LDA(线性判别分析)的原理详解及Python代码示例
线性判别分析(Linear Discriminant Analysis, 以下简称LDA)是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”,即将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
符号解释:
|
|
有 个类 个类 |
 |
第 类的样本数 类的样本数 |
 |
所有类的样本总数 |
第类的第 个样本 个样本 |
|
| 第类的均值矩阵 |
|
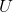 |
所有类的均值矩阵 |
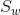 |
类间散度矩阵 |
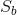 |
类内散度矩阵 |
 |
由d个最大的特征向量组成的投影矩阵 |
 |
降维后的新样本 |
算法步骤:
1、求出类间散度矩阵![]() ;
;

2、求出类内散度矩阵![]() ;
;
![]()

3、求出矩阵
![]() ;
;
4、求出![]() 的最大的d个特征值和对应的d个特征向量,由该d个特征向量组成投影矩阵;
的最大的d个特征值和对应的d个特征向量,由该d个特征向量组成投影矩阵;
5、对样本集的每一个样本![]() ,转化为新的样本
,转化为新的样本![]() ;
;
6、得到输出样本集;
结果:

Python代码示例:
#encoding:GBK
"""
Created on 2019/09/09 10:23:46
@author: Sirius_xuan
"""
import numpy as np
import matplotlib.pyplot as plt
# Sq1 合格样本
# Sq2 不合格样本
# Uq1 合格样本的均值
# Uq2 不合格样本的均值
# Uall 所有样本的均值
# Sb 类内散度矩阵
# Sw 类间散度矩阵
# L 特征值
# V 特征向量
# v 前k个最大的几个特征向量
fig,ax=plt.subplots(1,2,figsize=(10,6))
fig.suptitle("LDA",fontsize=20)
ax[0].set_title('Before Dimension Reduction')
ax[1].set_title('After Dimension Reduction')
#合格样本
Sq1 = [
[2.9500, 6.6300],
[2.5300, 7.7900],
[3.5700, 5.6500],
[3.1600, 5.4700]
#不合格样本
Sq2 = [
[2.5800, 4.4600],
[2.1600, 6.2200],
[3.2700, 3.5200]
]
Sq1 = np.array(Sq1)
Sq2 = np.array(Sq2)
ax[0].scatter(Sq1[:,0], Sq1[:,1], label='qualified')
ax[0].scatter(Sq2[:,0], Sq2[:,1], label='unqualified')
#n为该i类的样本数;
#(1/n) ∑ (Xk)
# k∈CLASSi
Uq1 = np.mean(Sq1,axis=0)
print ("合格样本均值:\n"+str(Uq1)+"\n")
ax[0].scatter(Uq1[0], Uq1[1], marker="v", label='U_qualified')
Uq2 = np.mean(Sq2,axis=0)
print ("不合格样本均值:\n"+str(Uq2)+"\n")
ax[0].scatter(Uq2[0], Uq2[1], marker="^", label='U_unqualified')
#m为所有样本的数目;
#(1/m) ∑ (Xk)
# k∈CLASSi
Uall = np.mean(np.vstack((Sq1,Sq2)),axis=0)
print ("总体均值:\n"+str(Uall)+"\n")
ax[0].scatter(Uall[0], Uall[1] , marker="s", label='U_all')
#有c个类,Ui为对应类样本的均值,U为所有样本的总均值;
# c
# ∑ (1/m)(Xi-Ui)(Xi-Ui)^T
# i=1
Sb1 = (4.0/7.0)*np.dot((np.mat(Uq1-Uall).T),np.array(Uq1-Uall).reshape(1,2))
Sb2 = (3.0/7.0)*np.dot((np.mat(Uq2-Uall).T),np.array(Uq2-Uall).reshape(1,2))
Sb = Sb1 + Sb2
print ("类间离散矩阵:\n"+str(Sb)+"\n")
#Xk为i类的某个样本;
# c
# ∑ (1/m) ∑ (Xk-Ui)(Xk -Ui)^T
#i=1 Xk∈CLASSi
Sw1 = np.zeros((2,2))
for i in range(0,len(Sq1)):
Sw1 = np.dot(np.mat(Sq1[i]-Uq1).T, np.array(Sq1[i]-Uq1).reshape(1,2)) + Sw1
Sw2 = np.zeros((2,2))
for i in range(0,len(Sq2)):
Sw2 = np.dot(np.mat(Sq2[i]-Uq2).T, np.array(Sq2[i]-Uq2).reshape(1,2)) + Sw2
Sw = (Sw1+Sw2)/7.0
print ("类内离散矩阵:\n"+str(Sw)+"\n")
#Sw^(-1)Sb
L,V = np.linalg.eig(np.dot(np.mat(Sw).I,Sb))
print ("特征值:\n"+str(L)+"\n")
print ("特征向量:\n"+str(V)+"\n")
k=1
v=V[:,k]
print ("最大特征值对应的特征向量:\n"+str(v)+"\n")
New_Sq1 = np.array(np.dot(Sq1,v))
print ("合格样本投影后的样本值:\n"+str(New_Sq1)+"\n")
ax[1].scatter(New_Sq1,np.ones(len(New_Sq1)),marker="p", label='qualified')
New_Sq2 = np.array(np.dot(Sq2,v))
print ("不合格样本投影后的样本值:\n"+str(New_Sq2)+"\n")
ax[1].scatter(New_Sq2,np.ones(len(New_Sq2)),marker="p", label='unqualified')
'''
#数据标注;
ax[0].annotate("qualified",xy = (Sq1[0][0],Sq1[0][1]), xytext = (Sq1[0][0]+0.2,Sq1[0][1]+0.2),\
arrowprops = dict(color='r',arrowstyle = "->"))
ax[0].annotate("qualified",xy = (Sq2[0][0],Sq2[0][1]), xytext = (Sq2[0][0]+0.2,Sq2[0][1]-0.2),\
arrowprops = dict(color='r',arrowstyle = "->"))
ax[0].annotate("U_qualified", xy = (Uq1[0], Uq1[1]), xytext = (Uq1[0]+0.2, Uq1[1]+0.2),\
arrowprops = dict(color='r',arrowstyle = "->"))
ax[0].annotate("U_unqualified", xy = (Uq2[0], Uq2[1]), xytext = (Uq2[0]+0.2, Uq2[1]-0.2),\
arrowprops = dict(color='r',arrowstyle = "->"))
ax[0].annotate("U_all", xy = (Uall[0], Uall[1]), xytext = (Uall[0]+0.2, Uall[1]),\
arrowprops = dict(color='r',arrowstyle = "->"))
ax[1].annotate("qualified", xy = (New_Sq1[0], 1), xytext = (New_Sq1[0], 1+0.002),\
arrowprops = dict(color='r',arrowstyle = "->"))
ax[1].annotate("unqualified", xy = (New_Sq2[0], 1), xytext = (New_Sq2[0], 1+0.002),\
arrowprops = dict(color='r',arrowstyle = "->"))
'''
ax[0].legend()
ax[1].legend()
plt.show()