知乎爬虫与数据分析(二)pandas+pyecharts数据可视化分析篇(上)
注:代码完整版可移步Github——https://github.com/florakl/zhihu_spider。
知乎爬虫与数据分析(一)数据爬取篇
知乎爬虫与数据分析(三)pandas+pyecharts数据可视化分析篇(下)
目录
- 2 数据处理与可视化分析
- 2.1 热门问题的回答日期分布统计——“在问题提出后多久去发表回答更容易火起来?”
- 2.2 赞数与粉丝数的关系——“是不是高赞答主一般都自带粉丝?小透明还有戏吗?”
2 数据处理与可视化分析
这一部分主要用了pandas+pyecharts模块,附上pyecharts的官方文档。
2.1 热门问题的回答日期分布统计——“在问题提出后多久去发表回答更容易火起来?”
(1)准备工作
知乎的回答时间数据使用的是Unix时间戳格式(从1970-1-1起始的秒数),需要通过函数转换为一般的日期格式。
def time_format(numarray):
# 时间戳转换为年月日
t = time.localtime(numarray)
# f_t = time.strftime("%Y-%m-%d %H:%M:%S", t)
f_t = time.strftime("%Y-%m-%d", t)
return f_t
此外还有个排序的小函数,后面用了好几次。
def data_sort(x, y):
# 将两个数组按x的顺序同时排序
a = np.array(x)
b = np.array(y)
sorted_indices = np.argsort(a)
a1 = a[sorted_indices]
b1 = b[sorted_indices]
return a1.tolist(), b1.tolist()
(2)代码
读取时间数据——转换格式——补全缺失日期——可视化。
import pandas as pd
from datetime import datetime, timedelta
from pyecharts import options as opts
from pyecharts.charts import Bar, Scatter, Page
from util import time_format, data_sort
def readdata(filename):
# 读取单个问题的所有回答
with open(filename) as f:
lines = f.readlines()
qids = []
titles = []
ans_times = []
voteups = []
for i in range(0, len(lines), 4):
qids.append(lines[i].strip())
titles.append(lines[i + 1].strip())
ans_times.append(list(map(int, lines[i + 2].strip()[:-1].split(','))))
voteups.append(list(map(int, lines[i + 3].strip()[:-1].split(','))))
return qids, titles, ans_times, voteups
def data_full(x, y):
# 日期缺失值补全
date_list = x[:]
datestart = datetime.strptime(x[0], '%Y-%m-%d')
dateend = datetime.strptime(x[-1], '%Y-%m-%d')
while datestart < dateend:
datestart += timedelta(days=1)
temp = datestart.strftime('%Y-%m-%d')
if temp not in x:
date_list.append(temp)
y.append(0)
x1, y1 = data_sort(date_list, y)
return x1, y1
def visualize(voteup, ans_time, qid, title):
# 将所有回答按时间排序,并获取每个回答的年月日格式日期
d, v = data_sort(ans_time, voteup)
dates = []
for i in d:
dates.append(time_format(i))
# 提取前n个高赞回答作为标记点
n = 5
max_voteup = []
max_dates = []
z = sorted(zip(v, dates), reverse=True)
for i, j in z[:n]:
max_voteup.append(i)
max_dates.append(j)
max_data = []
for i in range(n):
markpoint = {}
markpoint['coord'] = [max_dates[i], max_voteup[i]]
markpoint['name'] = str(i + 1)
max_data.append(markpoint)
# 分组统计
data = {'日期': dates, '赞数': v}
df = pd.DataFrame(data)
groupnum = df.groupby(['日期']).size()
voteupsum = df['赞数'].groupby(df['日期']).sum()
voteupmax = df['赞数'].groupby(df['日期']).max()
voteupmean = df['赞数'].groupby(df['日期']).mean()
# 默认访问values,提取index需要写明
x = list(groupnum.index)
y1 = list(groupnum)
y2 = list(voteupsum)
y3 = list(voteupmax)
y4 = list(map(int, voteupmean))
# 日期补全
x0, y1 = data_full(x, y1)
_, y2 = data_full(x, y2)
_, y3 = data_full(x, y3)
_, y4 = data_full(x, y4)
# 获取相对天数列表
x1 = list(range(len(x0)))
bar = (
Bar(init_opts=opts.InitOpts(width="700px", height="350px"))
.add_xaxis(x0)
.add_yaxis('回答数', y1)
.extend_axis(xaxis_data=x1,
xaxis=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_align_with_label=True),
axisline_opts=opts.AxisLineOpts(
is_on_zero=False, linestyle_opts=opts.LineStyleOpts()
),
))
.extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts()))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title=title, title_link=f'https://www.zhihu.com/question/{qid}'),
xaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_align_with_label=True),
axisline_opts=opts.AxisLineOpts(
is_on_zero=False, linestyle_opts=opts.LineStyleOpts()
),
),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts()),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
legend_opts=opts.LegendOpts(pos_left="right"))
)
scatter = (
Scatter()
.add_xaxis(x0)
.add_yaxis("当日总赞数", y2, yaxis_index=1)
.add_yaxis("当日最高赞数", y3, yaxis_index=1,
markpoint_opts=opts.MarkPointOpts(data=max_data,
symbol='pin', symbol_size=50,
label_opts=opts.LabelOpts(color='#fff')))
.add_yaxis("当日平均赞数", y4, yaxis_index=1)
)
bar.overlap(scatter)
filename = f'{qid}-回答统计分析.html'
bar.render(filename)
print(f'{qid}-图表创建成功')
return bar
if __name__ == '__main__':
qids, titles, ans_times, voteups = readdata('answer_time.txt')
page = Page(layout=Page.SimplePageLayout)
# 循环add生成组合图表
for i in range(len(qids)):
# visualize(voteups[i], ans_times[i], qids[i], titles[i])
page.add(visualize(voteups[i], ans_times[i], qids[i], titles[i]))
page.render("回答统计分析.html")
(3)可视化分析
效果如图,在上方添加了一个相对天数的x轴。pyecharts可以生成html动态图表,展示比较方便。
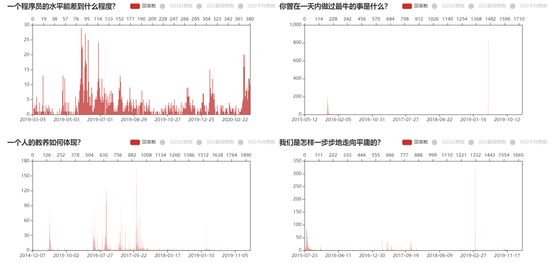

观察单个问题所有回答的时间分布,可以看出比较热门的问题大致可分为两种类型:细水长流型和昙花一现型。前者从问题提出开始,回答数陆陆续续增加,偶尔有个小高峰;后者则会经历在某个时期甚至某一天内的回答数爆发式增长,此后便杳无音讯,估计只有遇到相关热点事件时才会“翻红”,而这个几率显然是没法掌控的。
所以要想功利些让自己的回答被更多人看见,要么就赶时事热点,要么就找那种天天都有人回答有人看的日常性问题,少碰一些看上去回答数众多实则早已失去热度的问题。
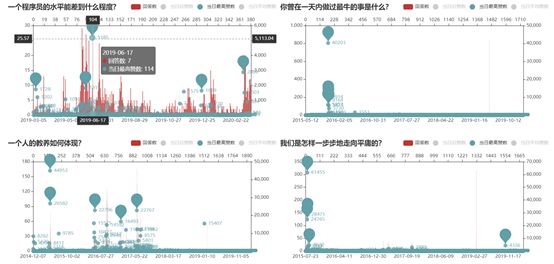

再看看前5个高赞回答的出现时间。对于昙花一现型的问题,高赞回答往往只出现在爆发的那几天里,一旦错过时机基本就很难“出人头地”。而对细水长流型,有机会火起来的窗口期就多上不少,但也同样和问题的热度有关系。此外,众所周知,鉴于知乎的排序算法,排名靠前-观看人数增加-赞数增加-排名更靠前这一循环显然成立,因此越早发表高质量的回答抢占先机自然越有利。
2.2 赞数与粉丝数的关系——“是不是高赞答主一般都自带粉丝?小透明还有戏吗?”
(1)数据预处理
首先读取之前存储的json数据。
import json
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, Line, Page
from pyecharts.commons.utils import JsCode
from util import data_sort
def read_json():
voteup = []
comment = []
follower = []
content = []
# 整合读取json数据
for i in range(0, 400, 10):
with open(f'data/data{i}.json', 'r') as f:
data = json.load(f)
for q in data:
for answer in q['answers']:
voteup.append(answer['voteup_count'])
comment.append(answer['comment_count'])
follower.append(answer['author_follower_count'])
content.append(answer['content'])
return voteup, comment, follower, content
再用pandas的cut函数以及dataframe的groupby函数进行分组统计。
*这里记录一个很小的知识点:
pd.value_counts(cut)根据count降序排列,
而df.groupby([‘分类’]).size()的结果根据类别排序,不需要额外重排。
def distribution(voteup, comment, follower):
# 按照赞数区间进行数据分类
cutpoint = [0, 100, 1000, 4000, 10000, 20000, 40000, 400000]
label = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
cut = pd.cut(voteup, cutpoint, right=False, labels=label)
data = {'分类': cut, '赞数': voteup, '评论数': comment, '粉丝数': follower}
df = pd.DataFrame(data)
# 分组统计
counts = df.groupby(['分类']).size() # 赞数区间的频数统计
c_mean = df['评论数'].groupby(df['分类']).mean()
f_mean = df['粉丝数'].groupby(df['分类']).mean()
# 提取千赞以上回答的数据
x = ['(A) <0.1k', '(B) 0.1k-1k', '(C) 1k-4k', '(D) 4k-10k', '(E) 10k-20k', '(F) 20k-40k', '(G) >40k'][2:]
y1 = list(map(int, c_mean))[2:]
y2 = list(map(int, f_mean))[2:]
df1 = df[df['分类'].isin(['C'])]['粉丝数']
df2 = df[df['分类'].isin(['D'])]['粉丝数']
df3 = df[df['分类'].isin(['E'])]['粉丝数']
df4 = df[df['分类'].isin(['F'])]['粉丝数']
df5 = df[df['分类'].isin(['G'])]['粉丝数']
bins = [0, 50, 100, 500, 1000, 5000, 10000, 50000, 100000, 500000, 1000000, 5000000]
label = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K']
# 在每个赞数区间内,进一步划分粉丝数区间
f_cut1 = pd.cut(df1, bins, right=False, labels=label)
c1 = pd.value_counts(f_cut1)
f_cut2 = pd.cut(df2, bins, right=False, labels=label)
c2 = pd.value_counts(f_cut2)
f_cut3 = pd.cut(df3, bins, right=False, labels=label)
c3 = pd.value_counts(f_cut3)
f_cut4 = pd.cut(df4, bins, right=False, labels=label)
c4 = pd.value_counts(f_cut4)
f_cut5 = pd.cut(df5, bins, right=False, labels=label)
c5 = pd.value_counts(f_cut5)
return counts, x, y1, y2, c1, c2, c3, c4, c5
数据分好组后便可以进行可视化了。
(2)所有3970个回答的赞数分布统计

*赞数分布的区间为人工划定。
知乎回答有默认排序和时间排序两种方法,而默认排序并不绝对以赞数为标准,因此爬取到的回答中有20%左右赞数<1k,后续分析时将排除在“高赞回答”的范围外。
def voteup_counts(counts):
# 赞数分布的区间与频数统计
x = ['(A) <0.1k', '(B) 0.1k-1k', '(C) 1k-4k', '(D) 4k-10k', '(E) 10k-20k', '(F) 20k-40k', '(G) >40k']
y = list(counts)
bar = (
Bar()
.add_xaxis(x)
.add_yaxis('该赞数区间内的回答数', y)
.extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts()))
.set_series_opts(label_opts=opts.LabelOpts(
is_show=True,
# formatter=JsCode("function(x){return Number(x.data/3970*100).toFixed(2) + '%';}")
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title='赞数分布统计'),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(), )
)
)
filename = '赞数分布统计.html'
bar.render(filename)
print('图表创建成功')
(3)不同赞数区间内回答的平均评论数和粉丝数统计
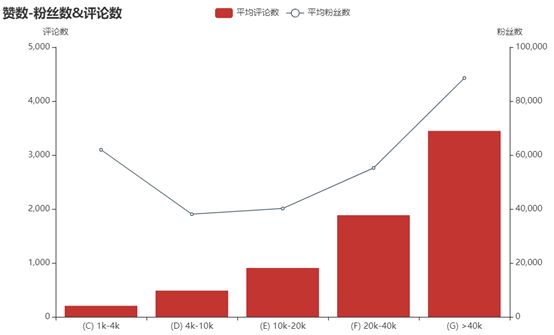
按照我们的一般认知,赞数-评论数-粉丝数这三个因素应当互为正相关。
图中赞数-评论数的关系显然符合这一认知,回答越火评论也越多;
但粉丝数的趋势却似乎不合常理,1k-4k赞的回答居然拥有比2w-4w赞的回答更高的平均粉丝数!出现这一情况的原因或许是样本数不足,缺乏普遍性,导致在第一个区间内出现多个拥有大量粉丝但回答遭受冷落的答主……于是我们针对每个区间来进一步观察粉丝数的分布情况。
def comment_follower_mean(x, y1, y2):
# 不同赞数区间内的平均评论数和粉丝数统计
bar = (
Bar(init_opts=opts.InitOpts(width="800px", height="500px"))
.add_xaxis(x)
.add_yaxis('平均评论数', y1)
.extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts(), name='粉丝数'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title='赞数-粉丝数&评论数'),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(), max_=5000, name='评论数')
)
)
line = (
Line()
.add_xaxis(x)
.add_yaxis("平均粉丝数", y2, yaxis_index=1, label_opts=opts.LabelOpts(is_show=False))
)
bar.overlap(line)
filename = '赞数-粉丝数&评论数.html'
bar.render(filename)
print('图表创建成功')
(3)不同赞数区间内的粉丝数分布统计
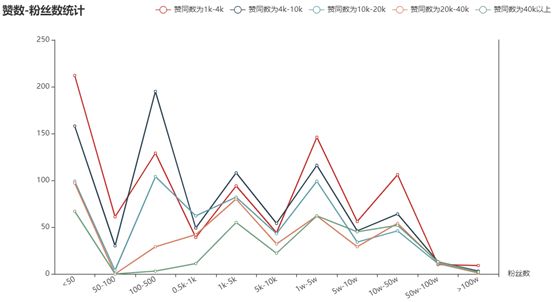

果不其然,赞数为1k-4k的回答中,出现了多位百万粉级别的大神,显著拉高了这一档次的平均值,也说明个位数的样本确实不太靠谱。此外,我只对原绝对数值进行了简单的可视化,没有归一化为百分比形式,所以也不方便对不同赞数区间进行横向比较。
从整体来看,粉丝数小于50的答主占了相当一部分,这难道表示小透明也有春天?!——遗憾的是,这可能仅仅是匿名/已注销/已停用的用户没法读取粉丝数只能设置为0的结果……撇开特殊情况不谈,粉丝数-赞同数的关系还是比较符合通常认知的,50-100粉的高赞回答随着赞数增加几乎绝迹。
不过这也不能成为“高赞答主自带粉丝团”的绝对佐证,毕竟这一因果关系完全可以颠倒:小透明写出了非常棒的回答自然会吸引到大量关注者,从而走上人生巅峰。所以也别气馁,认真创作干货,总有被人赏识的一天~
def multi_follower_counts(c1, c2, c3, c4, c5):
# 不同赞数区间内的粉丝数分布统计
_, y1 = data_sort(list(c1.index), list(c1))
_, y2 = data_sort(list(c2.index), list(c2))
_, y3 = data_sort(list(c3.index), list(c3))
_, y4 = data_sort(list(c4.index), list(c4))
_, y5 = data_sort(list(c5.index), list(c5))
x = ['<50', '50-100', '100-500', '0.5k-1k', '1k-5k', '5k-10k', '1w-5w', '5w-10w', '10w-50w', '50w-100w', '>100w']
line = (
Line()
.add_xaxis(x)
.add_yaxis('赞同数为1k-4k', y1)
.add_yaxis('赞同数为4k-10k', y2)
.add_yaxis('赞同数为10k-20k', y3)
.add_yaxis('赞同数为20k-40k', y4)
.add_yaxis('赞同数为40k以上', y5)
.extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts()))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False), linestyle_opts=opts.LineStyleOpts(width=2))
.set_global_opts(
title_opts=opts.TitleOpts(title='赞数-粉丝数统计'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30), name='粉丝数'),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts()),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
legend_opts=opts.LegendOpts(pos_left="right")
)
)
filename = '赞数-粉丝数统计-line.html'
line.render(filename)
print('图表创建成功')
bar = (
Bar()
.add_xaxis(x)
.add_yaxis('赞同数为1k-4k', y1)
.add_yaxis('赞同数为4k-10k', y2)
.add_yaxis('赞同数为10k-20k', y3)
.add_yaxis('赞同数为20k-40k', y4)
.add_yaxis('赞同数为40k以上', y5)
.extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts()))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False), linestyle_opts=opts.LineStyleOpts(width=2))
.set_global_opts(
title_opts=opts.TitleOpts(title='赞数-粉丝数统计'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30), name='粉丝数'),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts()),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
legend_opts=opts.LegendOpts(pos_left="right")
)
)
filename = '赞数-粉丝数统计-bar.html'
bar.render(filename)
print('图表创建成功')
page = Page(layout=Page.SimplePageLayout)
page.add(line, bar)
page.render("赞数-粉丝数统计.html")
print('图表创建成功')