论文《Attention Is All You Need》及Transformer模型
Transformer模型:
Transformer采用encoder-decoder结构,舍弃了RNN的循环式网络结构,完全基于注意力机制来对一段文本进行建模。
Transformer所使用的注意力机制的核心思想是去计算一句话中的每个词对于这句话中所有词的相互关系,然后认为这些词与词之间的相互关系在一定程度上反应了这句话中不同词之间的关联性以及重要程度。因此再利用这些相互关系来调整每个词的重要性(权重)就可以获得每个词新的表达。这个新的表征不但蕴含了该词本身,还蕴含了其他词与这个词的关系,因此和单纯的词向量相比是一个更加全局的表达。Transformer通过对输入的文本不断进行这样的注意力机制层和普通的非线性层交叠来得到最终的文本表达。
1. Introduction
本文是谷歌发表的文章,针对nlp里的机器翻译问题,提出了一种被称为”Transformer”的网络结构,基于注意力机制。文章提出,以往nlp里大量使用RNN结构和encoder-decoder结构,RNN及其衍生网络的缺点就是慢,问题在于前后隐藏状态的依赖性,无法实现并行,而文章提出的”Transformer”完全摒弃了递归结构,依赖注意力机制,挖掘输入和输出之间的关系,这样做最大的好处是能够并行计算了。
Background
在此之前,针对机器翻译这个领域,为了应对RNN无法并行问题,已经有过一些使用CNN的解决方案了,例如谷歌的ByteNet,Facebook的FairSeq等等。
自注意力机制(Self-attention)能够把输入序列上不同位置的信息联系起来,然后计算出整条序列的某种表达,目前自注意力机制主要应用于阅读理解、提取摘要、文本推论等领域。
2. 模型结构

大多数自然语言转换模型都包含一个encoder-decoder结构,模型的输入是一个离散符号序列(symbol)x=(x1,x2,⋯,xn),encoder负责将它映射成连续值序列z=(z1,z2,⋯,zn)。而给定z,decoder负责生成一个输出符号序列y=(y1,y2,⋯,ym)。模型是自回归的,即之前生成的输出会作为额外的输入,用于生成下一个输出。

要搭建Transformer,我们必须要了解5个过程:
- 词向量层
- 位置编码
- 创建Masks
- 多头注意层(The Multi-Head Attention layer)
- Feed Forward层
2.1 Encoder与Decoder堆叠
Encoder
Transformer模型的Encoder由6个基本层堆叠起来,每个基本层包含两个子层,第一个子层是一个注意力机制,第二个是一个全连接前向神经网络。对两个子层都引入了残差边以及layer normalization。
Decoder
Transformer模型的Decoder也由6个基本层堆叠起来,每个基本层除了Encoder里面的那两个以外,还增加了一层注意力机制,同样引入残差边以及layer normalization。
2.2 输入层
编码器和解码器的输入就是利用学习好的embeddings将tokens(一般应该是词或者字符)转化为d维向量。对解码器来说,利用线性变换以及softmax函数将解码的输出转化为一个预测下一个token的概率。
2.3 位置向量
由于本文的模型结构没有使用任何递归结构或卷积结构,为了让模型能利用输入序列的顺序信息,必须引入某种能表达输入序列每个部分的绝对或相对位置的信息才行,也就是需要将tokens的相对以及绝对位置信息注入到模型中去。文章采取的方法是在输入embeddings的基础上加了一个位置编码(positional encoding),在送入encoder和decoder之前,先对输入进行编码,编码后的向量维度是dmodel。具体来说,采用正弦和余弦函数进行编码。
然而,只要稍微思考一下就会发现,这样的模型并不能捕捉序列的顺序!换句话说,如果将K、V按行打乱顺序(相当于句子中的词序打乱),那么Attention的结果还是一样的。这就表明了,到目前为止,Attention模型顶多是一个非常精妙的“词袋模型”而已。
这问题就比较严重了,大家知道,对于时间序列来说,尤其是对于NLP中的任务来说,顺序是很重要的信息,它代表着局部甚至是全局的结构,学习不到顺序信息,那么效果将会大打折扣(比如机器翻译中,有可能只把每个词都翻译出来了,但是不能组织成合理的句子)。
于是Google再祭出了一招——Position Embedding,也就是“位置向量”,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。
Position Embedding并不算新鲜的玩意,在FaceBook的《Convolutional Sequence to Sequence Learning》也用到了这个东西。
1、以前在RNN、CNN模型中其实都出现过Position Embedding,但在那些模型中,Position Embedding是锦上添花的辅助手段,也就是“有它会更好、没它也就差一点点”的情况,因为RNN、CNN本身就能捕捉到位置信息。但是在这个纯Attention模型中,Position Embedding是位置信息的唯一来源,因此它是模型的核心成分之一,并非仅仅是简单的辅助手段。
2、在以往的Position Embedding中,基本都是根据任务训练出来的向量。而Google直接给出了一个构造Position Embedding的公式:

这里的意思是将id为p的位置映射为一个dpos维的位置向量,这个向量的第i个元素的数值就是PE。Google在论文中说到他们比较过直接训练出来的位置向量和上述公式计算出来的位置向量,效果是接近的。因此显然我们更乐意使用公式构造的Position Embedding了。
3、Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有sin(α+β)=sinαcosβ+cosαsinβ以及cos(α+β)=cosαcosβ−sinαsinβ,这表明位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
2.4. 注意力机制
注意力机制(Attention)简单来说就是给定一个查找(query)和一个键值表(key-value pairs),将query映射到正确的输入的过程。此处的query、key、value和最终的输出都是向量。输出往往是一个加权求和的形式,而权重则由query、key和value决定。
NLP领域中,Attention网络基本成为了标配,是Seq2Seq的创新。Attention网络是为了解决编码器-解码器结构存在的长输入序列问题。
Attention功能可以被描述为将查询和一组键值对映射到输出,其中查询,键,值和输出都是向量。输出可以通过对查询的值加权来计算。
Additive Attention
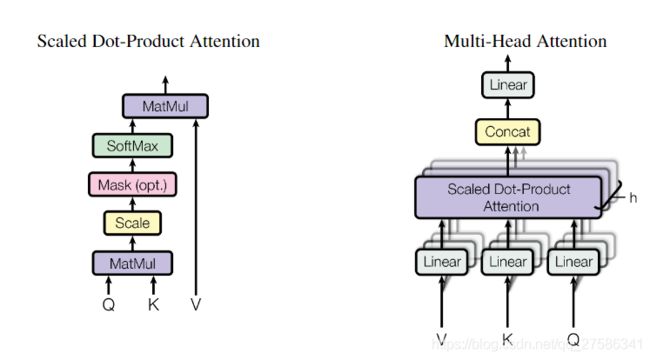
2.4.1 Scaled Dot-Product Attention
输入包含dk维的query和key,以及dv维的value。通过计算query和各个key的点积,除以dk−−√dk归一化,然后经过softmax激活变成权重,最后再乘value。点积注意力机制的优点是速度快、占用空间小。



例子:

embedding在进入到Attention之前,有3个分叉,那表示说从1个向量,变成了3个向量Q、K、V,它是通过定义一个WQ矩阵(这个矩阵随机初始化,通过前向反馈网络训练得到),将embedding和WQ矩阵做乘法,得到查询向量q,假设输入embedding是512维,在上图中我们用4个小方格表示,输出的查询向量是64维,上图中用3个小方格以示不同。然后类似地,定义WK和WV矩阵,将embedding和WK做矩阵乘法,得到键向量k;将embeding和WV做矩阵乘法,得到值向量v。对每一个embedding做同样的操作,那么每个输入就得到了3个向量,查询向量,键向量和值向量。需要注意的是,查询向量和键向量要有相同的维度,值向量的维度可以相同,也可以不同,但一般也是相同的。
至于将获得的Q、K、V矩阵具体操作,总的来说,就是以下这幅图:

获得的Z和目标值进行比较,获得的损失反向传播,优化的参数是,WQ,WK,WV
2.4.2 Multi-Head Attention
用h(本文取8)个不同的线性变换分别将dmodel维的key、value和query映射成dk维、dk维和dv维,然后再代入注意力机制,产生总共h×dv维输出,然后拼起来,再用一个线性变换得到最终的输出。
这个是Google提出的新概念,是Attention机制的完善。不过从形式上看,它其实就再简单不过了,就是把Q、K、V通过参数矩阵映射一下,然后再做Attention,把这个过程重复做h次,结果拼接起来就行了,可谓“大道至简”了。具体来说:

所谓“多头”(Multi-Head),就是只多做几次同样的事情(参数不共享),然后把结果拼接。
2.4.3 Self Attention
到目前为止,对Attention层的描述都是一般化的,我们可以落实一些应用。比如,如果做阅读理解的话,Q可以是篇章的向量序列,取K=V为问题的向量序列,那么输出就是所谓的Aligned Question Embedding。
而在Google的论文中,大部分的Attention都是Self Attention,即“自注意力”,或者叫内部注意力。
所谓Self Attention,其实就是Attention(X, X, X),X就是前面说的输入序列。也就是说,在序列内部做Attention,寻找序列内部的联系。Google论文的主要贡献之一是它表明了内部注意力在机器翻译(甚至是一般的Seq2Seq任务)的序列编码上是相当重要的,而之前关于Seq2Seq的研究基本都只是把注意力机制用在解码端。类似的事情是,目前SQUAD阅读理解的榜首模型R-Net也加入了自注意力机制,这也使得它的模型有所提升。
当然,更准确来说,Google所用的是Self Multi-Head Attention:
Y=MultiHead(X, X, X)
2.4.4 本文使用的注意力机制
本文使用的是Multi-Head Attention,具体体现在三个方面。
- 在“encoder-decoder attention”层中,query来自前一个decoder层,而key和value是encoder的输出。这允许decoder的每个位置都去关注输入序列的所有位置。
- encoder包含self-attention层,在self-attention层中所有的key、value和query都来自前一层的encoder。这样encoder的每个位置都能去关注前一层encoder输出的所有位置。
- decoder包含self-attention层
2.4.5 前向神经网络
这是一个 Position-wise 前向神经网络,encoder和decoder的每一层都包含一个前向神经网络,激活函数顺序是线性、RELU、线性。 每层由两个支层,attention层就是其中一个,而attention之后的另一个支层就是一个前馈的网络。公式描述如下:

3. 总结
模型的整体框架基本介绍完了,其最重要的创新应该就是Self-Attention和Multi-Head Attention的架构。在摒弃传统CNN和RNN的情况下,还能提高表现,降低训练时间。Transformer用于机器翻译任务,表现极好,可并行化,并且大大减少训练时间。并且也给我们开拓了一个思路,在处理问题时可以增加一种结构的选择。
为什么使用self-attention
从三个方面去对比self-attention和递归结构、卷积结构的优劣性,首先是每一层的计算复杂度,其次是能够被并行的计算量,最后是网络中长期依赖的路径长度。对比显示,self-attention表现最好。

训练
训练数据使用WMT English-German数据集,包含450w对语句。句子都被编码过了,使用了一个大小约37000个token的字典。样本被分为若干个batch,每个batch大概25000个token,每个batch中的句子长度保持基本一致。硬件上使用了8块GPU。Optimizer使用了Adam。过拟合方面使用了dropout和Label Smoothing。
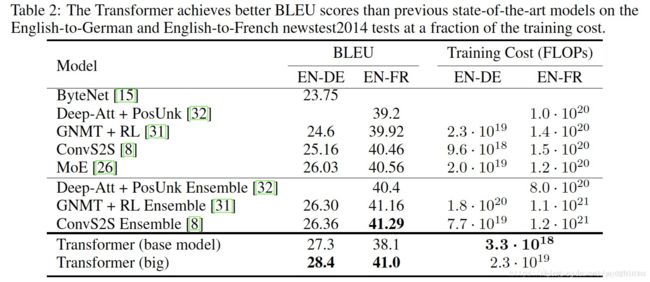
结果
不论是英语-德语还是英语-法语的翻译任务,对比之前的一些模型,本文提出的模型都达到更好的BELU值,同时Training Cost也最低。
本文开源代码
https://github.com/tensorflow/tensor2tensor
attention实现keras版: https://github.com/bojone/attention/blob/master/attention_keras.py
attention实现tensorflow版: https://github.com/bojone/attention/blob/master/attention_tf.py
参考资料
从Encoder-Decoder(Seq2Seq)理解Attention的本质:https://www.cnblogs.com/huangyc/p/10409626.html#_label3
《Attention is All You Need》浅读(简介+代码)https://kexue.fm/archives/4765
Attention Is All You Need https://arxiv.org/abs/1706.03762
一文读懂「Attention is All You Need」| 附代码实现 https://yq.aliyun.com/articles/342508
对Attention is all you need 的理解https://blog.csdn.net/mijiaoxiaosan/article/details/73251443