UFLDL深度学习编程练习1: 多层神经网络
作为一个刚踏入machine learning领域的小白,在学习的时候遇到很重要的问题是看了理论知识之后,没有练习,导致理解不深入。比如神经网络,没有实现之前,看过教程,看过论文,但对其技术细节却不了解。实践是检验真理的唯一标准,动手实现机器学习算法,就对机器学习的整个思路有了一个清晰的了解。在接下来这几篇博客中,总结一下自己做过的UFLDL的一些练习,如有错误,恳请赐教。
神经网络

首先回忆一下神经网络这个概念,而这应当先提到神经元,神经元实际上是想模仿生物神经元的工作机制,如上图,给神经元信号,如果信号超过了某个阈值,那么这个神经元会把这个信号传播到下一个神经元。多个神经元组合起来就形成了神经网络。其数学表示是
激发函数一般选择sigmoid, tanh,有的论文中还有其他的一些非线性激发函数,不过由于自己太浅薄,所以现在不懂。
综上所述,神经网络一般有三层,输入层,隐层,输出层,隐层的神经元接受从输入层传递过来的信号的线性组合,然后激发,得到的值是输入单元的非线性函数。而从隐层到输出层,可以选择诸如softmax regeression之类的分类方法,从而得到最终结果
而多层神经网络或者说深度神经网络就是有多个隐层的神经网络,如下图,每个隐层的传递激发机制都是一样的,但也有一些其他类型的,比如卷积神经网络,这个在后面的博客中会提到。
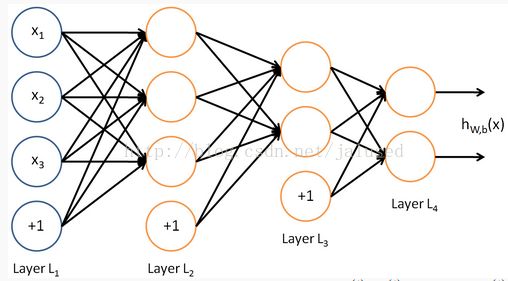
多层神经网络编程练习
练习题链接: http://ufldl.stanford.edu/tutorial/supervised/ExerciseSupervisedNeuralNetwork/
完成的代码: https://github.com/Jallet/stanford_dl_ex-master/tree/master/multilayer_supervised
有需要的朋友可以参考代码。
首先从UFLDL的教程中可以看到要实现的是一个三层的神经网络,输入是手写数字图片,激发函数可以是sigmoid函数或其他,在这里我们选择sigmoid函数;然后用隐层的输出作为softmax regeression的输入,输出层是10个类,也就是0-9十个数字。
因为大部分代码教程作者已经给出,我们需要实现的代码很少,只需要实现supervised_dnn_cost.m中的前向传播,损失函数计算,误差反向传播。
前向传播
前向传播分为两部分,输出层和隐藏层,隐藏层和隐藏层之间的传播以及最后一个隐藏层和输出层之间的传播,在这个题目中只有一个隐藏层,所以没有隐藏层之间的传播,不过这丝毫不影响我们写代码。
输入层到隐藏层:
z{l + 1} = stack{l}.W * data;
b = repmat(stack{l}.b, 1, size(a{l}, 2));
z{l + 1} = z{l + 1} + b;
a{l + 1} = 1 ./ (1 + exp(-1 * z{l + 1}));
可以看到,先对输入层的data进行线性组合,加上偏置,然后用sigmoid函数激发得到a{l+1}。
隐藏层到输出层:
temp = stack{numHidden + 1}.W * a{numHidden + 1};
b = repmat(stack{numHidden + 1}.b, 1, size(a{numHidden + 1}, 2));
temp = temp + b;
temp = exp(temp);
sumtemp = sum(temp, 1);
sumtemp = repmat(sumtemp, size(temp, 1), 1);
pred_prob = temp ./ sumtemp;从隐藏层到输出层是一个普通的softmax,如果做过UFLDL的softmax exercise,那这里就很简单了;这里算出来的pred_prob就是每张图片分别属于十个类的概率矩阵,在测试集预测及损失计算会用到。
到这里,神经网络的正向执行就结束了。
损失函数计算
有了预测数据和label监督信息,就可以计算损失函数了;这个函数也就是标准的softmax损失函数。

这里只要在pred_prob中每一列(即每个训练数据)选出该训练数据属于的类的概率,相加求相反数就得到损失函数,前面的教程中也给出了简单的求损失函数的方法,函数sub2ind可以从矩阵中每一列中选出自己想要的那个元素,需要注意的是这个损失函数是UFLDL旧版本的损失函数,和新版本的相差一个常数项1 / m,参考新版本的更新W和b的规则,应该使用上面的J(θ),当然也可以使用没有1 / m的损失函数,同时去掉W,b的更新规则中的1 / m。
I = sub2ind(size(pred_prob), labels', 1 : size(pred_prob, 2));
f = log(pred_prob(I));
ceCost = -1 * sum(f(:)) ./ m;误差反向传播
误差反向传播是BP算法最重要的一部分,其思想是l层的节点i的误差是由(l - 1)层所有与其相连的节点共同贡献的,而贡献的大小有权值W决定,所有在已知l层节点i的误差δi时,那么按权值大小将其分配到(l - 1)层与其相连的节点上。所以可以得到计算δ的公式
输出层的误差公式
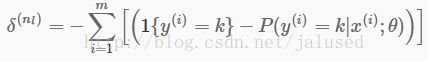
这个公式中有点错误,δ应该有个小标k。
for i = 1 : numHidden
l = numHidden - i + 2;
delta{l} = stack{l}.W' * delta{l + 1};
d = a{l} .* (1 - a{l});
delta{l} = delta{l} .* d;
这样一来,我们可以输出层到第一个隐层,算出每一层每个节点的δ,然后通过下面公式计算梯度
根据参数更新规则
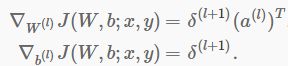
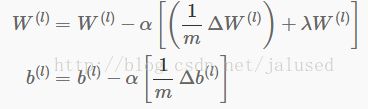
计算出α后面括号中的向即可。
for l = 1 : numHidden + 1
gradStack{l}.W = delta{l + 1} * a{l}' ./ m;
gradStack{l}.W = gradStack{l}.W + stack{l}.W * ei.lambda;
gradStack{l}.b = delta{l + 1};
gradStack{l}.b = sum(gradStack{l}.b, 2) ./ m;
end
总结
以上就是我们完成这个练习的所有步骤及其基本公式,由于我不熟悉公式的具体推导过程,所以没有写出,想了解细节的同学,可以自己推导,应该不难。这个是最简单的神经网络,但由于我以前没怎么用过matlab,对matlab的矩阵运算上花了不少时间,写这个博客也是加深一下印象。
Reference:
http://ufldl.stanford.edu/tutorial
http://blog.csdn.net/zouxy09/article/category/1387932(推荐这个深度学习的博客,非常好)