Hierarchical Question-Image Co-Attention
主要做了四个方面的改进:
1、为VQA提出了一个co-attention mechanism,能够联合问题主导的visual attention和图片主导的question attention。用两种策略实现这个mechanism,分别为parallel co-attention 和 alternating co-attention。
2、提出了一个层架构来represent question。并且最终通过3个不同的levels组建image-question co-attended maps.分别为:word level , phrase level和question level。这些co-attended特征是递归的从word level到question level,从而获得最终的answer prediction。
3、在phrase level,提出了一个新的卷积池化策略(convolution-pooling strategy)来 选择合适的传送给question level的phrase sizes.
4、最后,在两个大的数据集合上对模型进行了验证,VQA数据集和COCO-QA数据集。还使用了ablation studies(消融研究)来量化不同组件在模型中的作用。
方法:
1. Notation

给定一个有T个word的question,它的表示形式为。。。,qt是第t个word的feature vector。q(t,w),q(t,p),q(t,s)分别代表在位置t处的word embeding, phrase embeding和question embeding。image feature表示为V={...},其中vn表示在位置n处的图像特征。每一层中的图像和问题的co-attention features表示为....。各个模型/层中的权重表示为W,对应不同的权重可以有不同的上标或下标。在下面的方程中,为了避免符号的混杂,忽略偏执。
2. Question Hierarchy(问题层面)

给定问题的one-hot编码的单词Q={巴拉巴拉},首先把单词变成一个vector空间(端到端学习)得到Qw={balabala}(指的是先把one-hot编码的单词变成word level的vector)。为了计算phrase特征,在word embeding vectors(上一步得到的vectors)上采用一维卷积。在每个word的位置,我们都采用三种窗口来计算word vectors的inner vector:单个单词,两个单词和三个单词。对于第t个单词,采用window size为s的卷积输出为:
(1)
W(c,s)是权重参数,(s表示的是窗口大小,c不知道表示的是啥)。在卷积之后,送到两个单词,和三个单词卷积之前,为了保持sequence的长度,word-level的Q(w)是0-padded的。基于得到的卷积结果,在每个word的位置上实行max-pooling来获得phrase-level features
(2)
我们的池化方式和之前别的论文中的方式不同。以往的方式在每个time step保存原始sequence 的长度和顺序的时候,是自适应的选择不同的gram features。而我们使用一个LSTM编码池化之后的序列(就是上面的(2))。相关的question-level feature q(t,s)是在t时刻的LSTM隐藏vector。
层级表示question的表示如下:
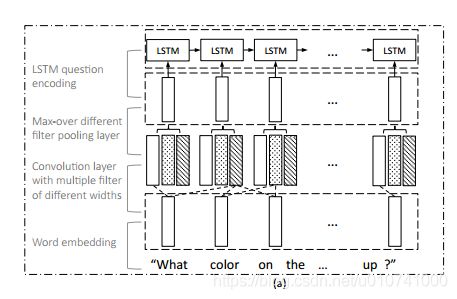
可以看到先是进行word embeding,然后将embeding输出的结果经过不同宽度的filter(就是上面说的单个单词长度,两个单词长度,三个单词长度)卷积,然后对不同filter宽度的结果采用max,然后再经过LSTM 的question encoding,得到相应的qeustion feaature。
3. Co-Attention
这部分作者给了两种co-attention mechanisms,这两个mechanism的不同之处在于image和question 的 attention maps产生的顺序不同。第一种mechanism叫做parallel(同步) co-attention,同时生成image和question attention maps。第二种mechanism叫做alternating co-attention机制,是一定的顺序交替生成image attention和question attention。这两个co-attention机制都是在question hierarchy的三层上的基础上进行操作的。
Parallel Co-Attention:
parallel co-attention趋向于同时生成image 和question attention maps。我们通过计算所有image-locations和question-loacations的image 和 question对儿的相似性来connect the image and question。特殊的是,当给定一个image feature map V, 和一个question representation Q,相似矩阵C是通过如下计算得到的:

Wb是要学习的weights。在计算完相似性矩阵之后,一种可行的计算image(or question)attention的方法就是在其他模态的location上简单的取出相似性最大的值,作为相应的image (or question) attention。例如:图片的attention: a(v)[n] = max(i)(C(i,n))以及问题的attention: a(q)[n] = max(j)(C(t,j))。与采用最大激活相比,我们返现如果只讲相似性矩阵视为一个feature来预测image和question attention maps,这种方法能够很大的提高性能: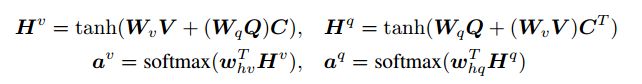
其中W(v),W(q), w(h,v), w(h,q)都是要权重参数。a(v)和a(q)是最后我么要得到的每个区域(v(n))和word(q(t))的attention probabilities。相似性矩阵C能够把question attention space转成image attention space(相反的就通过C的转置,能过把image attention space转换成question attention space)。基于以上的attention weights,image和question的attention vectors是图像和问题特征的加权和。
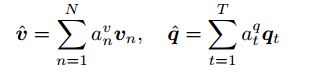
parallel co-attention是在每个hierarchy的每个level完成的,最后生成![]()
其中r属于{w,p,s}。
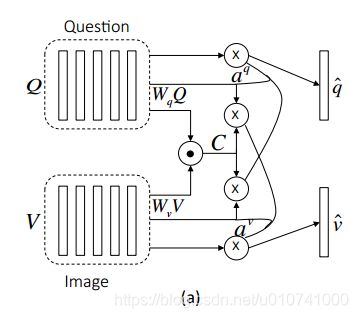
Alternating Co-Attention:
简明的说,这部分包含三个阶段:
(1)把question总结为一个单一向量q;(2)在q的基础上处理image ;(3)在image feature的基础上处理question.
定义一个attrntion操作![]()
这个函数的参数为image feature(or question feature)X和question (or image)的attention gudiance g作为输入,并且输出attended image(or question)vector。公式如下:
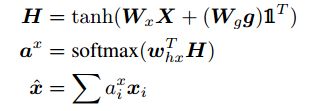
其中(奇怪的1)是一个所有元素都为1的向量,W(x),W(g)和w(h,x)是参数。a(x)是feature X的attention weight。
交替co-attention过程的图示:
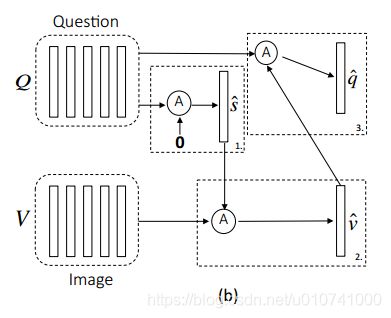
在第一阶段X= Q,g是0向量;在第二阶段,X= V,V是image features,并且guidance g是来自第一步的最终attended question feature:s; 最后,使用attended image feature v作为获取question的guidance。和parallel co-attention一样alternating co-attention也是在hierarchy的每个level完成的。
4、Encoding for Prediciting Answers
将VQA视为一个分类任务。我们基于三个level的attended image and question features预测结果。使用多层感知机(MLP)来递归编码attention features:

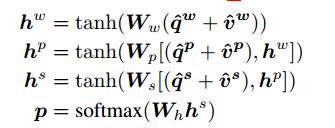
Ww; Wp; Ws and Wh 是weight参数,得到的p是最后的answer 的概率。