独家 | 如何解决深度学习泛化理论

作者:Dmytrii S.
翻译:陈之炎
校对:卢苗苗
本文共2360字,建议阅读5分钟。
本文与大家讨论深度学习泛化理论中的一些经验并试图对它做出解释。
我们可以从最新的关于深度学习“炼金术”的悖论研究中了解一二。
动机
深度学习目前正被用于方方面面。但是,人们经常批评它缺乏一个基础理论,能够完全解释其为什么能如此神奇。最近,神经信息处理系统大会(NIPS)的时间测试奖(Test-of-Time)得主将深度学习比作“炼金术”。
尽管解释深度学习泛化理论仍然是一个悬而未决的问题,在这篇文章中,我们将讨论这个领域最新的理论和先进的经验,并试图对它做出解释。
深度学习的悖论
深度学习的一个“显而易见的悖论”是:尽管在实际问题中它具有大容量、数值不稳定、尖锐极小解(SharpMinima)和非鲁棒性等特点,它在实践中可以很好地推广。
在最近的一篇文章《理解深度学习需要反思泛化》里表明:深度神经网络(DNN)具有足够大的存储容量去记住带有随机标签的ImageNet和CIFAR10数据集。目前尚不清楚为什么他们在真实数据找到了可泛化的解决方案。
深层架构的另一个重要问题是数值不稳定性。在基于导数的学习算法中,数值不稳定性通常被称为梯度消失。底层正向模型的不稳定性导致了更大的难度。也就是说,对于原始特征中的小扰动,某些网络的输出可能是不稳定的。在机器学习中,它被称为非鲁棒性。其中一个例子是图1所示的对抗性攻击。
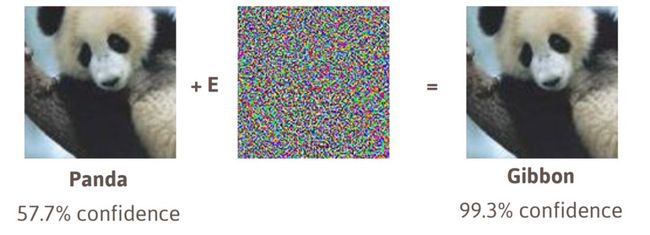
图1:来源:带有对抗攻击示例的机器学习
一些研究将深度学习的泛化论点建立在通过随机梯度下降(SGD)从而找到损失函数的最小平坦度上。然而,最近的研究表明:“尖锐极小解(Sharp Minima)对于深度网络同样具有更好的泛化能力”。更具体地说,通过重新参数化可以将平坦极小解转化为尖锐极小解,而不改变泛化能力。因此,泛化不能仅用参数空间的鲁棒性来解释。
泛化理论
泛化理论的目的是解释和证明为什么和如何提高训练集的准确率。这两个准确率之间的差异称为“泛化误差”或“泛化间隙”。从更严格的意义上,泛化间隙可以被定义为在给定学习算法A的数据集SM上的函数F的不可计算的预期风险和可计算的经验风险之间的差:
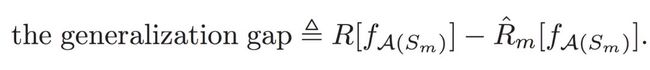
本质上,如果我们将泛化间隙的上界设定成一个小的数值,它将保证深度学习算法f在实际中很好地泛化。泛化间隙的多个理论上界取决于模型的复杂度、稳定性、鲁棒性等。
深度学习的模型复杂性有两种:Rademacher复杂性和Vapnik‑Chervonenkis(VC)维度。然而,对于已知的上界的深入学习函数f, Radamacher复杂性随着网络深度的增长成指数级增长。这与实际观察的结果恰恰相反,适合的训练数据网络深度越大,经验误差就越小。同样,泛化间隙的上界基于VC维度和训练参数呈线性增长,不取决于深度学习中的实际观察值。换句话说,这两个上界限均太保守。
最近,KKawaguchi、LPKELING和YBengio提出了更为有用的办法。与其他人不同,他们接受了这样一个事实,即通常使用训练验证范式培训深度学习模型。他们使用验证错误替代非可计算的预期风险和训练错误。在这种观点中,他们针对为什么深度学习能泛化得如此完美而提出了以下观点:“我们之所以可以泛化得这么很好是因为我们可以利用验证的错误,通过模型搜索得到一个好的模型,并证明对于任何δ > 0,概率至少为1-δ:
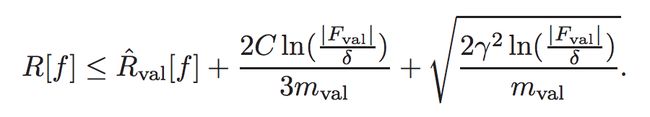
重要的是:|Fval|是我们利用验证数据集来选择最终模型进行决策的次数,M是验证集的大小。这一数值可以用来解释为什么深度学习可以泛化得如此好,尽管可能带来不稳定、非鲁棒性和尖锐利极小解(Sharp Minima)。还有一个悬而未决的问题是:为什么我们能够找到导致低验证错误的体系结构和参数。通常,架构的灵感来自真实世界的观察和通过使用SGD搜索到的良好的参数,我们会在下文进行讨论:
随机梯度下降(SGD)
SGD是现代深度学习的内在组成部分,显然是其泛化背后的主要原因之一。接下来我们将讨论它的泛化属性。
在最近的一篇论文《随机梯度下降的数据相关稳定性》中,作者证明了在某些附加损失条件下,SGD是平均稳定算法。这些条件在常用的损失函数中就可以得到满足,例如在激活函数是sigmoid函数的神经网络中通常用到Logistic/Softmax损失函数。在这种情况下,稳定性意味着SGD对训练集中的小扰动有多敏感。他们进一步证明了非凸函数(如深度神经网络)中SGD泛化间隙的平均数据上界的数据相关性:
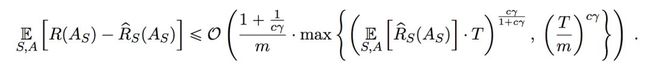
其中m是训练集的大小,T是训练步长,γ表征了初始点的曲率对稳定性的影响。从中至少可以得出两个结论。首先,目标函数在初始化点附近的曲率对目标函数的初值有着至关重要的影响。从一个低风险的曲率较小的区域中的一个点开始,能产生更高的稳定性,即更快地泛化。在实践中,它可以是一个很好pre-screen决策,以选择良好的初始化参数。第二,考虑到通过率,即m=O(T),我们简化了对O(M)的上界。即训练集越大,泛化差距越小。
有趣的是,有大量的研究正在探究学习曲线。其中大部分显示幂律泛化误差,缩放比例为ε(m)-mm,指数β=−0.5或−1。这也与前面讨论过的结论一致。然而,很重要的是,百度做了大量的研究,已能够凭经验观察到这一幂律(见图2)。实际应用中的指数β介于−0.07和−0.35之间,这一数值还必须得到理论上的解释。
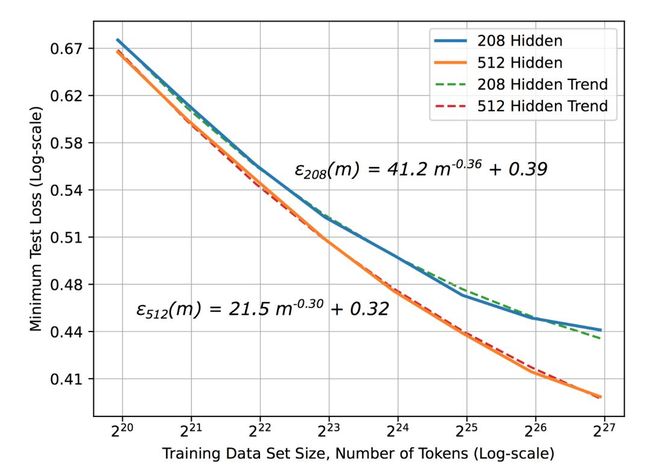
图2 资料来源:深度学习的缩放比例是可预测的,经验值。
此外,SGD泛化中关于批量大小(一个批量中样本的数量)有理论值和经验值两种。直观地说,小批量训练会在梯度上引入噪音,这种噪音会使SGD远离最小的极小值,从而增强泛化能力。在谷歌最近的一篇论文中,它表明批量大小的优化与学习速率和训练集大小成比例。或者简单地说,“不牺牲学习速率,增加批量大小”。同样的缩放规则来自SGD动量:Bopt ~1/(1 − m), Bopt是优化的批量大小,m是动量。或者,所有结论都可以用下面的等式来概括:

ε是学习速率(learningrate),N为训练集的大小,m是动量和B是批量大小。
结论
在过去的几年里,人们对深度学习的基础理论中悖论越来越感兴趣。尽管仍然存在一些尚未解决的研究问题,但现代深度学习绝不是所谓的炼金术。在本文中,我们讨论了这个问题的泛化观点,得出了一些实际的结论:
在曲率较小和风险较低的区域选择初始化参数。用Hessian向量乘法可以有效地估计曲率。
在改变动量时,对批次的大小进行缩放。
不牺牲学习速率,增加批量大小。
原文链接:https://medium.com/mlreview/modern-theory-of-deep-learning-why-does-it-works-so-well-9ee1f7fb2808
译者简介

陈之炎:北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~

点击“阅读原文”拥抱组织