【深度学习:迁移学习】图像识别预训练模型的迁移学习
【深度学习:迁移学习】图像识别预训练模型的迁移学习
-
- 什么是迁移学习?
- 为什么不从头开始训练模型?
- 迁移学习的优点是:
- 如何使用预训练模型进行迁移学习:
- 迁移学习的过程:
- 实施迁移学习来构建人脸识别模型:
- 模型的构建分为 3 个步骤:
-
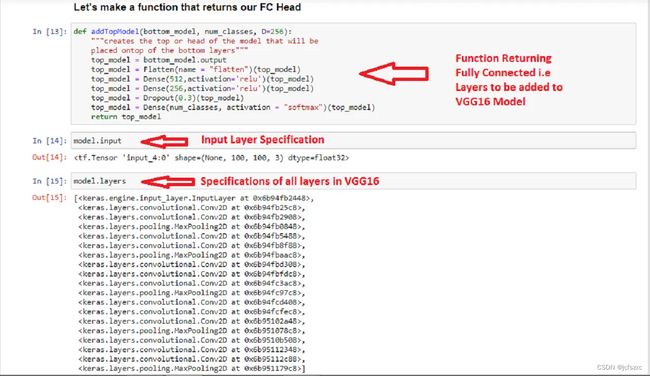
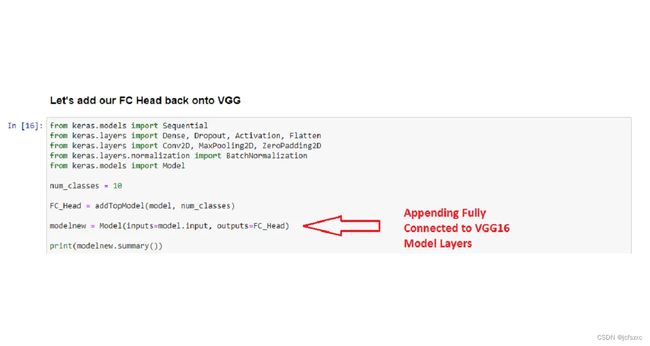
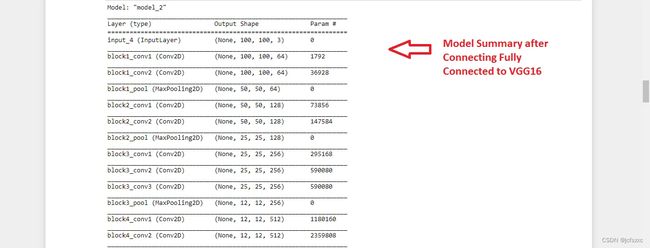
- 1. 导入预训练模型并添加密集层。
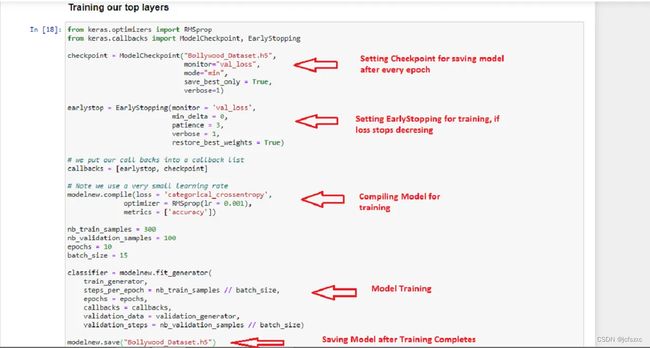
- 2. 将训练数据加载到图像数据生成器中。
- 3.通过预测验证数据标签加载训练模型和模型评估
- 结论 :
本文的目的是使用迁移学习快速、轻松地解决图像识别问题。为了演示,我们将使用 Keras 及其预训练模型创建一个深度学习代码。
在直接进入实践之前,让我们首先了解迁移学习到底是什么。
如今,深度学习在人工智能应用中发挥着重要作用,其中大部分是在计算机视觉或自然语言处理或语音识别领域。
但深度学习主要在计算机视觉领域,特别是在图像分类和识别领域取得了巨大的成就。图像分类的任务是将特定图像分类为一组可能的类别,图像识别是指软件识别图像中的对象、地点、人物、文字和动作的能力。图像分类的例子之一是汽车和自行车的识别。
由于在图像识别和分类方面已经做了很多工作,我们可以使用机器学习中的一种技术来解决图像分类问题,它可以快速、简单地产生很好的结果,这种技术就是迁移学习。
什么是迁移学习?
迁移学习通常是指将针对一个问题训练的模型以某种方式用于第二个相关问题的过程。
在深度学习中,迁移学习是一种技术,通过这种技术,神经网络模型首先在与正在解决的问题类似的问题上得到训练。然后将训练过的模型中的一个或多个层用于针对相关问题训练的新模型中。
迁移学习是计算机视觉领域的一种流行方法,因为它能让我们以省时省力的方式建立精确的模型。在迁移学习中,学习过程不是从零开始,而是从解决不同问题时学到的模式开始。这样就能充分利用以前的学习成果,避免从头开始。
迁移学习的好处是减少神经网络模型的训练时间,并能降低泛化误差。
重复使用的层中的权重可用作训练过程的起点,并根据新问题进行调整。这种用法将迁移学习视为一种权重初始化方案。当第一个相关问题的标注数据比感兴趣问题的标注数据多得多,而且问题结构的相似性在两种情况下都可能有用时,这种方法可能会很有用。
例如,在学习识别汽车时获得的知识可以应用于尝试识别卡车。

为什么不从头开始训练模型?
当经过足够的数据训练时,卷积神经网络可以学习极其复杂的映射函数。卷积神经网络因在具有大量特征的数据集中学习模式而闻名。
在基础层面上,CNN(卷积神经网络)的权重由过滤器组成。将过滤器视为由某些数字组成的 (n*n) 矩阵。现在这个过滤器通过提供的图像进行卷积(滑动和乘法)。假设输入图像的大小为 (10,10),滤波器的大小为 (3,3),首先将滤波器与输入图像左上角的 9 个像素相乘,此乘法产生另一个 (3, 3)矩阵。该矩阵的 9 个像素的值相加,该值成为 CNN 的 Layer_2 左上角的单个像素值。

基本上,CNN 的训练涉及到在每个滤波器上找到正确的值,以便输入图像在通过多个层时激活最后一层的某些神经元,从而预测输入图像的正确类别。
尽管对于小型项目来说,从头开始训练 CNN 是可能的,但大多数应用程序都需要训练非常大的 CNN,正如您所猜测的,这需要极其大量的处理数据和计算能力。如今,这两者都不那么容易找到了。因此,为了解决这个问题,另一种选择是迁移学习。
在迁移学习中,我们采用已训练模型的预训练权重(该模型已在数个高功率 GPU 上对属于 1000 个类别的数百万张图像进行了几天的训练),并使用这些已学习的特征来预测新的特征类。
迁移学习的优点是:
1:不需要大型数据集进行训练。
2:与从头开始训练 CNN 相比,所需的计算能力更少,因为我们使用预先训练的权重,只需学习最后几层的权重。
如何使用预训练模型进行迁移学习:
为了使用预训练模型,我们首先需要删除预训练模型的分类器,即全连接,然后我们必须添加自己的分类器,即符合我们目的的全连接,然后我们需要微调我们的模型根据我们的目标是什么以及我们拥有什么样的数据集,根据以下策略之一:
-
训练整个模型:在这种情况下,您可以使用预训练模型的架构并根据您的数据集对其进行训练。您正在从头开始学习模型,因此您将需要一个大型数据集,同时您还需要大量的计算能力。
-
训练一些层并冻结其他层:如您所知,较低层指一般特征(与问题无关),而较高层指特定特征(与问题相关)。通常,如果您有一个小数据集和大量参数,您将冻结更多层以避免过度拟合。相比之下,如果数据集很大并且参数数量很少,您可以通过为新任务训练更多层来改进模型,因为过度拟合不是问题。
-
冻结卷积基:主要思想是保持卷积基的原始形式,然后使用其输出来馈送分类器,即全连接。您使用预训练模型作为固定特征提取机制,如果您计算能力不足、数据集很小和/或预训练模型解决的问题与您所遇到的问题非常相似,那么这会很有用。想要解决。

迁移学习的过程:
这个过程可以通过3个要点来理解:
- 选择预先训练的模型:可能有十几个或更多性能最佳的图像识别模型可以下载并用作图像识别和相关计算机视觉任务的基础。
也许三种更流行的模型如下:
- VGG(例如 VGG16 或 VGG19)。
- GoogLeNet(例如 InceptionV3)。
- 残差网络(例如 ResNet50)。
这些模型都广泛用于迁移学习,不仅因为它们的性能,还因为它们是引入特定架构创新的示例,即一致和重复结构(VGG)、初始模块(GoogLeNet)和残差模块(ResNet)。
Keras 提供了对许多为图像识别任务开发的性能最佳的预训练模型的访问。
它们可以通过应用程序 API 获得,并且包括加载带有或不带有预先训练权重的模型的函数,并以给定模型可能期望的方式准备数据(例如,缩放大小和像素值)。
首次加载预训练模型时,Keras 将下载所需的模型权重,考虑到您的互联网连接速度,这可能需要一些时间。权重存储在主目录下的 .keras/models/ 目录中,下次使用时将从该位置加载。
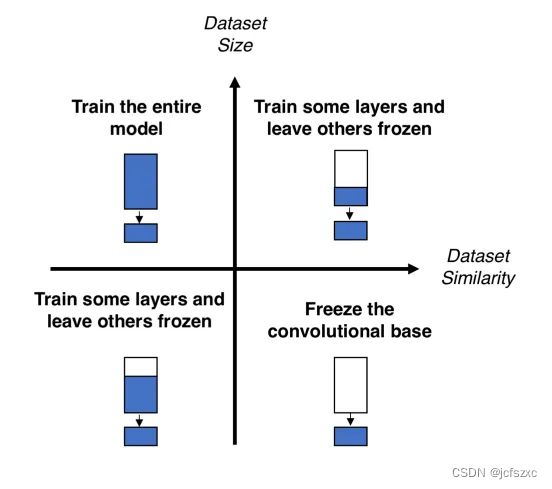
- 根据下图所示的类别识别问题:
下图显示了大小相似度矩阵,我们将根据该矩阵来决定我们的策略。

- 微调您的模型:微调只是进行一些微调以进一步提高性能。例如,在迁移学习期间,您可以解冻预训练的模型,让它更好地适应手头的任务。
实施迁移学习来构建人脸识别模型:
Pre-requisites:
- Keras
- Tensorflow
- Pillow
- numpy
- pandas
- jupyter notebook
预训练模型:我们在这里使用的模型是 VGG16,它已经在 Keras 框架的应用程序 API 中可用。
数据集:对于本次实践,我们将使用仅由我创建的数据集。但是您可以创建自己的图像或家人或朋友的图像的数据集来训练模型。
我们将使用的数据集由 10 类不同的图像组成,每类图像对应不同的印度名人。

以下是数据集中的示例数据,显示了阿米尔·汗的图像。

在开始之前,首先下载代码和数据集,以便更好地实际理解。点击这里下载。
模型的构建分为 3 个步骤:
请在安装了所有依赖项的环境中启动您的 Jupyter Notebook (因为我也在使用 Jupyter Notebook ),否则您可能会遇到一些问题。
1. 导入预训练模型并添加密集层。

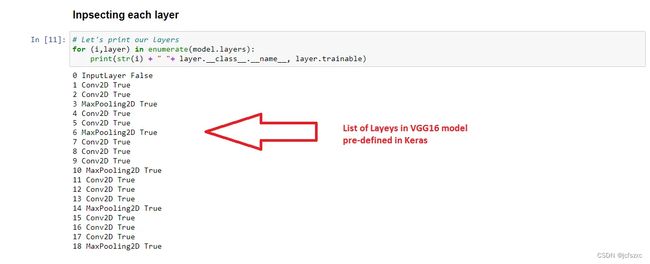
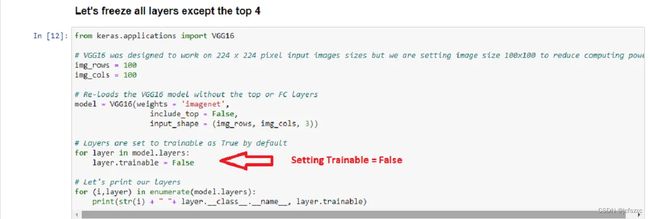


2. 将训练数据加载到图像数据生成器中。


3.通过预测验证数据标签加载训练模型和模型评估

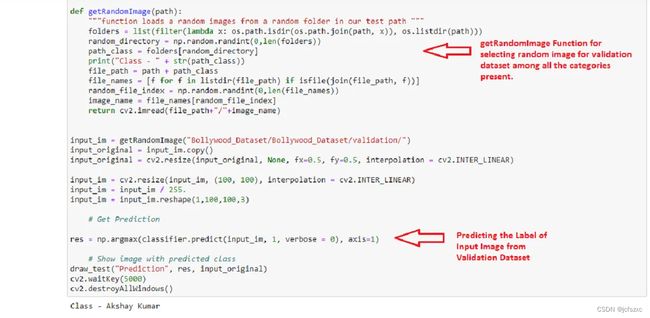
当您运行图像中标记为 [96] 的最后一个块时,您将看到一个图像出现,其中显示要预测标签的图像,并且在代码块的底部,您将看到原始标签的图像。图像是通过“getRandomImage”函数随机选择的。因此,您可以一次又一次地运行 Block No [96] 来检查不同图像的预测。

这次为图像预测的标签与图像的原始标签相同。这意味着我们的面部识别模型有效。
但有时我们的模型可能会做出错误的预测。
在上面的评估中,为图像预测的标签与原始标签不同,这意味着我们的模型不是 100% 准确,这在机器学习问题中是正常的。
为了获得更好的准确性,唯一的方法是一次又一次地微调我们的模型,直到其准确性提高而不会过度拟合。
结论 :
这样,我们就完成了在 Keras 中使用 VGG16 预训练模型进行迁移学习的实际演示。我希望您有动力开始开发计算机视觉深度学习项目,并尝试更多的迁移学习模型。这是一个伟大的研究领域,每天都会有新的令人兴奋的发现出现。
我很高兴为您提供帮助,所以如果您有任何问题或改进建议,请告诉我!