【DiMP】Learning Discriminative Model Prediction for Tracking论文阅读
Learning Discriminative Model Prediction for Tracking 论文地址
写在前面
又是MD大神的一个作品,发现MD大神也把Siamese的框架用起来了,而且一用就解决了Siamese这个框架的三大固有问题,论文还是延续了我看不懂的风格,很多机器学习和概率统计中的知识,自己基础不够扎实了。
Motivation
- Siamese的网络框架一般都只是把模板割出来,忽略了背景信息的利用,而背景的信息对目标的检测定位也是至关重要的;
- 因为跟踪一般都是很多没有见过的类,通过offline学习的相似性度量可能不是很适用;
- Siamese的框架没有一个合适的模型更新方式。
Contribution
- 解决了上面三个问题。。。
- 速度很快,40帧左右,在各大benchmark上都是state-of-the-art的结果。
Algorithm
这块比较难懂,我就简单讲一下。这篇文章的理论基础在于:1)一个判别力强的损失函数可以指导网络学到鲁棒的特征;2)一个powerful的优化器可以加快网络收敛
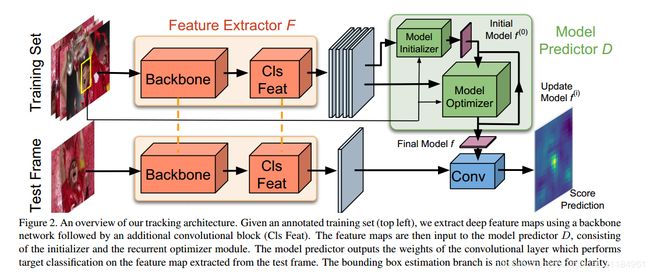
上图就是本文的网络结构,前面的额backbone网络就是用来提特征的,然后这个特征后面加了一个卷积block来对特征进行分类?(文章里好像就没说这个东西,就在ablation实验中做了)。训练用的是一个集合的方式,得到多个不同的feature map,然后再通过Model Predictor D来预测最终用来分类的模型f,接下来简单介绍一下文中的各个部分。
1 Discriminative Learning Loss
他们提出了一个概念,就是单纯以图片对方式训练,传统的岭回归问题只会让网络过分注意于优化负样本的影响,而忽略了学到的正样本的特征本身的判别能力。为了解决这个问题,他们用了SVM中使用的hinge-like 损失,就是不仅将前景背景分开,更加使得两类之间有一定的距离,使得分类结果更好。
最后他们将背景类的loss都量化成 >=0 的,其实就像focal loss那样,不过他们是直接把那些简单的负样本去掉,最后的损失函数定义如下:
![]()
其中mc代表target的mask,正样本就用正样本的score,负样本的话就用大于零的,即被错分的样本。这里和别人的文章不一样的地方是,它的 m c , v c , λ , y c m_c, v_c, \lambda, y_c mc,vc,λ,yc 都是网络中自己学到的,并不是人工指定的。
2 Optimization-Based Architecture
他们表示使用固定的学习率不仅会导致模型迭代次数多,获得的精度也不够理想,所以他们自己设计了一个梯度下降的方式,自适应的学到学习率。这里的策略就是希望梯度下降沿着最陡的方向走(好像是很多年前机器学习理论里的优化方式),这一块文章里贴了公式和说明,但是我看不懂,就不详细讲了。
3 Initial filter prediction
这个模型初始化就是将所有的bbox里面的东西取平均,就像原始的Siamese网络一样,只不过在这里只用于初始化,后面还会训练更新。
4 Learning the Discriminative Loss
这个部分就解释了刚刚公式2和其中的参数是如何学习的, m c , v c , λ , y c m_c, v_c, \lambda, y_c mc,vc,λ,yc 都是根据与目标中心距离决定的,不过不是简单的高斯,而是转化到对偶空间求,啊~看不懂。反正这些东西都是自适应的,代码开源了之后会更容易懂一些吧。
5 Offline Training
训练的时候是用多个图片对训练的 ( M t r a i n , M t e s t ) (M_{train}, M_{test}) (Mtrain,Mtest), 这些样本是从同一个序列中抽样出来的,对于给定的样本对,先是用特征提取网络提取到对应的特征 ( S t r a i n , S t e s t ) (S_{train}, S_{test}) (Strain,Stest),得到的特征输入到D网络中得到滤波器f, 这个文章的目的就是学到一个可以推广到没见过帧的特征。然后将f 在 S t e s t S_{test} Stest上测试,然后计算一个损失:
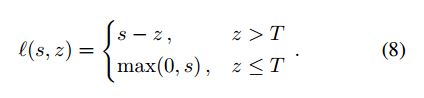
这里就是之前提到的Hinge-like损失函数,T表示前景和背景,所以这里只惩罚背景样本。这里他们为了提升模型鲁棒性,不仅最小化每个损失,而是对每次迭代的损失都做约束,这就相当于一个中间的监督:
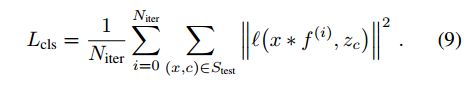
迭代次数也不是指定的,而是自适应的。上诉公式中 z c z_c zc 是一个高斯型的mask中心位于bbox的中心,在BBOX回归的地方,他们用了IOUNet来做。最终的损失函数为:
L t o t = β L c l s + L b b L_{tot} = \beta L_{cls} + L_{bb} Ltot=βLcls+Lbb
6 Online Tracking
对于给定的第一帧,他们用数据增强方式添加了15个样本,然后用10次梯度下降来学习f,在模型更新过程中,他们保持最新的50个样本,每20帧更新一次。
Experiment
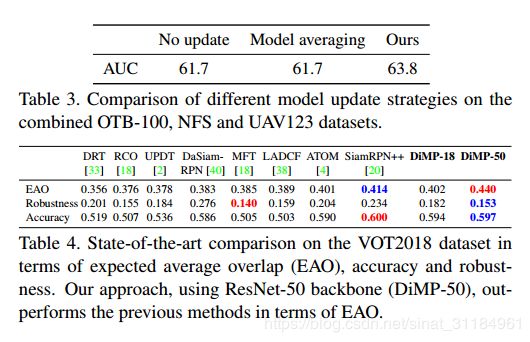
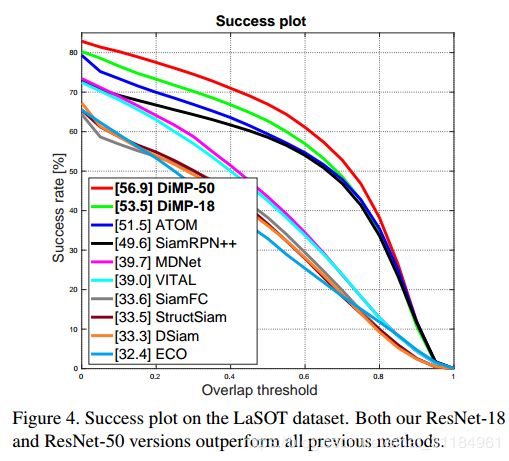
效果很好,用一张GTX 1080能跑到57FPS(ResNet-18),43FPS(ResNet-50)。
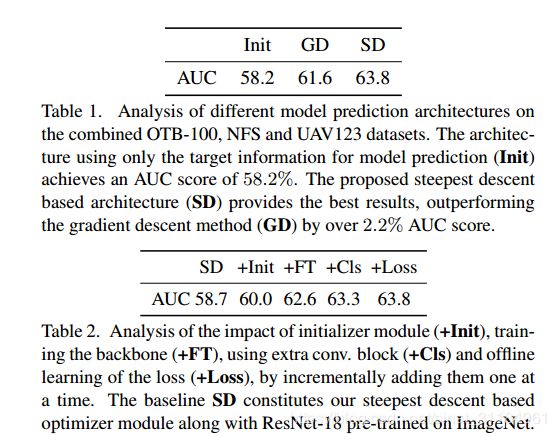
总结
解决了Siamese这个结构的三大毛病,可以说是很厉害了,然后里面的一些想法也值得我们借鉴,比如扩大前景和背景的距离,使得特征分类更好。