?
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
a_grad = list()
def grad_hook(grad):
grad *= 2
return grad*3
handle = w.register_hook(grad_hook)
y.backward()
# 查看梯度
print("w.grad: ", w.grad)
handle.remove()
# w.grad: tensor([30.])
grad_hook相当于是对输入的梯度乘6,因此得到的是30,如果注释掉return grad*3,则输出的结果为w.grad: tensor([10.])
上面的hook函数是针对Tensor的hook函数,然而它的使用场景一般不多,最常用的 hook 是针对神经网络模块的。网络模块 module 不像上一节中的 Tensor,拥有显式的变量名可以直接访问,而是被封装在神经网络中间。我们通常只能获得网络整体的输入和输出,对于夹在网络中间的模块,我们不但很难得知它输入/输出的梯度,甚至连它输入输出的数值都无法获得。除非设计网络时,在 forward 函数的返回值中包含中间 module 的输出,或者用很麻烦的办法,把网络按照 module 的名称拆分再组合,让中间层提取的 feature 暴露出来
因此为了解决这个麻烦,PyTorch设计了两种 hook:register_forward_hook和 register_backward_hook,分别用来获取正/反向传播时,中间层模块输入和输出的 feature/gradient,大大降低了获取模型内部信息流的难度。
(2)Module.register_forward_hook
- 功能:注册module的前向传播hook函数,作用是获取前向传播过程中,各个网络模块的输入和输出
- 使用方式:
module.register_forward_hook(hook_fn),hook_fn为:
hook_fn(module, input, output) -> None
module为模块,input为模块的输入,output为模块的输出
- 实例:
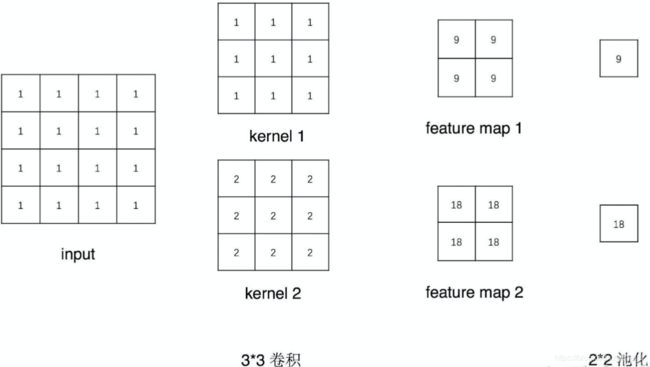
通过代码实现上图中各层输入与输出
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
return x
def forward_hook(module, data_input, data_output):
fmap_block.append(data_output)
input_block.append(data_input)
# 初始化网络
net = Net()
net.conv1.weight[0].detach().fill_(1)
net.conv1.weight[1].detach().fill_(2)
net.conv1.bias.data.detach().zero_()
# 注册hook
fmap_block = list()
input_block = list()
net.conv1.register_forward_hook(forward_hook)
# inference
fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W
output = net(fake_img)
# 观察
print("output shape: {}\noutput value: {}\n".format(output.shape, output))
print("feature maps shape: {}\noutput value: {}\n".format(fmap_block[0].shape, fmap_block[0]))
print("input shape: {}\ninput value: {}".format(input_block[0][0].shape, input_block[0]))
# output shape: torch.Size([1, 2, 1, 1])
# output value: tensor([[[[ 9.]],
#
# [[18.]]]], grad_fn=)
#
# feature maps shape: torch.Size([1, 2, 2, 2])
# output value: tensor([[[[ 9., 9.],
# [ 9., 9.]],
#
# [[18., 18.],
# [18., 18.]]]], grad_fn=)
#
# input shape: torch.Size([1, 1, 4, 4])
# input value: (tensor([[[[1., 1., 1., 1.],
# [1., 1., 1., 1.],
# [1., 1., 1., 1.],
# [1., 1., 1., 1.]]]]),)
(3)Module.register_forward_pre_hook
- 功能:注册module前向传播前的hook函数,用于查看网络层输入的数据
- 参数:
- module:当前网络层
- input:当前网络层输入数据
hook_fn(module, input) -> None
(4)Module.register_backward_hook
- 功能:注册module反向传播的hook函数
- 参数:
- module:当前网络层
- grad_input:当前网络层输入梯度数据
- grad_output:当前网络层输出梯度数据
hook_fn(module, grad_input, grad_output) -> Tensor or None
(5)采用hook函数,实现特征图可视化
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 数据
path_img = "./lena.png" # your path to image
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
norm_transform = transforms.Normalize(normMean, normStd)
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
norm_transform
])
img_pil = Image.open(path_img).convert('RGB')
if img_transforms is not None:
img_tensor = img_transforms(img_pil)
img_tensor.unsqueeze_(0) # chw --> bchw
# 模型
alexnet = models.alexnet(pretrained=True)
# 注册hook
fmap_dict = dict()
for name, sub_module in alexnet.named_modules():
if isinstance(sub_module, nn.Conv2d):
key_name = str(sub_module.weight.shape)
fmap_dict.setdefault(key_name, list())
n1, n2 = name.split(".")
def hook_func(m, i, o):
key_name = str(m.weight.shape)
fmap_dict[key_name].append(o)
alexnet._modules[n1]._modules[n2].register_forward_hook(hook_func)
# forward
output = alexnet(img_tensor)
# add image
for layer_name, fmap_list in fmap_dict.items():
fmap = fmap_list[0]
fmap.transpose_(0, 1)
nrow = int(np.sqrt(fmap.shape[0]))
fmap_grid = vutils.make_grid(fmap, normalize=True, scale_each=True, nrow=nrow)
writer.add_image('feature map in {}'.format(layer_name), fmap_grid, global_step=322)
3、CAM(class activation map,类激活图)
CAM 指的是经过 W W W加权的特征图集重叠而成的一个特征图。它可以显示模型做出分类决策的依据主要来自于特征图集中的哪些特征图。

如上图所示,CAM关注最后一个特征图,并将最后一特特征图提取出来,乘上权值,再相加,得到了右下角的类激活图,可以看到,这里更关注的是狗的特征。
但是CAM并不是很实用,因为需要通过一个GAP(Global Average Pri)过程,将特征图转换为神经元,但是在实践的模型分析中,我们需要神经元网络层,再进行训练。因此一种更实用的算法——Grad-CAM被提出,其思路是利用梯度作为特征图权重

从上图可以看出,在得到特征图A后,对向量 y y y求导,然后在于在与特征图加权平均,最后用ReLU函数激活