代码实践|全连接神经网络与文本分类

前情回顾

戳上方蓝字【阿力阿哩哩的炼丹日常】关注我~
今天继续给大家介绍第四章的内容
前面我们介绍了:
深度学习开端-全连接神经网络
一文掌握CNN卷积神经网络
超参数(Hyperparameters)| 上
超参数(Hyperparameters)| 下
寄己训练寄己|自编码器
通熟易懂RNN|RNN与RNN的变种结构 | 上
通俗易懂LSTM|RNN的变种结构 | LSTM长短期记忆网络
通俗易懂GRU|门控循环单元(gated recurrent unit, GRU)
代码实践 | 全连接神经网络回归---房价预测
4.7
代码实践
4.7.2 全连接神经网络与文本分类
笔者将在这节给大家介绍如何用全连接神经网络对招聘数据进行分类,从而训练出一个可以分类招聘信息的神经网络模型。
1. 文本表示
计算机是无法直接处理文本信息的,所以,在我们构建神经网络之前,要对文本进行一定的处理。
相信大家对独热编码(one-hot encode)应该不陌生了,虽说它能把所有文本用数字表示出来,但是表示文本的矩阵会非常的稀疏,极大得浪费了空间,而且这样一个矩阵放入神经网络训练也会耗费相当多的时间。
为此,Bengio等人[2]提出了词向量模型(Word2Vec)。词向量模型是一种将词的语义映射到向量空间的技术,说白了就是用向量来表示词,但是会比用独热编码用的空间小,而且词与词之间可以通过计算余弦相似度来看两个词的语义是否相近,显然King和Man两个单词语义更加接近,而且通过实验我们知道King-Man+Woman=Queen,也 5验证了词向量模型的有效性。Word2Vec的示意图如图 4.54所示。
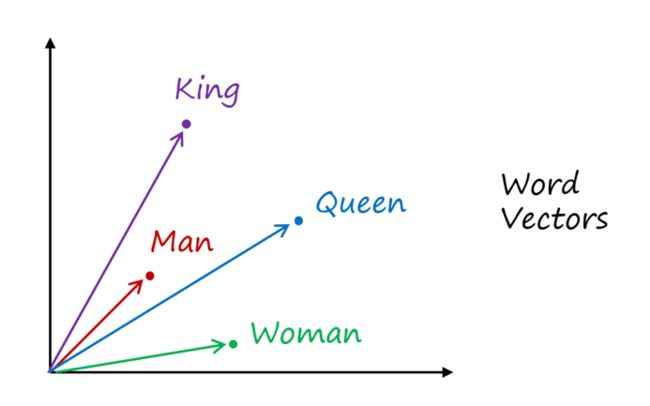
图 4.54 词向量模型Word2Vec
目前Word2Vec技术有好几种:CBOW、Skip-gram和GloVe以及2018年大火的BERT(在第八章提及),原理都差不多,目前我们的实验用的词向量模型是Skip-gram,因此这里笔者只介绍 Skip-gram模型。
Skip-gram是输入一个词,预测该词上下文的模型。如图 4.55所示。
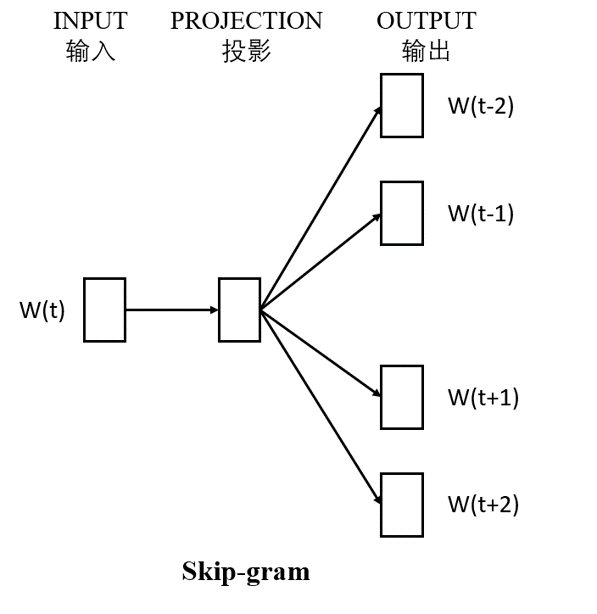
图 4.55 Skip-gram
Skip-gram的具体训练过程如下,蓝色代表输入的词,图 4.56的框框代表滑动窗口,用来截取蓝色词的上下文,蓝色词的上下文作为输出,然后形成训练标本(Training Samples),这样我们就得到了{输入和输出},将他们放入{输入层-隐藏层-输出层}的神经网络训练,我们就能得到Skip-gram模型。因为神经网络不能直接处理文本,因此所有的词都用one-hot encode表示。
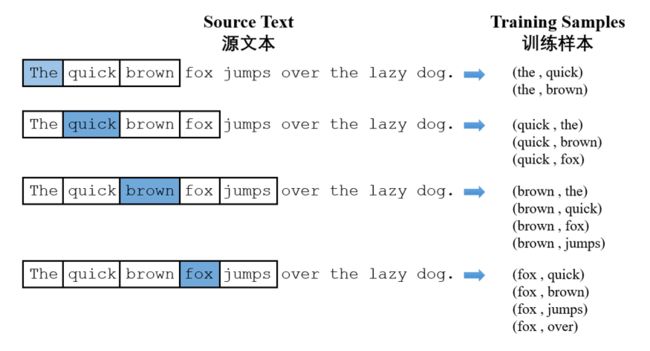
图 4.56 Skip-gram训练数据生成过程
Skip-gram的神经网络结构如图 4.57所示,隐藏层有300个神经元,输出层用softmax激励函数,通过我们提取的词与其相应的上下文去训练,得到相应的模型。通过Softmax激励函数,输出层每个神经元输出的是概率,加起来等于1。

图 4.57 Skip-gram网络结构
但输出层并不是我们关心的,我们去掉模型的输出层,才是我们想要的词向量模型,我们通过隐藏层的权重来表示我们的词。
如图 4.58所示,现在假设我们有10000个词,每个词用one-hot encode编码,每个词大小就是1*10000,现在我们想用300个特征去表示一个词,那么隐藏层的输入是10000,输出是300(即300个神经元),因此它的权值矩阵大小为10000 * 300。那么我们的词向量模型本质上就变成了矩阵相乘。
好了,讲到这,大家已经把词向量的原理了解清楚了,而且值得高兴的是,Keras自带了词向量层embedding layer,所以我们只要将文本处理好,就可以灌入这个层中即可,后面的实验笔者会给大家细讲如何对文本进行预处理,生成符合embedding layer输入格式的词。

图 4.58 [1*10000] * [10000 * 300] = [1 * 300] 矩阵相乘
2. 中文分词之jieba分词
中文文本处理会比处理英文多一步,中文词与词之间并不是用“空格”分开的,计算机不能处理这么高度抽象的文字,所以我们得通过一个Python库比如jieba来将中文文本进行分词,然后用“空格”将词分开,形成类似英文那样的文本,方便计算机处理。jieba分词示例图如图 4.59所示。

图 4.59 jieba分词示例图
1. # 打开操作系统的命令行,输入安装指令
2. pip install jieba
3. 实验流程
(1) 加载招聘数据集
(2) 中文分词
(3) 提取文本关键词
(4) 建立token字典
(5) 使用token字典将“文字”转化为“数字列表”
(6) 截长补短让所有“数字列表”长度都是50 :保证每个文本都是同样的长度,避免不必要的错误。
(7) Embedding层将“数字列表”转化为"向量列表"
(8) 将向量列表送入深度学习模型进行训练
(9) 保存模型与模型可视化
(10) 模型的预测功能
(11) 训练过程可视化
4. 代码
1. # chapter4/4_7_2_MLP_Text.ipynb
2. import pandas as pd
3. import jieba
4. import jieba.analyse as analyse
5. from keras.preprocessing.text import Tokenizer
6. from keras.preprocessing import sequence
7. from keras.models import Sequential
8. from keras.layers import Dense, Dropout, Activation, Flatten, MaxPool1D, Conv1D
9. from keras.layers.embeddings import Embedding
10. from keras.utils import multi_gpu_model
11. from keras.models import load_model
12. from keras import regularizers # 正则化
13. import matplotlib.pyplot as plt
14. import numpy as np
15. from keras.utils import plot_model
16. from sklearn.model_selection import train_test_split
17. from keras.utils.np_utils import to_categorical
18. from sklearn.preprocessing import LabelEncoder
19. from keras.layers import BatchNormalization
1) 加载数据
1. job_detail_pd = pd.read_csv('job_detail_dataset.csv', encoding='UTF-8')
2. print(job_detail_pd.head(5))
3. label = list(job_detail_pd['PositionType'].unique()) # 标签
4. print(label)

1. # 上标签
2. def label_dataset(row):
3. num_label = label.index(row) # 返回label列表对应值的索引
4. return num_label
5.
6. job_detail_pd['label'] = job_detail_pd['PositionType'].apply(label_dataset)
7. job_detail_pd = job_detail_pd.dropna() # 删除空行
8. job_detail_pd.head(5)

1. # 中文分词
2. def chinese_word_cut(row):
3. return " ".join(jieba.cut(row))
4.
5. job_detail_pd['Job_Description_jieba_cut'] = job_detail_pd.Job_Description.apply(chinese_word_cut)
6. job_detail_pd.head(5)

1. # 提取关键词
2. def key_word_extract(texts):
3. return " ".join(analyse.extract_tags(texts, topK=50, withWeight=False, allowPOS=()))
4. job_detail_pd['Job_Description_key_word'] = job_detail_pd.Job_Description.apply(key_word_extract)
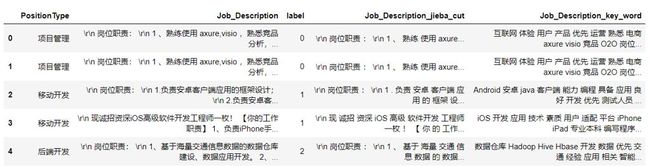
1. # 建立2000个词的字典
2. token = Tokenizer(num_words = 2000)
3. token.fit_on_texts(job_detail_pd['Job_Description_key_word']) #按单词出现次数排序,排序前2000的单词会列入词典中
4.
5. # 使用token字典将“文字”转化为“数字列表”
6. Job_Description_Seq = token.texts_to_sequences(job_detail_pd['Job_Description_key_word'])
7.
8. # 截长补短让所有“数字列表”长度都是50
9. Job_Description_Seq_Padding = sequence.pad_sequences(Job_Description_Seq, maxlen=50)
10. x_train = Job_Description_Seq_Padding
11. y_train = job_detail_pd['label'].tolist()
2) 开始训练
1. batch_size = 256
2. epochs = 5
3. model = Sequential()
4. model.add(Embedding(output_dim = 32, # 词向量的维度
5. input_dim = 2000, # Size of the vocabulary 字典大小
6. input_length = 50 # 每个数字列表的长度
7. )
8. )
9.
10. model.add(Dropout(0.2))
11. model.add(Flatten()) # 平展
12. model.add(Dense(units = 256,
13. activation = "relu"))
14. model.add(Dropout(0.25))
15. model.add(Dense(units = 10,
16. activation = "softmax"))
17.
18. print(model.summary()) # 打印模型
19. # CPU版本
20. model.compile(loss = "sparse_categorical_crossentropy", # 多分类
21. optimizer = "adam",
22. metrics = ["accuracy"]
23. )
24.
25. history = model.fit(
26. x_train,
27. y_train,
28. batch_size = batch_size,
29. epochs = epochs,
30. verbose = 2,
31. validation_split = 0.2 # 训练集的20%用作验证集
32. )

3) 保存模型
1. from keras.utils import plot_model
2. # 保存模型
3. model.save('model_MLP_text.h5') # 生成模型文件 'my_model.h5'
4. # 模型可视化
5. plot_model(model, to_file='model_MLP_text.png', show_shapes=True)
4) 模型的预测功能
1. from keras.models import load_model
2. # 加载模型
3. # model = load_model('model_MLP_text.h5')
4. print(x_train[0])
5. y_new = model.predict(x_train[0].reshape(1, 50))
6. print(list(y_new[0]).index(max(y_new[0])))
7. print(y_train[0])
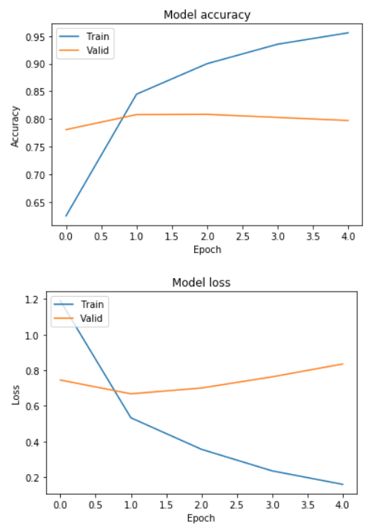
5) 训练过程可视化
1. import matplotlib.pyplot as plt
2. # 绘制训练 & 验证的准确率值
3. plt.plot(history.history['acc'])
4. plt.plot(history.history['val_acc'])
5. plt.title('Model accuracy')
6. plt.ylabel('Accuracy')
7. plt.xlabel('Epoch')
8. plt.legend(['Train', 'Valid'], loc='upper left')
9. plt.savefig('Valid_acc.png')
10. plt.show()
11.
12. # 绘制训练 & 验证的损失值
13. plt.plot(history.history['loss'])
14. plt.plot(history.history['val_loss'])
15. plt.title('Model loss')
16. plt.ylabel('Loss')
17. plt.xlabel('Epoch')
18. plt.legend(['Train', 'Valid'], loc='upper left')
19. plt.savefig('Valid_loss.png')
20. plt.show()
5. 结果分析
在迭代了1个epochs之后,验证集的损失loss和acc,趋于平稳,这时,我们得到的模型已经是最优的了。所以讲epoch设置为1即可。
参考文献
[2] Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. Journal of machine learning research, 2003, 3(Feb): 1137-1155.

下一期,我们将继续介绍
深度学习代码实践敬请期待~


关注我的微信公众号~不定期更新相关专业知识~


内容 |阿力阿哩哩
编辑 | 阿璃

点个“在看”,作者高产似那啥~
